-
WebApp1
-

WebApp2
-
WebApp3
-
WebApp4
-
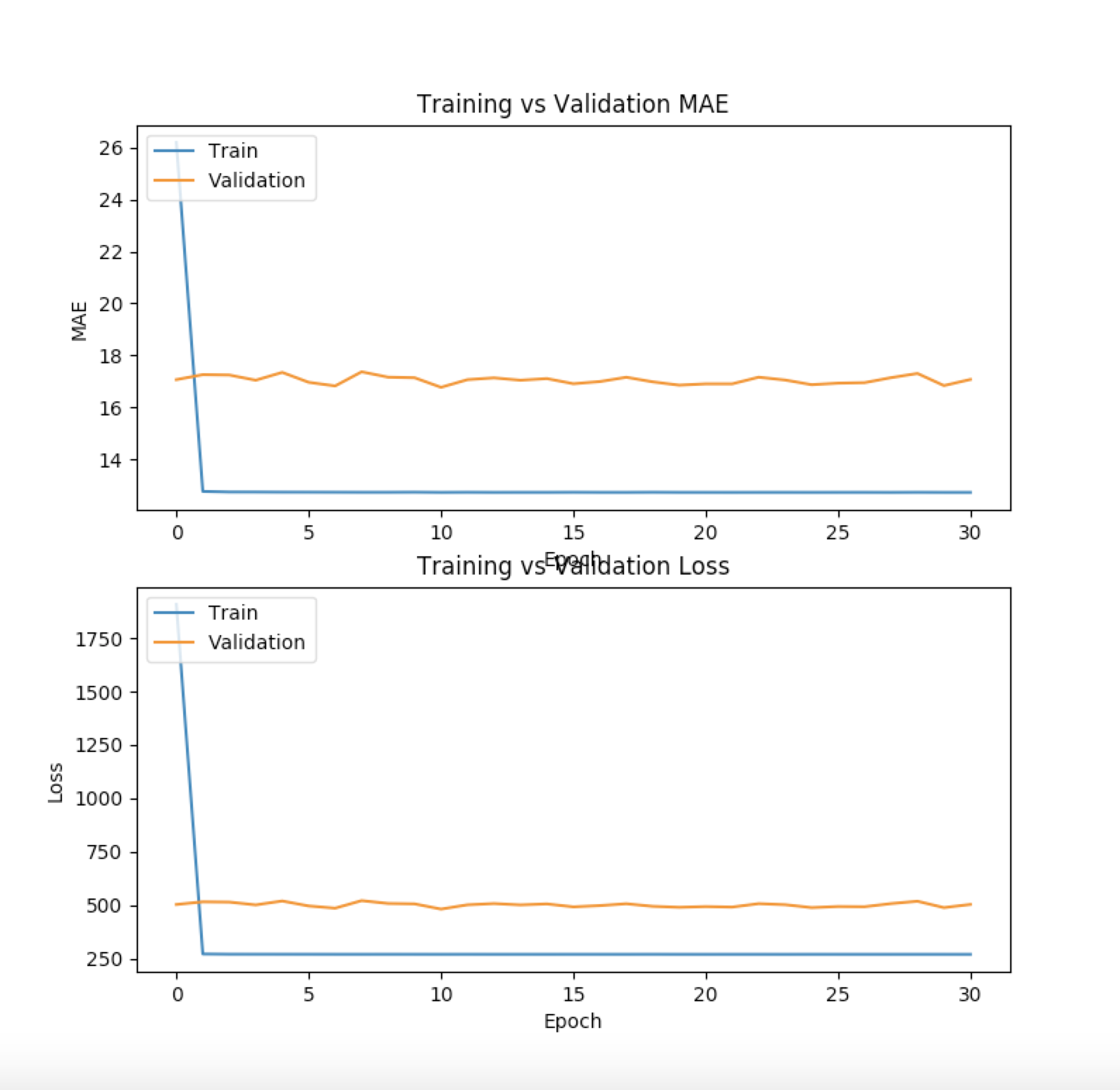
MAE and Loss Over Epochs


