




Inspiration
Every one of us has faced the struggle of finding suitable colleges to apply to. Despite consulting academic counselors (with many having no access to counselors) or some of the many online resources by college recommendations, we could not find any non-generic recommendations that used not only SAT scores, GPA, and acceptance rates. We wanted to find a solution that took more qualitative aspects into consideration. For instance, the diversity of the student body, the student body size, the gender distribution, etc. This led us to develop YourCollege CLI.
What it does
YourCollege CLI uses an Unsupervised Weighted K-Means Model to provide college recommendations based on factors like those mentioned above. We believe that factors like the diversity of the student body, the student body size, and the gender distribution help us better measure a student's experience in a particular college. This helps users obtain a more holistic college guide that not only provides the academic support they need, but also a suitable, competitive, comfortable, and opportunistic study environment for the next 3 to 4 years of their lives.
How we built it
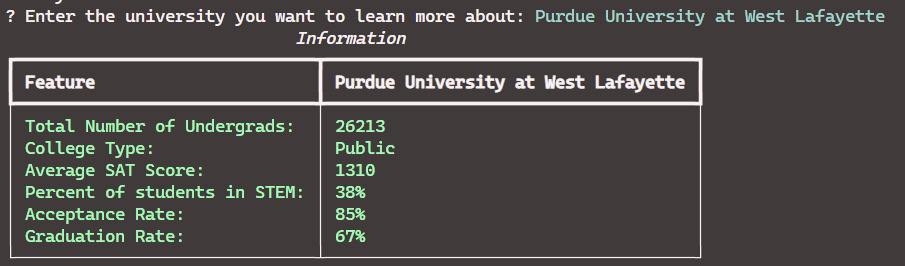
We built the application in two parts, the CLI, and the K-Means model. The model was made using the libraries provided by Scikit-Learn. We trained the model on data obtained from multiple Kaggle sources on US Colleges. We cleaned and combined the data to obtain a dataset that contained multiple features related to academics, student body, racial distribution, gender distribution, etc. The model then clusters colleges in the dataset into groups using weights based on preferences indicated by the user. After that, the user can enter one college they are interested in and the application will display colleges that are in the same cluster as the college specified by the user. The user can select recommended colleges and view information about them. The application is entirely based on the command line interface.
Challenges we ran into
There were many challenges that we ran into during the course of our project. The first and most prevalent challenge that we ran into multiple times throughout the course of this project was data. Finding data was difficult. While the common data sets of colleges contained the information we needed, they were, unfortunately, not in a format that could be used by us, and trying to convert it into an apt format would take more than the 36 hours given to us. We had to settle for datasets already present on Kaggle, which provided a new problem! Firstly, we had to use multiple data sets on Kaggle to get information about all the aspects our application was covering and obtain the results we wanted. Due to this, the naming conventions used differed from data set to data set, which led to a loss of a significant number of data points when we actually cleaned each individual data set. Furthermore, since each aspect had its own dataset, we had to create multiple data frames and merge them into one large dataset. In doing so, we lost a few data points - although not many, they could have proven effective when it came to training our model.
Accomplishments that we're proud of
WE FINISHED! If you told us 36 hours ago we would have such a sophisticated project ready to submit, we might not have believed you. However, we never gave up and kept persisting despite the challenges our project threw against us. For most of us, this is our first hackathon, and getting this far is a monumental achievement for us. Another achievement we are proud of is our teamwork: despite our differences in technical expertise and competitive experience, we were able to find common ground that we can all work towards enthusiastically, helping each other grow, while we complete the project in perfect harmony.
What we learned
While all of us read something or the other about machine learning algorithms, being able to implement them in a real-world context was unknown to us. However, through this project, we have acquired the knowledge and practical experience needed to develop sophisticated machine-learning models and implement them to solve real-world problems. Furthermore, we have come to realize that in such a technical field, the more trivial aspects are of significant importance: while data retrieving and cleaning might sound trivial, they are what determine the accuracy, complexity, and quality of the model we are developing. If the data we use is not well-rounded, clean, and well-structured, the model will not be able to learn effectively and hence will not solve the given problem. Hence, we have learnt strategies to develop such large problems into smaller visions that streamline our focus, time, and efforts, enabling us to move onto next steps with more confidence, and effectively develop a suitable technical solution. This opportunity also helped us further refine our communication and collaboration skills, which are important skills that we need as aspiring computer scientists.
What's next for YourCollege CLI
We believe that YourCollege CLI has the potential to help many aspiring high school students find their suitable colleges to apply to. Our application has vast scope for improvement:
- As of now, the clustering is based on K-Means and a few college features. If we can find data for other aspects, such as weather of the area, the overall safety, the internship/research opportunities available in and around the campus, along with updated information from common data sets of colleges, we could develop a more up-to-date and sophisticated application.
- By considering more parameters to suggest colleges, we would be able to build a model using multilevel clustering, which helps group colleges into clusters based on more minute details.
- As of now, the application is implemented through CLI. In the future, we can upgrade to a GUI and include more information about colleges from not only in the US, but from around the world.


Log in or sign up for Devpost to join the conversation.