
Inspiration
With technological advancements in transportation, communication, and networks, people's lifestyles have changed drastically over the years and it has become much easier for people to move and live in different cities across the world. We decide to design a web app allowing users to obtain personalized and friendly results.
What it does
Our team has developed an ML clustering-based web app to help users identify their dream city to live post-COVID aside from family influence.
In this project, since we have the clustering result, we decided not to put all the data points because that would cause confusion among users. Massive dots would also cause uncomfort for a certain group of audience.
We also calculated the score differently. We would ask users to input an ideal value that we can compare with the data from the cities. If the users don’t think a characteristic is important, they can simply not add it to the scale.
Current Features
We used Streamlit to construct a web app allowing the user to search for a list of desired cities through either multiple preferences or a dream city.
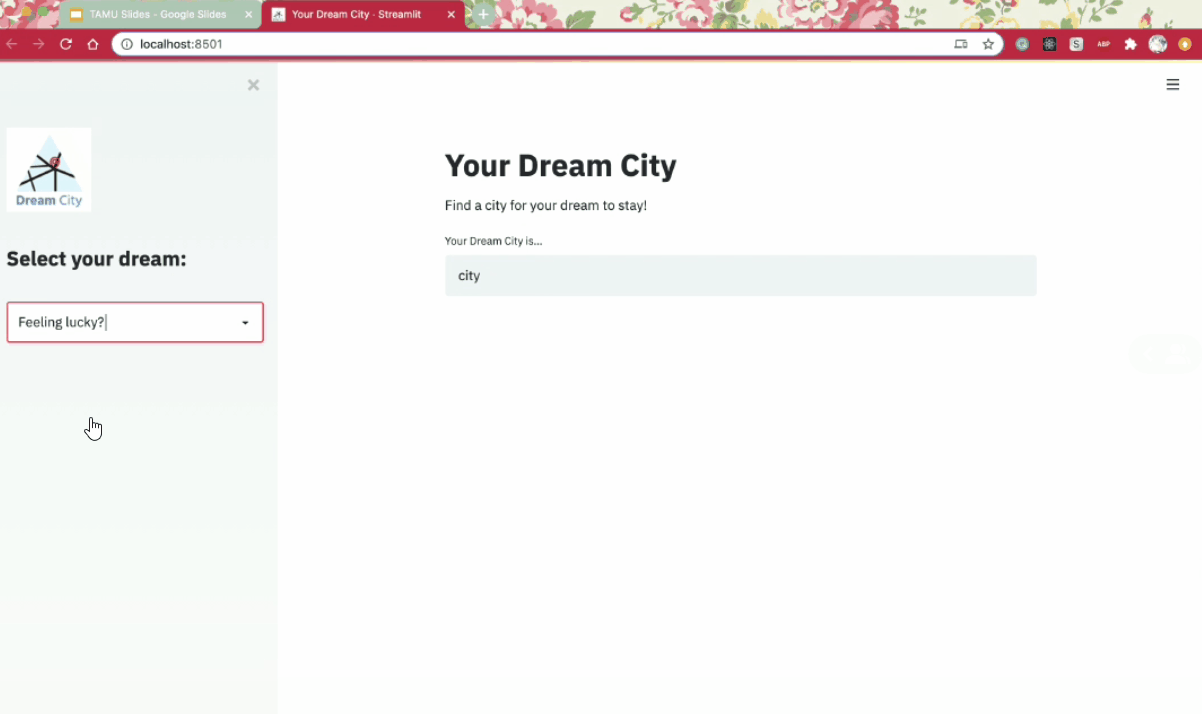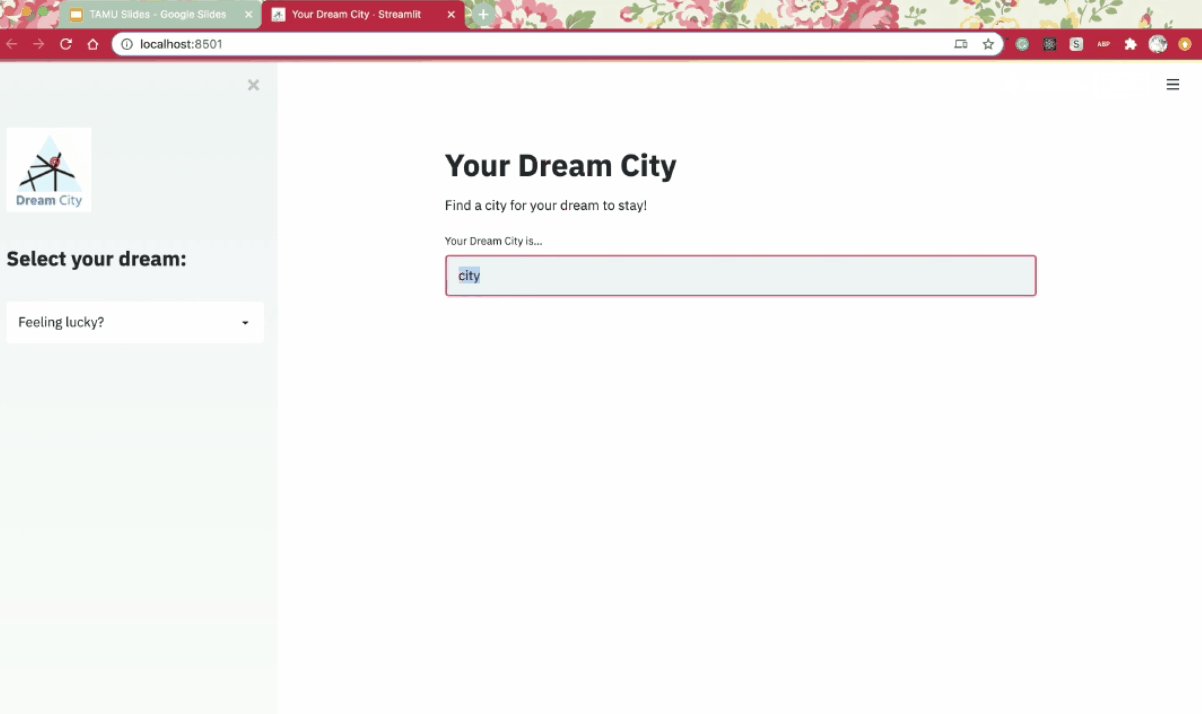