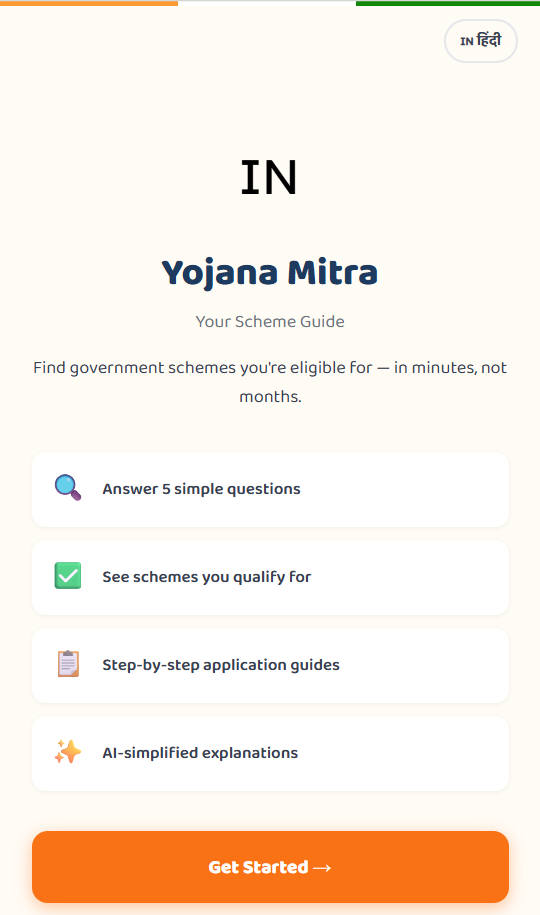
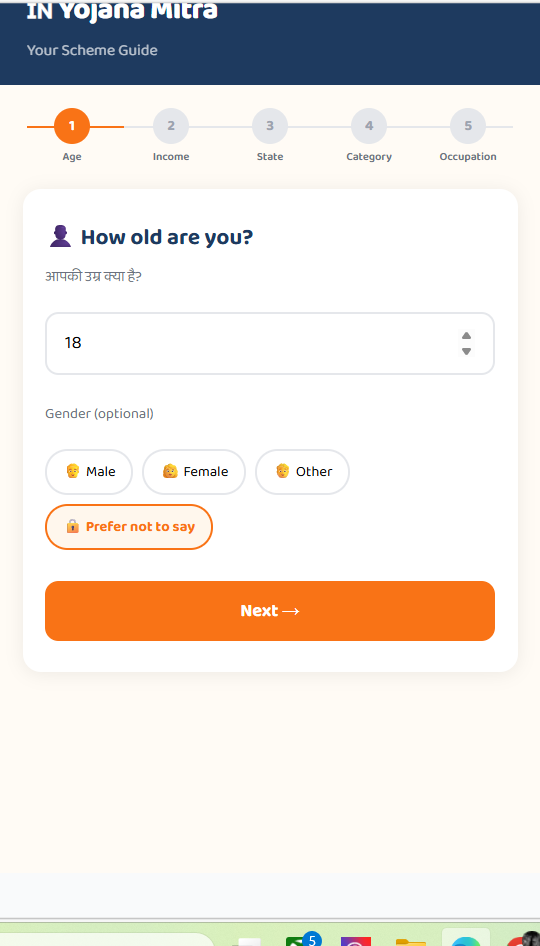

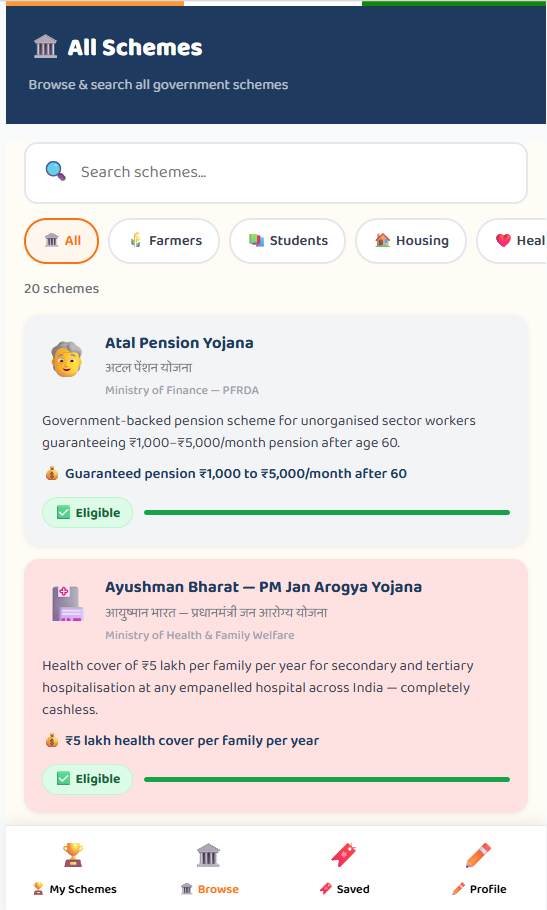
Inspiration Discovering and understanding Indian government welfare schemes is overly complex. Yojana Mitra was built to democratize access by simplifying bureaucratic documents and instantly matching citizens with the benefits they deserve.
What it does It’s a welfare discovery platform featuring a custom eligibility engine that matches users to schemes based on their profile. An AI-powered Simplifier (using Gemini 2.5 Flash) translates dense requirements into plain language. It also includes an automated PDF ingestion pipeline to extract and structure new scheme data directly from official documents.
How we built it The frontend is a responsive SPA built with React 18 and Vite. The backend runs on Node.js/Express, using MongoDB for storage and Redis for caching. We integrated Gemini's API for AI features and built a custom ingestion pipeline using pdf-parse and OCR. The entire stack is containerized using Docker.
Challenges we ran into Working with Gemini's free tier meant strict rate and token limits. We solved this by building a smart text truncation system and an automated JSON repair mechanism to handle AI output errors. Synchronizing the backend eligibility logic on the client side for real-time UI feedback was another major hurdle.
What we learned We gained deep, practical experience in orchestrating complex file ingestion pipelines, managing third-party AI rate limits, and implementing robust dual-layer caching strategies in a full-stack environment.
What's next for Yojana Mitra The immediate next step is the full production deployment of the platform. We plan to deploy our Dockerized backend, frontend, and database to a scalable cloud provider so citizens can actually start using it. Following a successful deployment, we aim to expand our custom LanguageContext to support more regional Indian languages beyond Hindi and English, maximizing accessibility across different states.

Log in or sign up for Devpost to join the conversation.