Inspiration
We are all interested in the potential and power of machine learning, and the fact that this challenge additionally incorporated elements of public good only added to the appeal. Further, as a biomedical engineering student, Rounak was particularly drawn to the health insurance aspect of the challenge, while Raymond and Nahum (both of whom are computer science students) were deeply interested by the data sets and potential UI designs.
What it does
Our web app provides a user-friendly interface through which prospective health insurance buyers can get highly reliable quotes through their browser by submitting their information to a cloud-based machine-learning model.
How we built it
We trained a machine learning model with over 130,000 randomly sampled ViTech data points, each of which represented a health insurance policyholder. Using Python Requests, we sampled data points from the "v_participants_detail" field, and used the IDs provided there to query the corresponding "v_participants" and "v_quotes."
We parsed these data points into a CSV to contain information about:
- age
- gender
- height
- weight
- location
- employment status
- annual income
- marriage
- usage of tobacco
- preconditions
- number of people covered
- additional coverage
- premiums for bronze, silver, gold, platinum plans
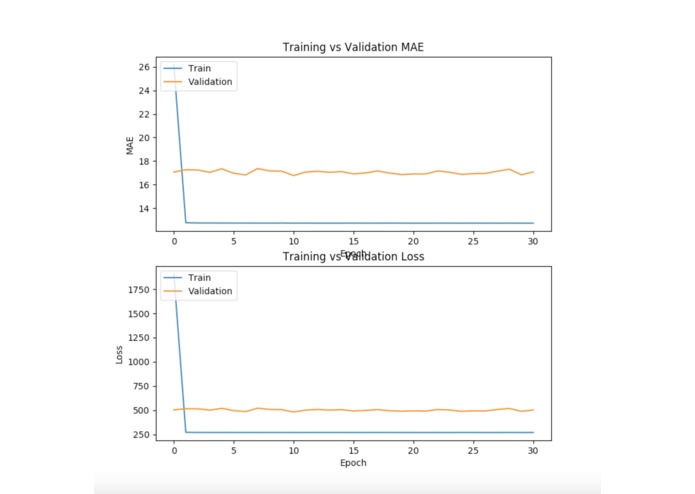
We used a three-layered Keras neural network to train our model to predict premium costs based on each policyholder's features (such as age, gender, etc.). Roughly 70,000 of the data points were used as training data, while the remaining 60,000 were used for validation.
We used React.js to create the form through which each prospective policyholder would submit their information. In addition, in order to incorporate our Google Cloud Machine Learning model, we created a Flask application API endpoint to access the API. We deployed the app using Heroku.
Challenges we ran into
We had issues with the Google Cloud backend, as the current documentation only provides Python implementation. Thus, because our project was primarily created in JavaScript, we created a separate Flask application API endpoint through which we could access the Google Cloud ML API. It was then necessary to configure the CORS settings for both the JavaScript and Python code. In addition, it was initially difficult to query the data and to parse our large datasets. Fine-tuning our machine learning model was a cryptic challenge, as none of our team members had ever had experience with such APIs before.
Accomplishments that we're proud of
In a short time, we were able to create and deploy a Google Cloud-based machine learning model. We generated an robust, styled, responsive application by using an incredibly diverse array of developmental tools, and all garnered a strong initial comprehension of machine learning. Finally, we all deepened our technical competency in creating data-rich applications.
What we learned
machine learning, CORS, Flask, data parsing, Google Cloud API
What's next for yhack2k17
We would like to further refine our neural network by running it on far more data and testing different network configurations. In addition, it will be incredibly useful and informative to create interactive data visualizations of the insurance policy information. To improve the user experience, we would like to streamline the "latitude" and "longitude" form inputs to instead query the Google Maps API for geocoding of one's address.




Log in or sign up for Devpost to join the conversation.