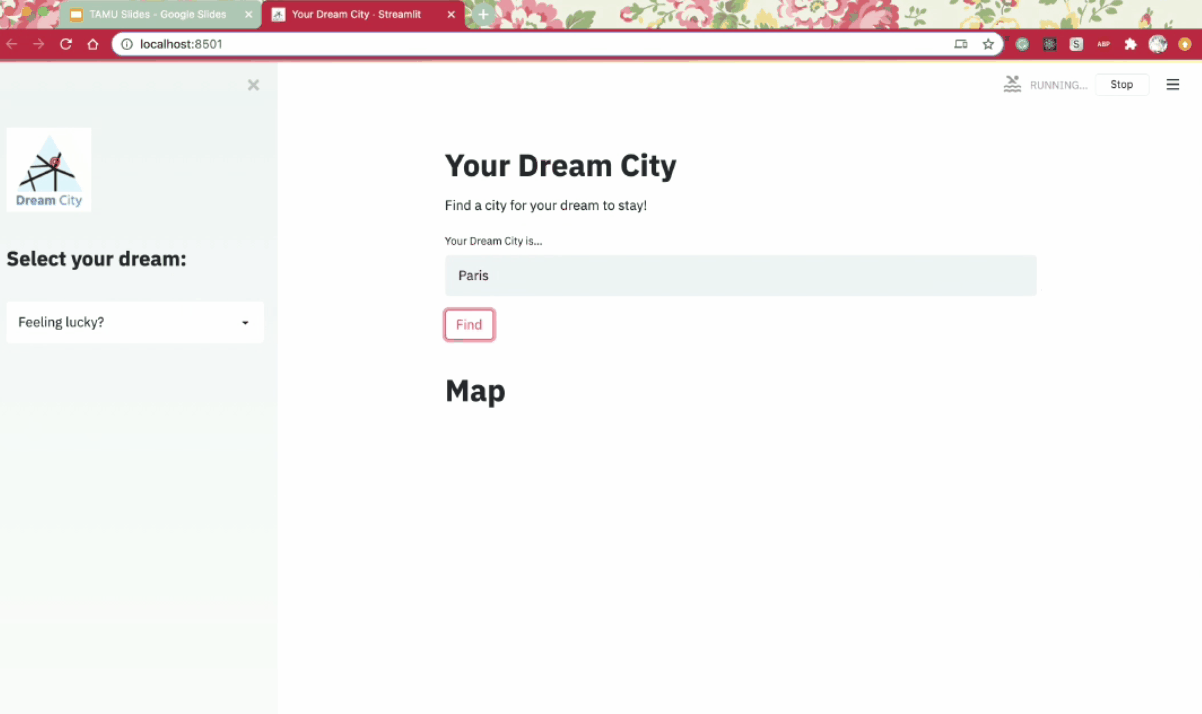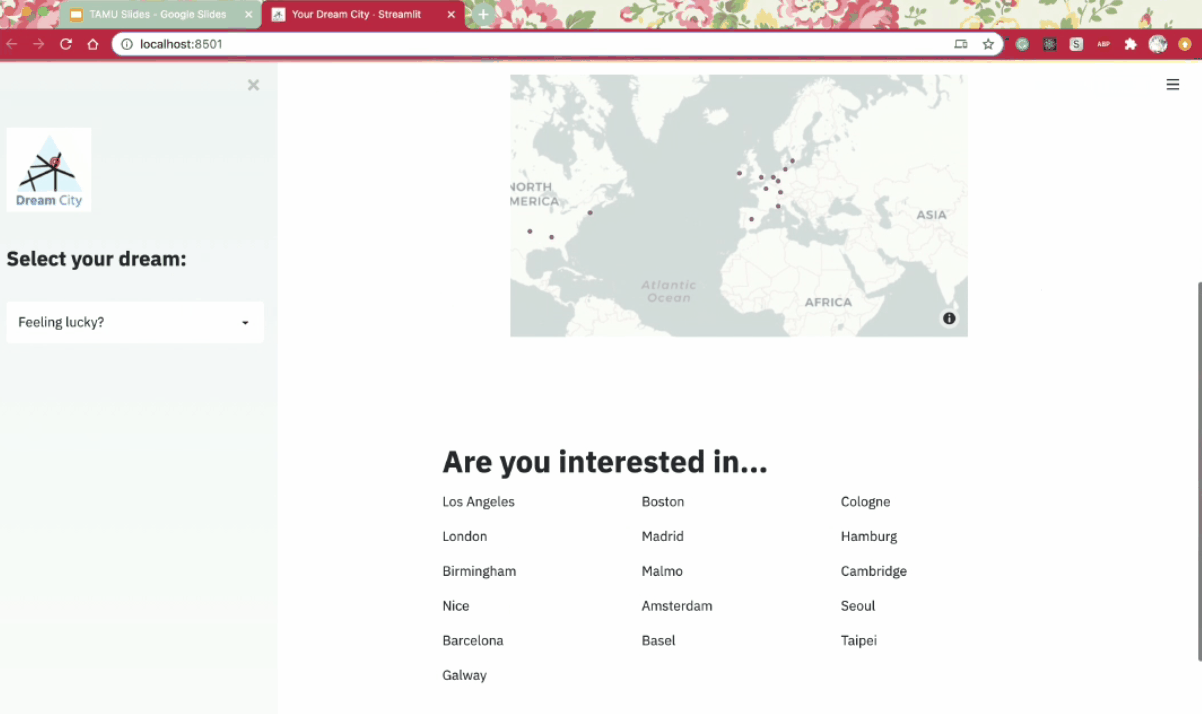
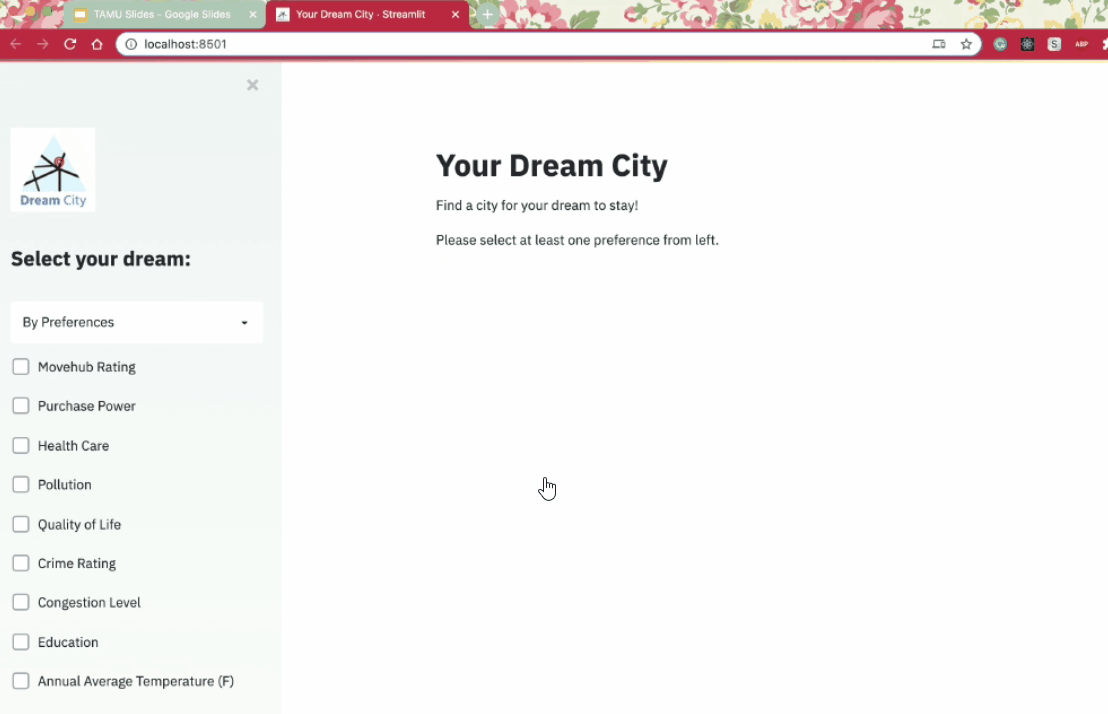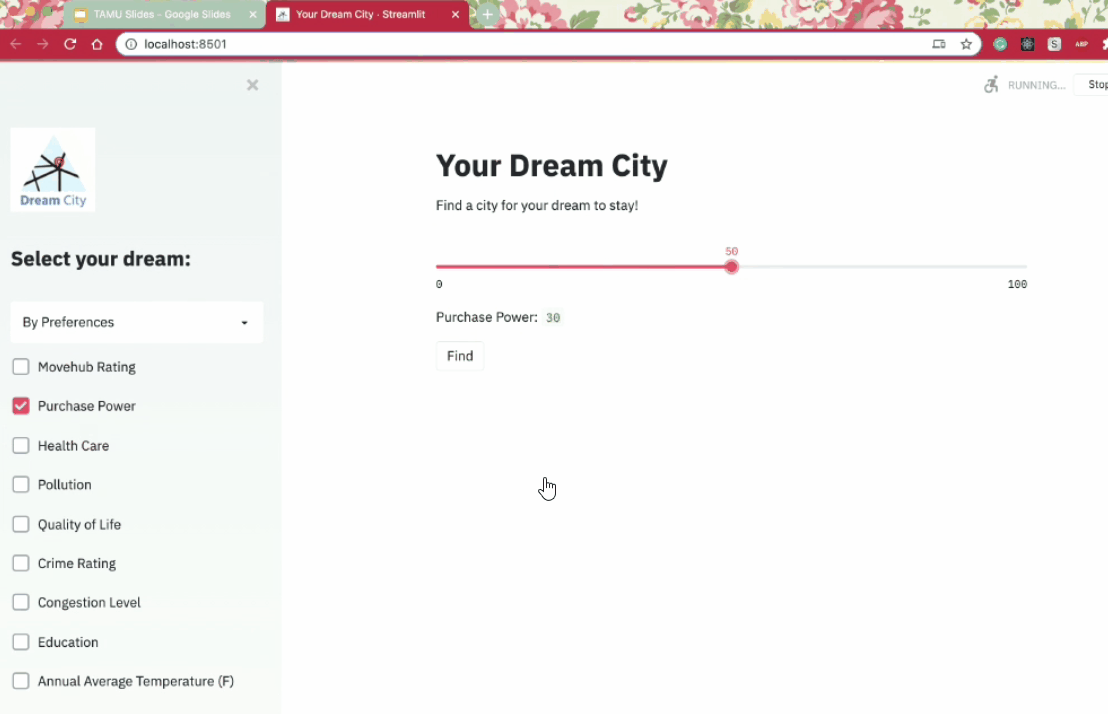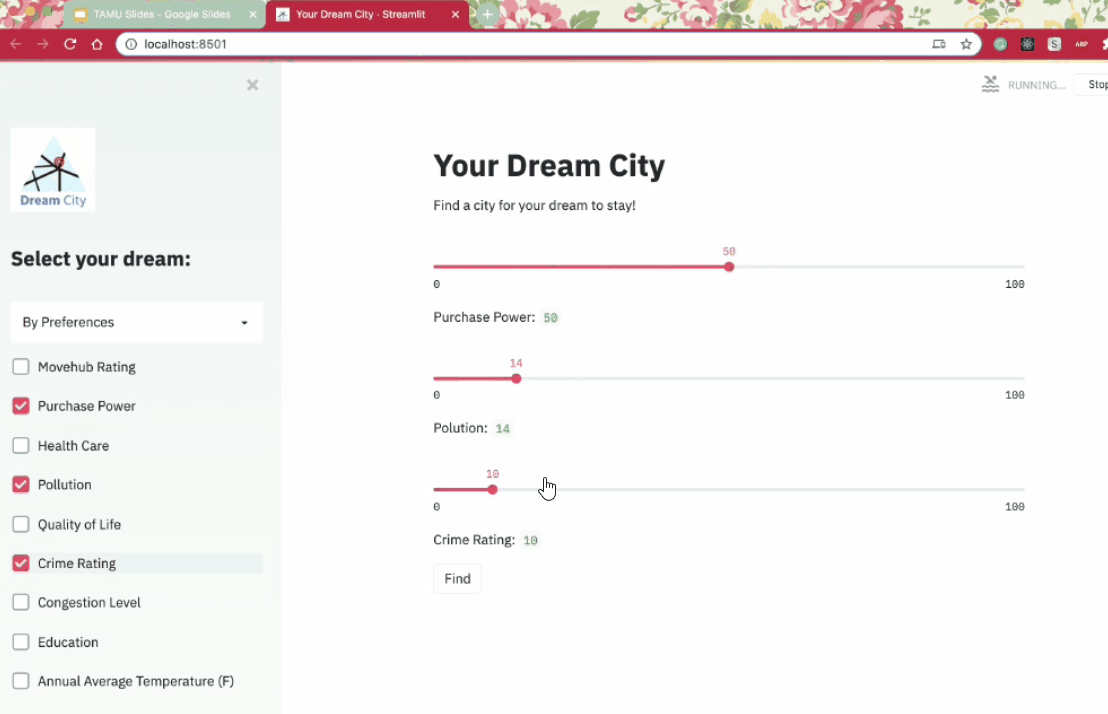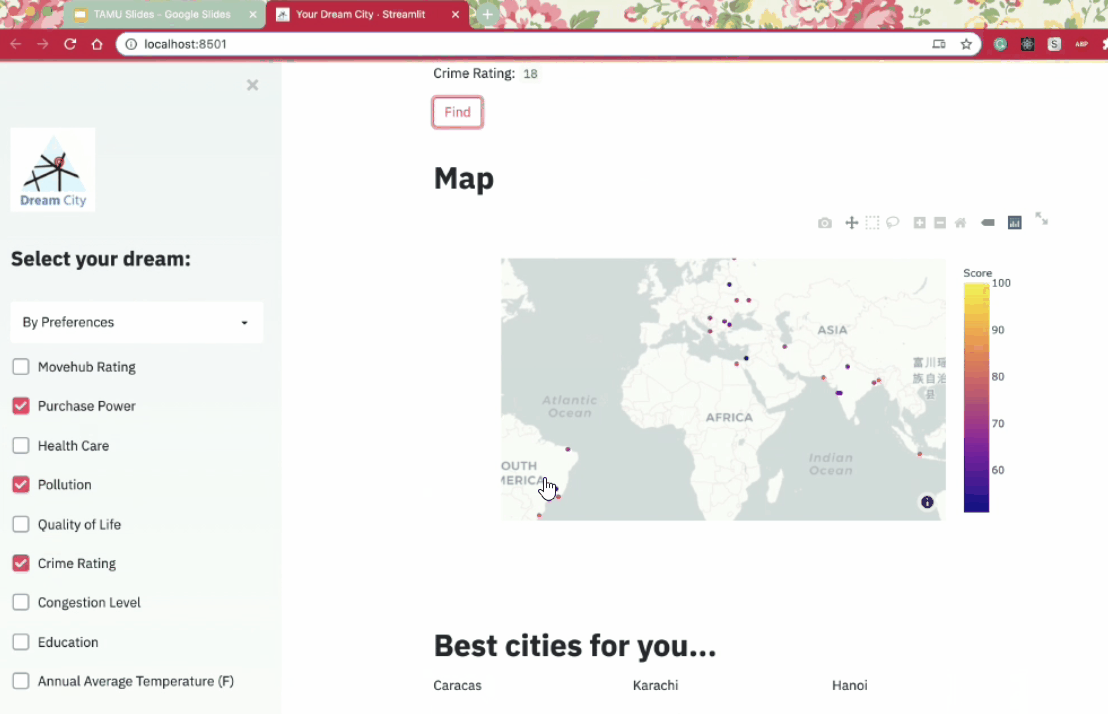
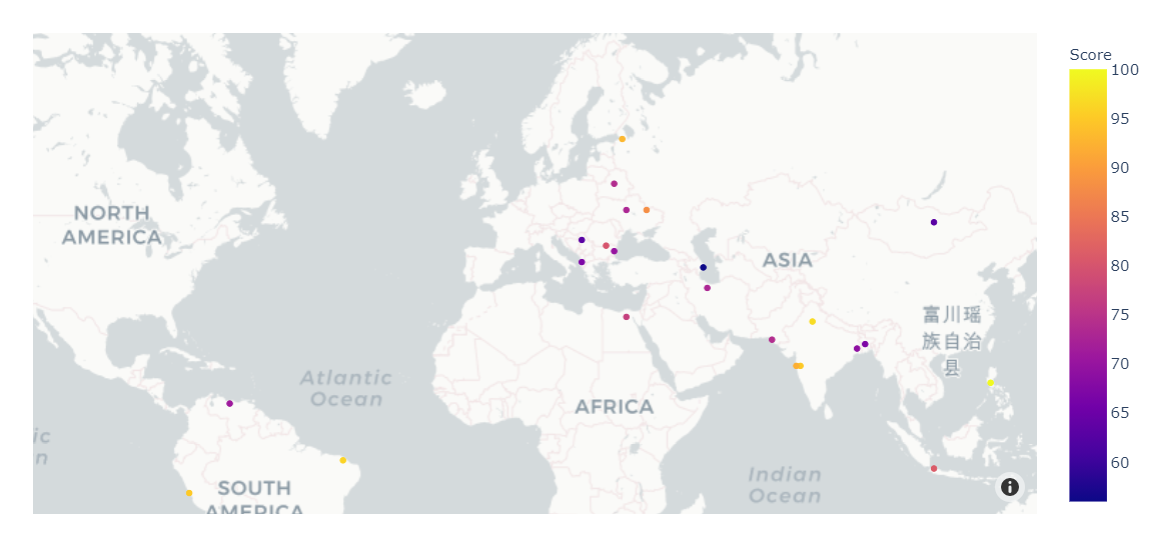
For searching by preferences, we display the searched cities on a world map using Plotly where users can covers over for more detailed information about each city to get a better understanding. The app also lists the best and worst cities based on scores from our model for easy result retrieval.
