


Inspiration
San Francisco's Board of Supervisors meetings run for hours, are filled with procedural language, and cover dozens of topics in a single session. Most residents simply don't have the time or energy to sit through entire meetings to find the few agenda items that actually affect their neighborhood, business, or daily life, and most residents are never exposed to these topics in the first place.
So we built a solution that makes civic engagement as easy as a Google search, informing the city about what its policymakers are up to.
What it does
SFGovTV++ turns San Francisco’s Board of Supervisors meetings into an interactive video experience that anyone can navigate in seconds:
Featured Videos & Discovery
- On the home page, you’ll find the latest or most relevant council sessions front and center, alongside a powerful search bar.
Dual-Mode Search
- Keyword & Tag Filtering: Instantly narrow down meetings by typing keywords (e.g. “bike lanes,” “budget,” “housing”) or selecting from curated tags.
- AI-Powered Chatbot: Flip on the “Ask AI” toggle and pose questions in plain English—“What did they decide about the new park?” or “Show me discussions on public safety”—and get precise, context-aware results drawn from every transcript.
At-a-Glance Meeting Summaries
- As soon as you open a video, an AI-generated overview highlights the meeting’s key takeaways, so you know exactly what happened without watching hours of footage.
Clickable Agenda Navigator
- A sidebar lists every agenda item with its own AI-written summary. Click any entry to jump straight to that moment in the video—no fiddling with timestamps or guesswork.
Advanced Playback Controls
- Speed Up to 3×: Breeze through presentations or dial it back for detailed discussions.
- One-Click Skips & Precision Seek: Skip past irrelevant sections, or drag the timeline with frame-level accuracy—perfect for fact-checking a vote or quote.
- All of this sits inside a sleek, YouTube-style interface, enhanced by meeting-specific “chapters” and AI summaries. Civic video just got as easy to explore as a web search.
How we built it
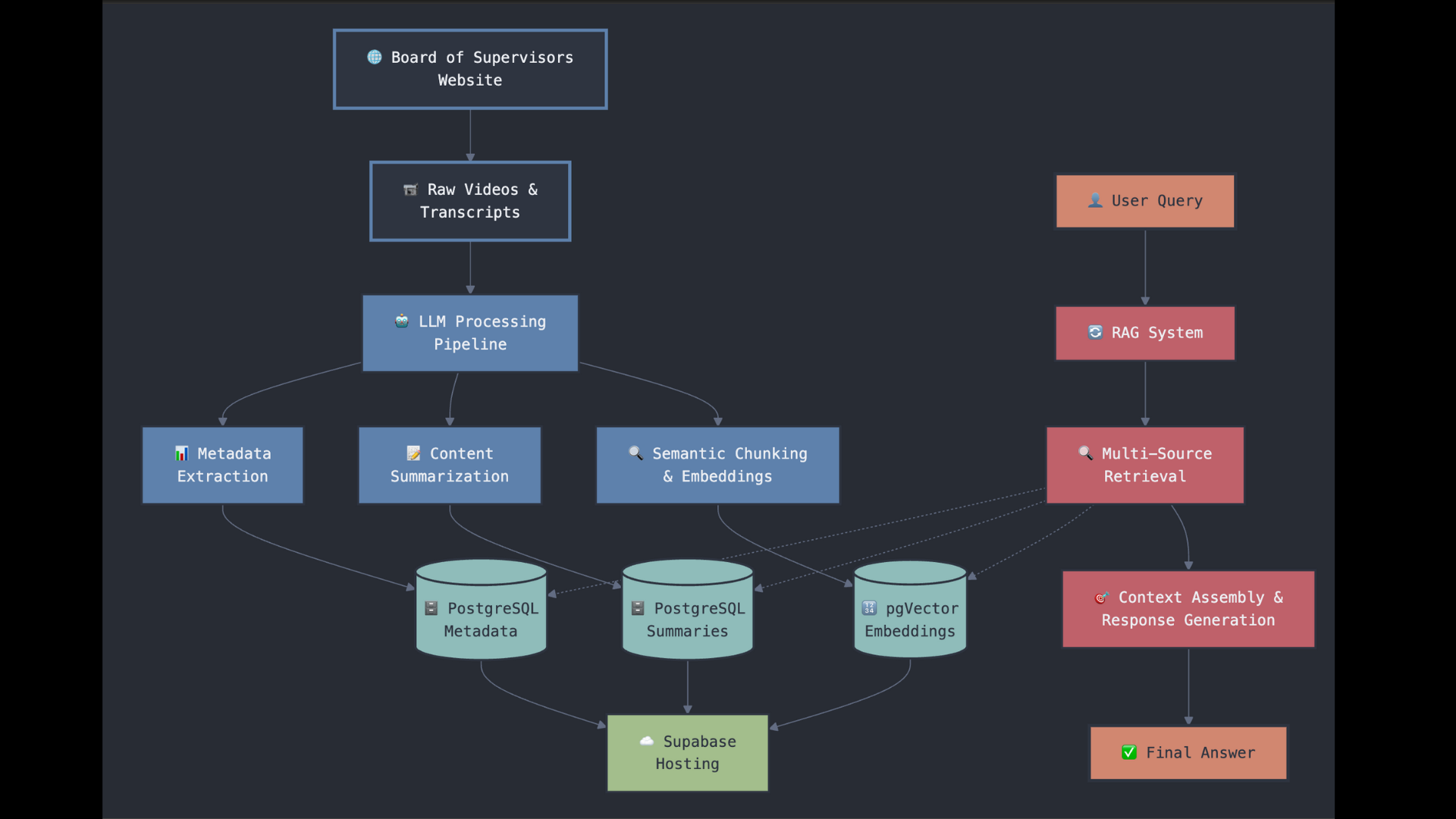
- Data Ingestion
- Python + BeautifulSoup4 scrapes each Board video + caption file on a cron schedule.
- In-script transcript normalization (align timestamps, clean speaker labels).
LLM Pipeline (Gemini)
- Metadata Extraction: Gemini parses dates, agenda titles, sponsors, vote counts → writes to Postgres.
- Content Summarization: Gemini generates a “headline” summary + per-item synopses → stored in a summaries table.
- Semantic Chunking & Embeddings: Break transcripts into ~2 min chunks → Gemini embedding API → pgVector table.
