YouTube Automation Engine
Inspiration
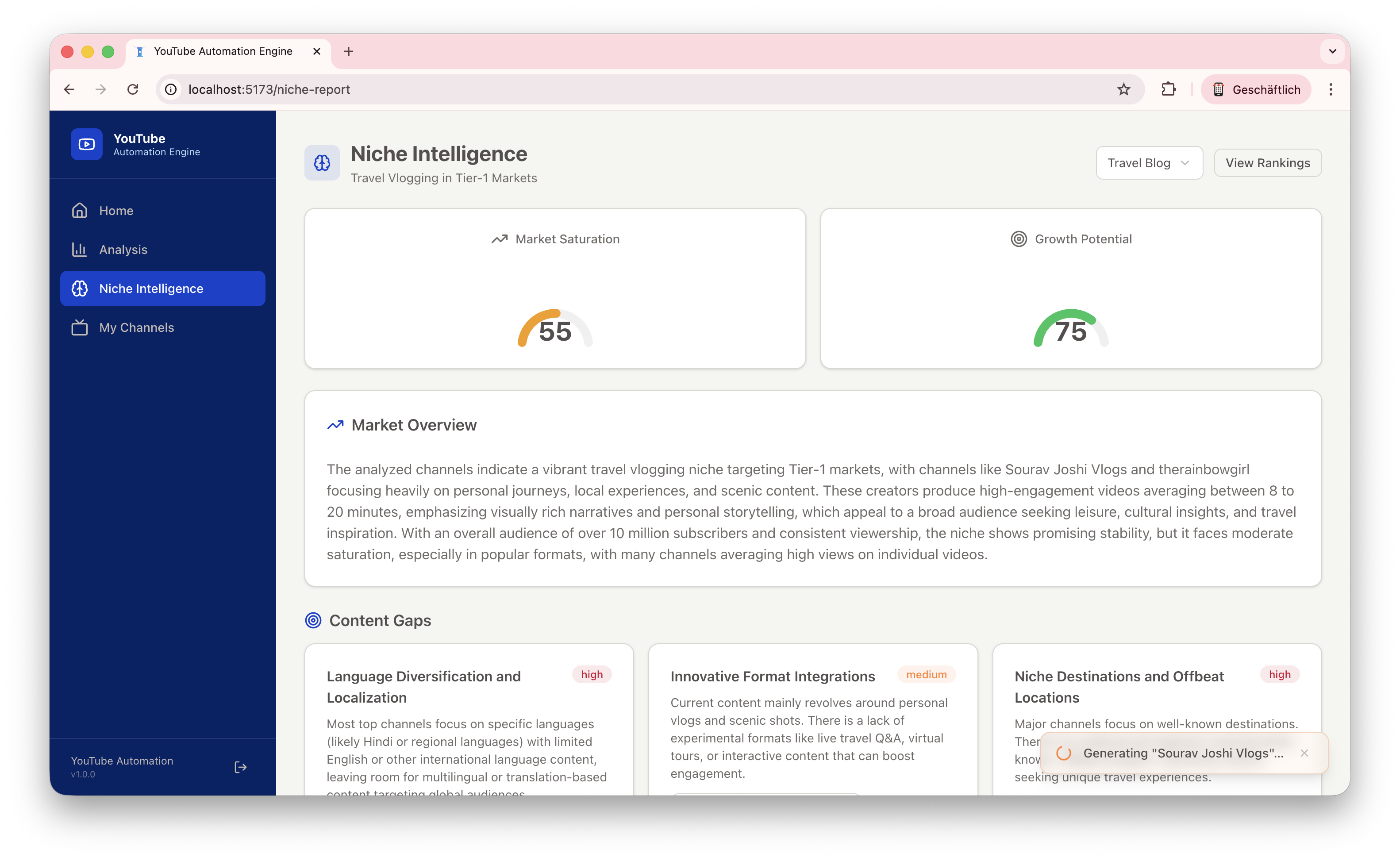
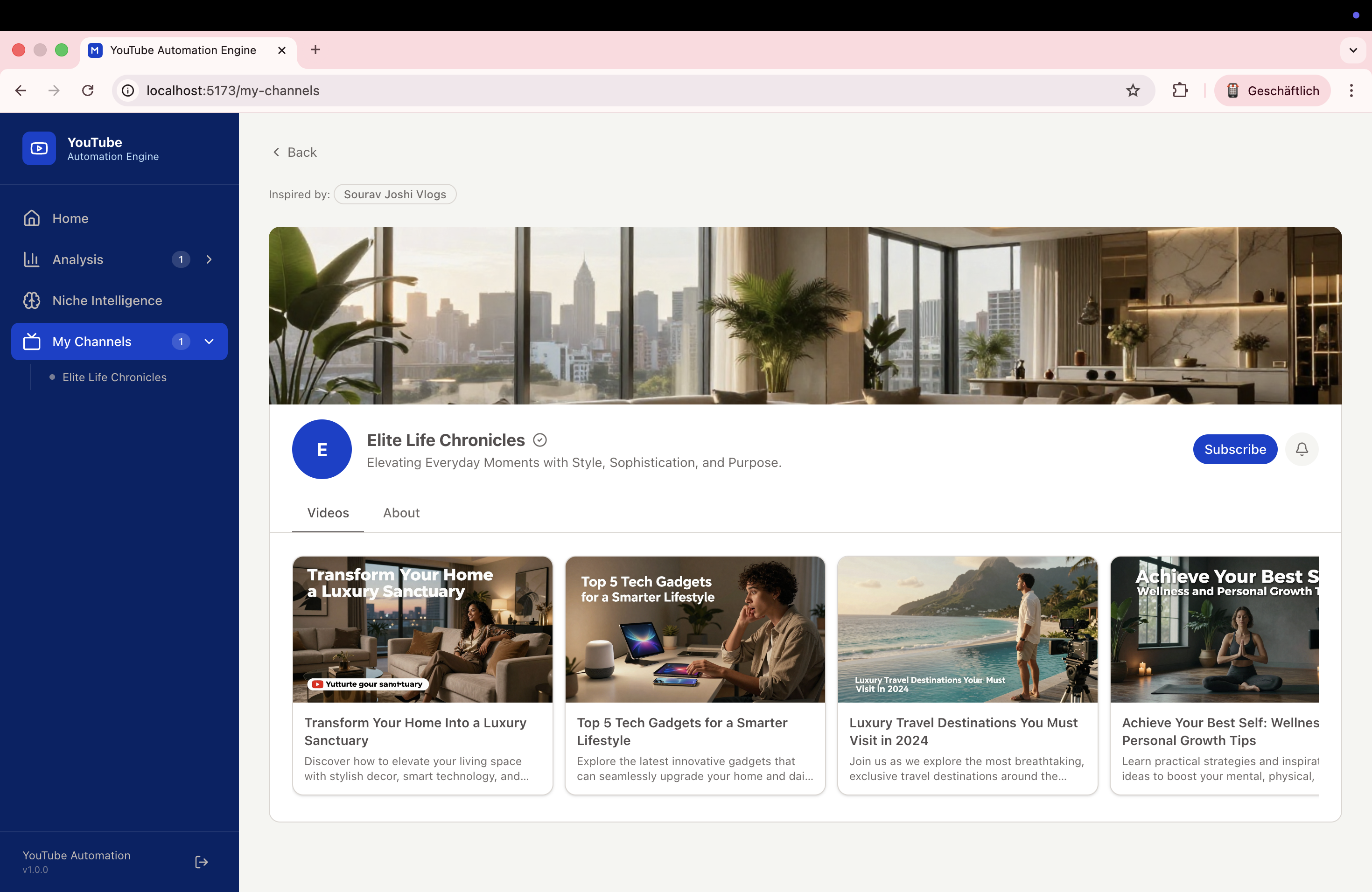
Starting a YouTube channel today means competing against millions of creators, but most aspiring creators have no systematic way to identify what actually works. Big media companies have research teams. While independent creators often operate on mere instinct, our system replaces 'gut feeling' with data-driven precision. The digital economy is shifting from manual creativity to algorithmic excellence. We asked: What if AI could analyze the YouTube landscape, identify proven winning formulas, and generate complete competitor channel concepts, ready to launch? YTB bridges the gap between data-driven marketing and the solo creator economy.