For searching with a dream city in mind, we use our clustering algorithm to generate other cities around the world with similar characteristics to the desired city.
Click for full documentation of the web app.
How We built it
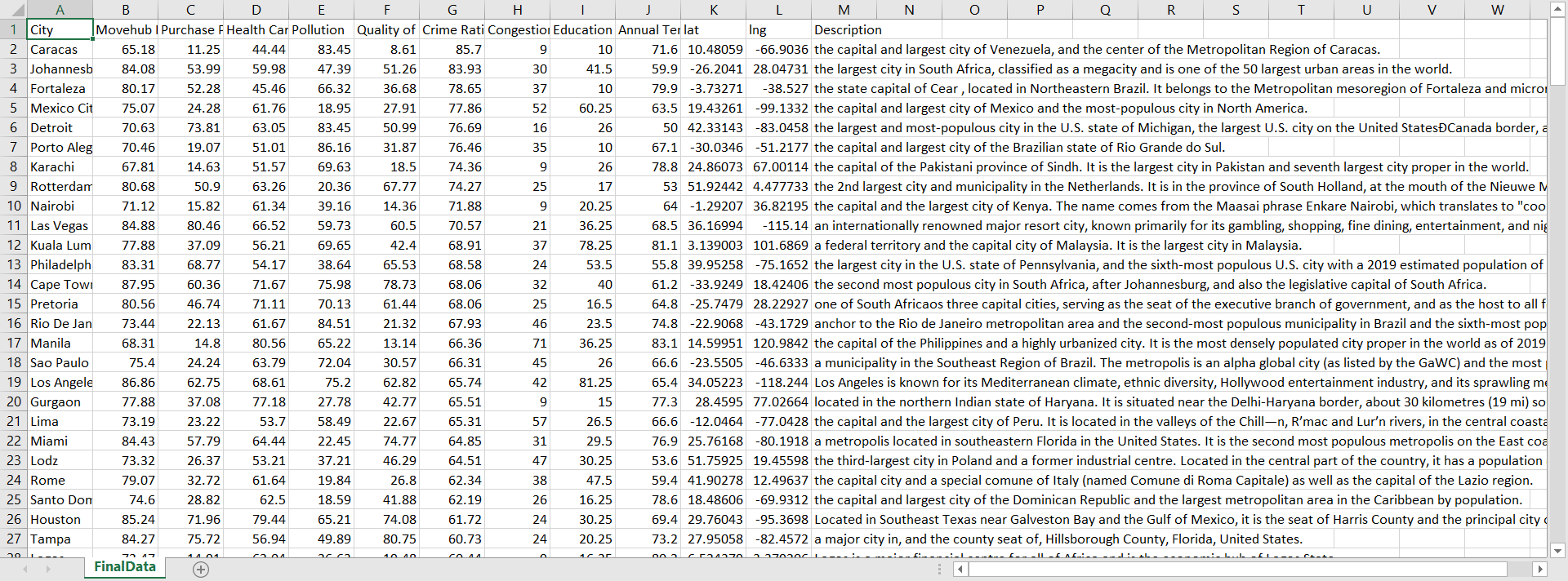
We started off by thinking we should build a product as close to users as possible. Hence, we decided to make a survey that collects data from 60+ people from a diverse background and age. As a result, we discovered that besides the criteria given by the starter pack, three other topics stand out: Education, Climate, and Traffic. We fetched the data for the new preferences online and added those to our dataset.