Storage & Front-End Hosting
- Supabase Postgres + pgVector holds all metadata, summaries, and vectors.
- Vite + React front-end deployed on Vercel: featured sessions, dual-mode search, video player with AI summaries & agenda “chapters.”
RAG-Style Query Service
- User query → our API endpoint invokes the RAG orchestrator.
- Multi-Source Retrieval:
- Fast filters on metadata (dates, tags)
- Full-text search on summaries
- k-NN search over pgVector embeddings
- Prompt assembly: Top hits merged into one context block
- Gemini chat completion returns concise answers, plus “click-to-jump” timestamps and inline citations.
By wiring Supabase’s Postgres+pgVector to a Gemini-powered pipeline and a Vite/Vercel front end, we turn multi-hour SF Board meetings into sub-second, Google-search–style insights.
Accomplishments that we're proud of
Scaling Transcript Parsing
- Volume & Noise: Multi-hour videos yielded millions of words—with overlapping speaker labels, timestamp drift, and OCR artifacts in captions.
- Smart Chunking: We built a sliding-window splitter that groups 1–2 minute segments by semantic coherence (using punctuation and speaker turns) before normalization, keeping chunk sizes manageable for embedding and summarization without losing context.
- Resource Management: Parallelized the Python/BeautifulSoup scraper and normalization scripts across serverless workers to avoid timeouts and CPU spikes.
Building a Robust RAG Pipeline
- Hybrid Retrieval Design: Balancing fast metadata filters (dates, tags, supervisors) with vector-based similarity search demanded careful schema design in Supabase Postgres + pgVector.
- Index Tuning: We experimented with different embedding dimensions, chunk overlap ratios, and ivfflat/hnsw index configs to hit sub-50 ms nearest-neighbor lookups at scale.
- Context Assembly: Merging top-K hits from three sources (metadata, full-text summaries, vector chunks) into a single Gemini prompt without exceeding token limits required dynamic pruning and priority heuristics.
What's next for SFGovTV++
- Advanced RAG: Hierarchical retrieval + long-context Gemini (100K tokens) for end-to-end meeting context and multi-hop follow-ups. Indexing based on temporal data.
- UI/UX Polish: Collapsible, mobile-first agenda panel; real-time topic alerts; advanced filters (Supervisor, date, department).
- External Feeds: Ingest news outlets, RSS, social media—link press coverage and city transcripts in a unified, searchable timeline.
Built With
- beautiful-soup
- claude
- fastapi
- gemini
- langchain
- postgresql
- rag
- supabase
- vector-embeddings
- vite



Log in or sign up for Devpost to join the conversation.