How we build it
Architecture:
- Backend: Node.js + Express + TypeScript (ESM), REST API on port 8000
- Frontend: React 19 + Vite + Tailwind CSS v4, AG Grid, Recharts
- Database: SQLite via Knex + @libsql/knex-libsql (5 normalized tables)
- AI: OpenAI GPT-4.1 with Zod-validated structured output; Ollama as local fallback
- Assets: n8n webhooks for image/video generation with retry logic and local caching
- Data: YouTube Data API v3 for discovery + transcript service for LLM context
Key Technical Decisions:
- Structured output with Zod schemas ensures deterministic, typed JSON from the LLM
- Background generation queue (React Context + localStorage) for non-blocking batch generation
- Dual caching layers: backend in-memory TTL cache + frontend request deduplication
Challenges we faced
A major technical hurdle arose during our n8n integration, where we discovered that secure file retrieval required a specific ?filename= query parameter combined with Bearer authentication, rather than a simple direct path construction. This forced us to rethink our internal data-routing logic mid-build. We also encountered a significant Database ABI mismatch with our native better-sqlite3 drivers, which led us to migrate the entire backend to libsql (pure JS) to ensure cross-platform portability and seamless deployment. The pressure of the hackathon further intensified when we decided to perform a Python-to-Node migration in the middle of the event; we managed this transition by implementing a legacy schema auto-detection system to keep our existing data intact. On the frontend, we faced stability issues where Recharts would crash during window resizing, a problem we eventually isolated and solved using React Error Boundaries. Finally, navigating the YouTube API rate limits (capped at 10,000 units per day) remained our biggest architectural constraint, which we overcame by developing a sophisticated smart batching and pre-filtering algorithm to ensure every API call contributed directly to a high-value result.
What we learned
One of our most significant technical takeaways was that using structured LLM outputs via Zod and OpenAI completely eliminated an entire class of unpredictable parsing bugs, ensuring our data remained consistent across the entire pipeline. We also learned that the strict constraints of the YouTube API quotas essentially dictate the system's architecture; this taught us that smart pre-filtering is not just an optimization, but an absolute necessity for a functional production environment. To manage these constraints effectively, we implemented a dual-layer caching strategy, which successfully reduced redundant API calls by approximately 60% and significantly increased our system's speed. Finally, we discovered that deep transcript context is the ultimate differentiator for content quality; by feeding specific narrative cues into the generation process, we were able to move beyond generic AI output and create videos that truly resonate with the target audience.
