Predicting Yelp Star Ratings Using Natural Language Processing of Yelp Written Reviews
Bridget Griswold, bgriswol Madison Peters, mpeter35 Hannah O’Keeffe, hokeeffe Cal Stellato, cstellat
Introduction
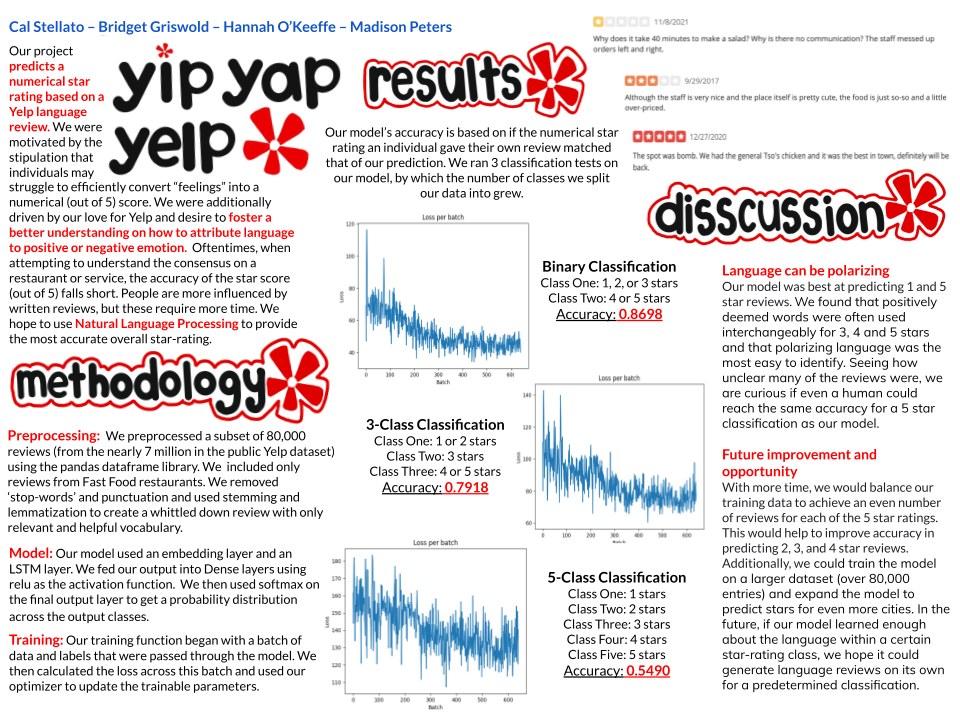
Our project aims to provide a more accurate numerical rating to language reviews, as some individuals may struggle to effectively convert “feelings” in words into a numerical score. We hope to foster a better understanding on how to attribute language to positive or negative emotion. We were originally motivated by our love for Yelp (and other online rating sites, such as Amazon). However, these sites' use of a “star” (out of 5) score falls short. We are more influenced by written reviews, but these require more time to process and interpret. This is similar to the motivations of our implemented paper, which seeks to create an automatic star prediction based on a language review. Ergo, this is a classification problem. We hope to create a more holistic and accurate numerical representation of user ratings based on written reviews.
Related Work
We found a prior project done using Amazon rather than Yelp, found in a Github here: https://github.com/imdeepmind/RatePrediction. In the Github provided the user creates a project that aims to predict the start rating based on given reviews of a product. In order to do this the user relies on word tokenization to convert the reviews in numbers which in turn represents the number of stars. They then use CNN and LSTM networks to train the given dataset.