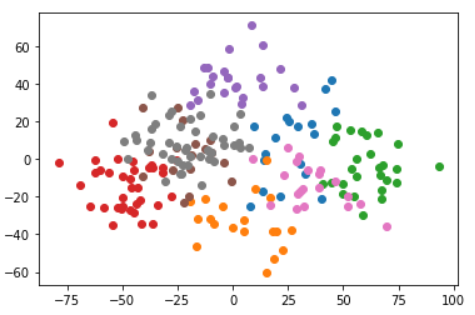
After we finally cleaned up the data, we first tried to reduce the dimension of the features to 2D by applying the Principal Component Analysis (PCA), which decomposes the dataset with nine features such that it explains each data point according to its maximum variance. This is done to ensure that we do not encounter problems of high dimensionality when analyzing the dataset.
Then we tried to visualize the data by plotting it in 2D and found out that the data have approximately uniform density distribution. This means that we should not choose a density-based clustering algorithm such as DBSCAN, and we should also keep all the outliers which are potential cities with very special characteristics that could be one of the user’s choices. We also don’t want Spectral Clustering, Hierarchical Clustering, or Agglomerate Clustering because the data have no clear shapes. Finally, we decided to use k-means for my clustering model because it has the best performance.
Then we converted the jupyter notebook to a Streamlit python script in order to create an interactive web app that can take various user inputs. Using a python front-end framework allows us to easily port our data analysis model to a web server as well as allowing users to interact smoothly with instant feedback. By linking data analysis variables to the user input, we were able to generate dynamic and personalized data for the users.
Challenges We ran into
Because of the large scope of the project, we encountered missing data when downloading data from various databases. We ended up manually searching datas for missing cities and filling them in to create a complete, accurate database. For the ones we cannot find, we did an imputation based on relevant data, such as the country’s data.
Another challenge we encountered was to determine the number of clusters used in the k-means model. If the number of clusters is too large, it will greatly impact the accuracy of the model because there might not be a clear distinction between clusters. However, if the number of clusters is too small, we will yield a large number of recommended cities to the user which is overwhelming. By using statistics, we decided to fix the cluster size to 8.
Lastly, we have never had experience with front-end development in python, which is indeed very different from traditional javascript development. Fortunately, through consulting various Streamlit documentation, discussions, and manipulation of the APIs, we were able to construct a web app which showcases all features of our model in a clear and appealing form.
Accomplishments that We're proud of
We self-learned a few python libraries including SKLearn, Pandas, Plotly, and Streamlit. We figured out the interaction in between and successfully built a functioning web app according to our design.
What We learned
We did learn quite a lot of libraries and gained a ton of development and design experience. Walking through this full process in such a short amount of time gave us a full overview of what a data science project may look like. We learned how to find suitable datasets initially with ideas and how to handle missing data. We also learned how to analyze data by a clustering model and went through the process of choosing the optimal clustering model to suit the scenario based on the visualized data.
What's next for Dream City
We could potentially use a more advanced and more refined clustering model but we are short of time. The k-means model right now does not suit perfectly well with the scenario and it tends to favour the central cluster over the other ones.
We could also add reference links to desired cities so that users will have a better experience exploring the dream cities. Priority scales can also be added so that each feature will have a different weight and users could prioritize some of the important ones over others.
Built With
- clustering
- data
- figma
- jupyter
- machine-learning
- matplotlib
- plotly
- python
- scikit-learn
- streamlit




Log in or sign up for Devpost to join the conversation.