What we are proud of
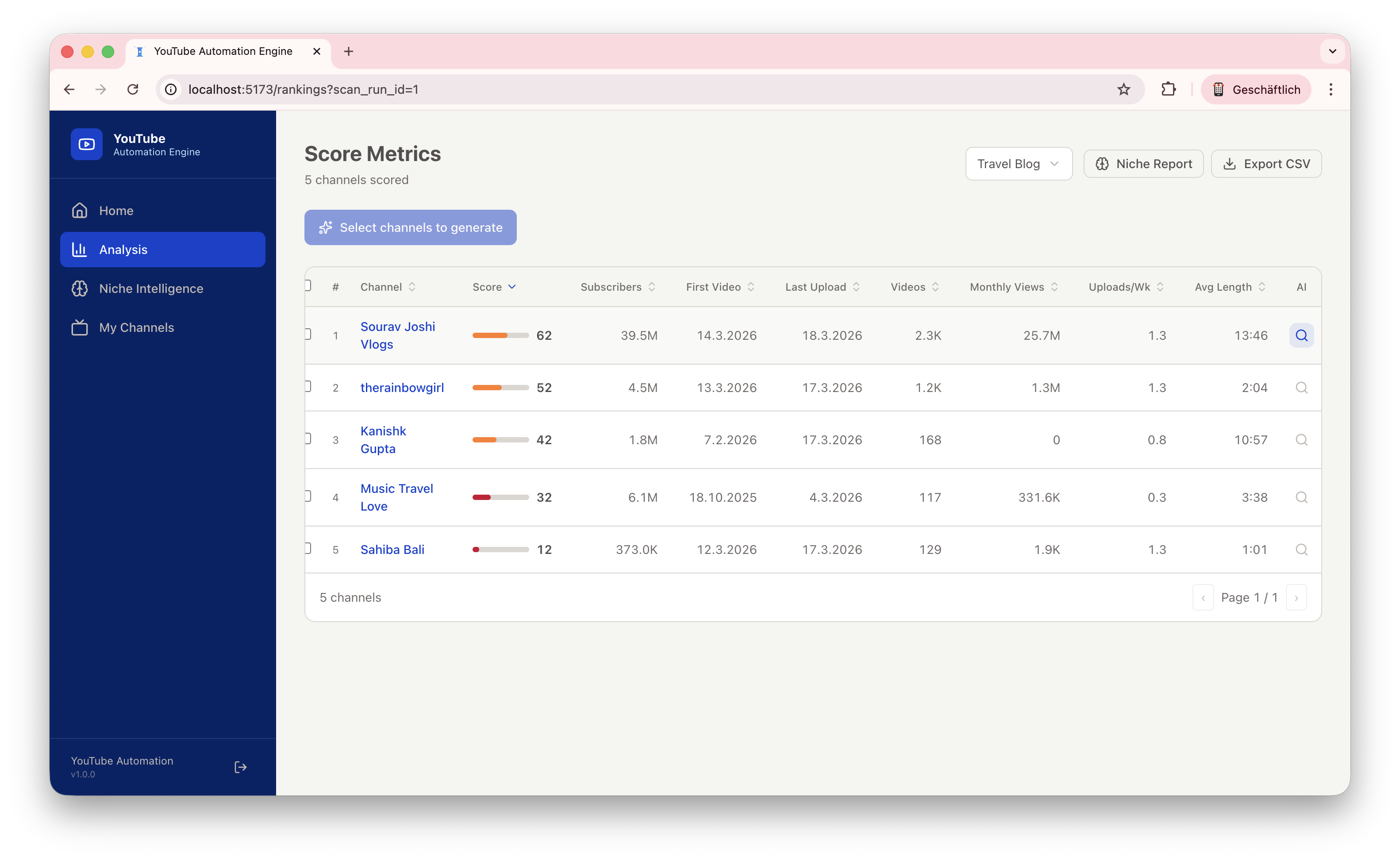
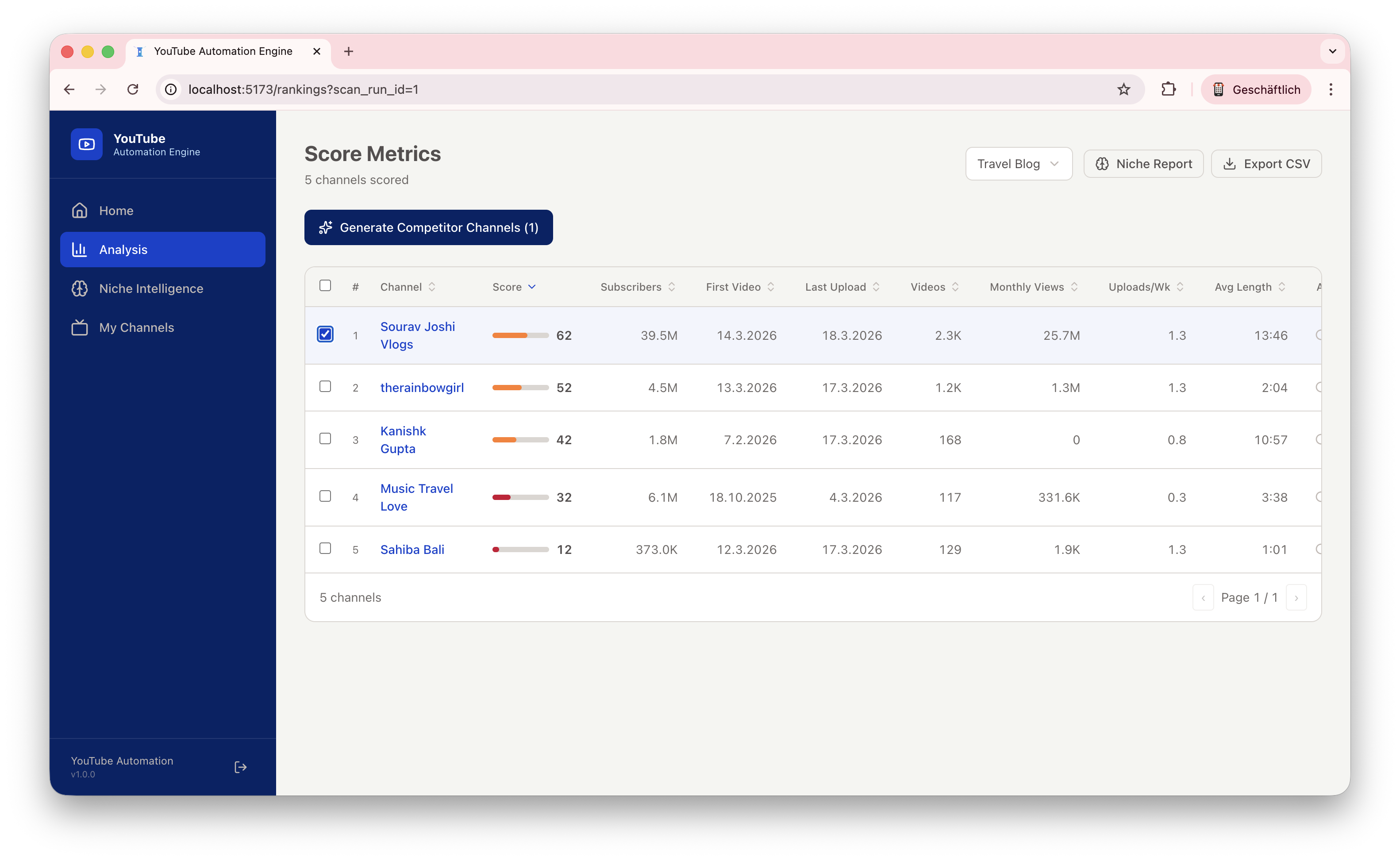
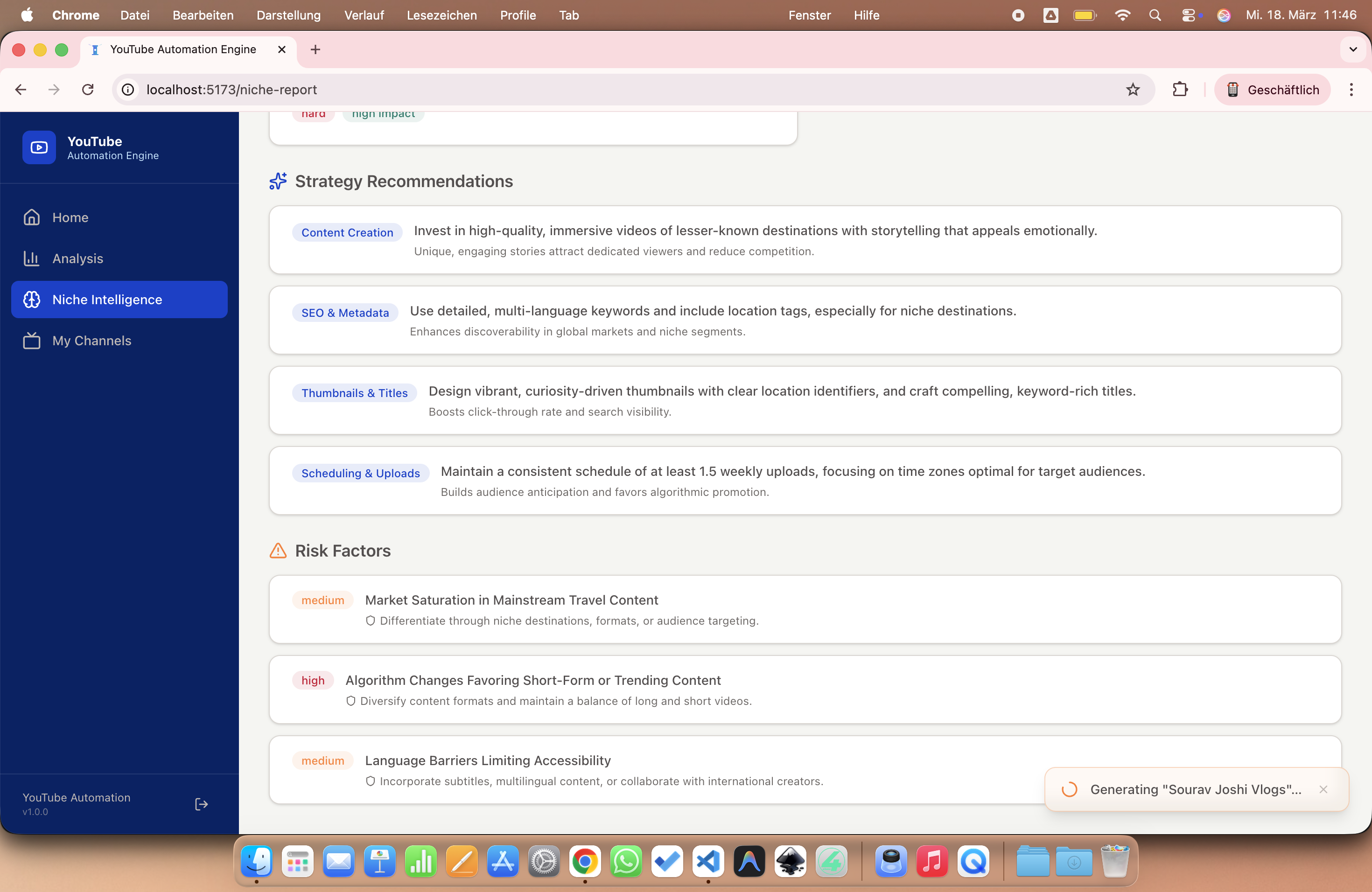
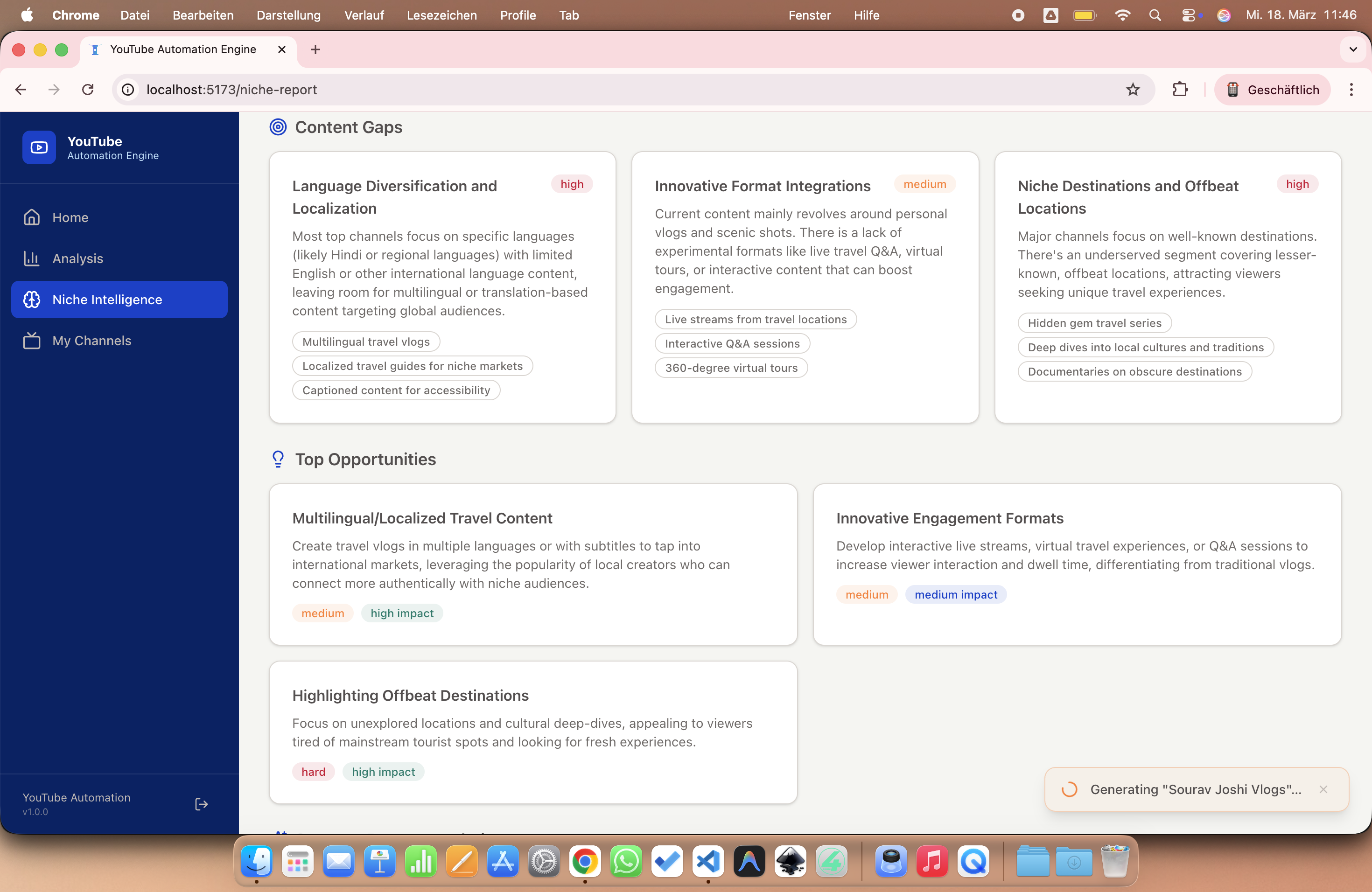
Our system features a comprehensive end-to-end pipeline that bridges the gap between initial keyword research and a fully generated competitor channel, complete with AI-driven visuals. Unlike "black-box" automation, we implemented a transparent and deterministic scoring engine, where every ranking and recommendation is fully explainable through a detailed score_reasons metadata set. This ensures that users can audit the AI's decision-making process at every step. To make these insights actionable, we developed a production-quality dashboard featuring interactive charts, high-performance data grids, and real-time background job tracking to monitor the engine's progress. The backbone of our content creation is a resilient asset pipeline, engineered with industrial-grade reliability features such as exponential backoff for API calls, strict concurrency limits, local caching, and robust fallback download mechanisms. Finally, we discovered that incorporating real transcript context into the generation process is the ultimate differentiator; it dramatically improves the quality and specificity of the generated concepts, moving them far beyond generic AI content.
Built With
- asgrid
- express.js
- knex
- llms
- n8n
- node.js
- openaigpt-4.1
- pino
- postgresql
- python
- python-pptx
- react19
- recharts
- sqlite
- tailwindcssv4
- typescript
- vite
- youtubeapiv3
- zod

Log in or sign up for Devpost to join the conversation.