Other relevant works: -https://github.com/mansipatel2508/Yelp-Review-Stars-Prediction-with-Machine-Learning -https://cs229.stanford.edu/proj2015/331_report.pdf -https://cs229.stanford.edu/proj2014/Chen%20Li,%20Jin%20Zhang,%20Prediction%20of%20Yelp%20Review%20Star%20Rating%20using%20Sentiment%20Analysis.pdf -https://www.sciencedirect.com/science/article/pii/S2214785320398229
Data
We will be using the Yelp dataset (https://www.yelp.com/dataset) which is a subset of Yelp's businesses, reviews, and user data that has been made publicly available for use for personal, educational, and academic purposes. We will specifically be using the written reviews and associated ratings data. This dataset is very large and we will likely have to restrict the data to a given city/or region. The dataset has been set up well by Yelp in that the review.json file contains the review text and star rating, which we should be able to easily extract. From there we will have to preprocess to suit the model, but we do not expect this to be extensive.
Methodology
For this project we are modeling it based off of the Amazon Star Prediction Github. The architecture we are using is pytorch. We are training the model using both LSTM layers as well as CNNs. We believe that the hardest parts about implementing this project based off of the existing paper, is ensuring that our dataset is narrowed down to a manageable size which will be handled in preprocessing. We also worry about the accuracy of the Github we are modeling because the author notes that it only reached 50% accuracy. We are attempting to improve this accuracy by grouping the stars with 4 and 5 representing a positive review and 1 and 2 representing negative reviews, and 3 being neutral. We are hoping by implementing this grouping of stars into positive, negative, and neutral we will diminish any of the difficulty of defining a review that could either be a 4 or a 5 and just labeling it as a positively starred review.
Metrics
For our project, what constitutes success is how accurate we can train our model to represent that number of stars given with an associated review. If our model predicts that the review given was a high review then we would expect the given review to have five stars, same with if there is a negative review, then it would have one star. The paper we will base our project on has a 50% accuracy. To improve this accuracy we plan to use groups of stars, for example 4 and 5 correlate to positive reviews while 1 and 2 correlate to negative reviews. Our “experiments” to test accuracy will print out the correct vs. predicted star score ratings. We may also try to use different segments of the Yelp data to see how this impacts accuracy (restaurants vs. landmarks vs. tours, etc.) Still, success to us will be reaching a similar accuracy (50%) to our modeled paper. Our base goal is to use language processing to accurately take a group of ratings and output a score of how highly users rated the business. Our target goal is to predict the exact stars rather than a general prediction and evenly predict each “grouping” of ratings (predicting low (1-2) vs high (4-5) scores evenly accurately). Finally, our stretch goal is to output what the model is actually learning, or what relationships the model is learning.
Ethics
What broader societal issues are relevant to your chosen problem space? A broader societal problem is the difference in qualitative feelings to quantitative ratings in many social platforms, such as Facebook, Why is Deep Learning a good approach to this problem? Deep learning is a good approach to this problem because of the vast amount of data available in the YELP API. Our program will be trained using deep learning to hone in on the best method to predict the amount of stars based on a user’s review. If this were a dataset with, say, 10 reviews and corresponding stars, then deep learning would not be a reliable predictor. However, given the vast quantity of data in the YELP dataset, deep learning is a viable method of prediction. Who are the major “stakeholders” in this problem, and what are the consequences of mistakes made by your algorithm? The major stakeholders in this problem are YELP the company, the restaurants that are listed on YELP, and the restaurant customers that use YELP. A mistake made in our algorithm would have consequences for all 3 stakeholders. For example, a potential flaw is that our algorithm may not accurately quantify qualitative customer reviews, perhaps skewing reviews to star ratings that are too low. In this case, restaurants will receive comparatively low reviews, which will affect how likely a YELP user is to go to their restaurant. In addition, another potential flaw is that our algorithm is simply inaccurate. In this case, YELP users will begin to distrust our algorithm, which will lead to bad restaurant experiences for customers, a decreased user base for YELP, and decreased customer flow for restaurants whose desirability is not accurately portrayed on YELP.
Division of labor
Bridget will be focused on debugging and assisting all individuals with the code, and will be in charge of preparing the oral presentation and final write up. Hannah will focus on the Yelp dataset and preprocessing of the data. Madison and Cal will work together on the Language Processing model. However, we are a close-knit team and we will all be working cross-functionally and helping each other out in all aspects of the project.

Log in or sign up for Devpost to join the conversation.