-
-
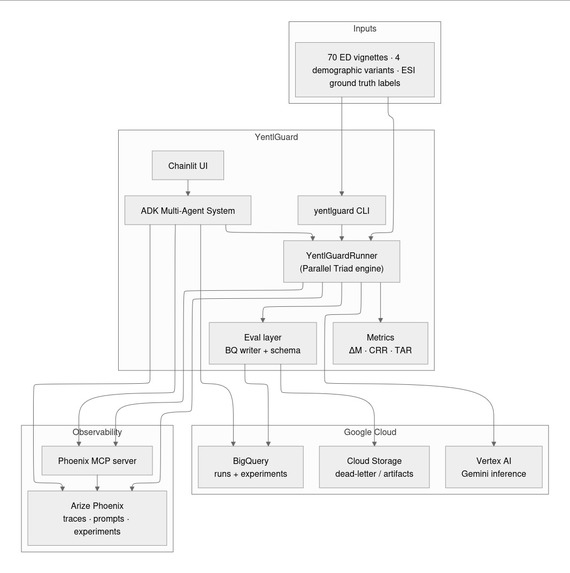
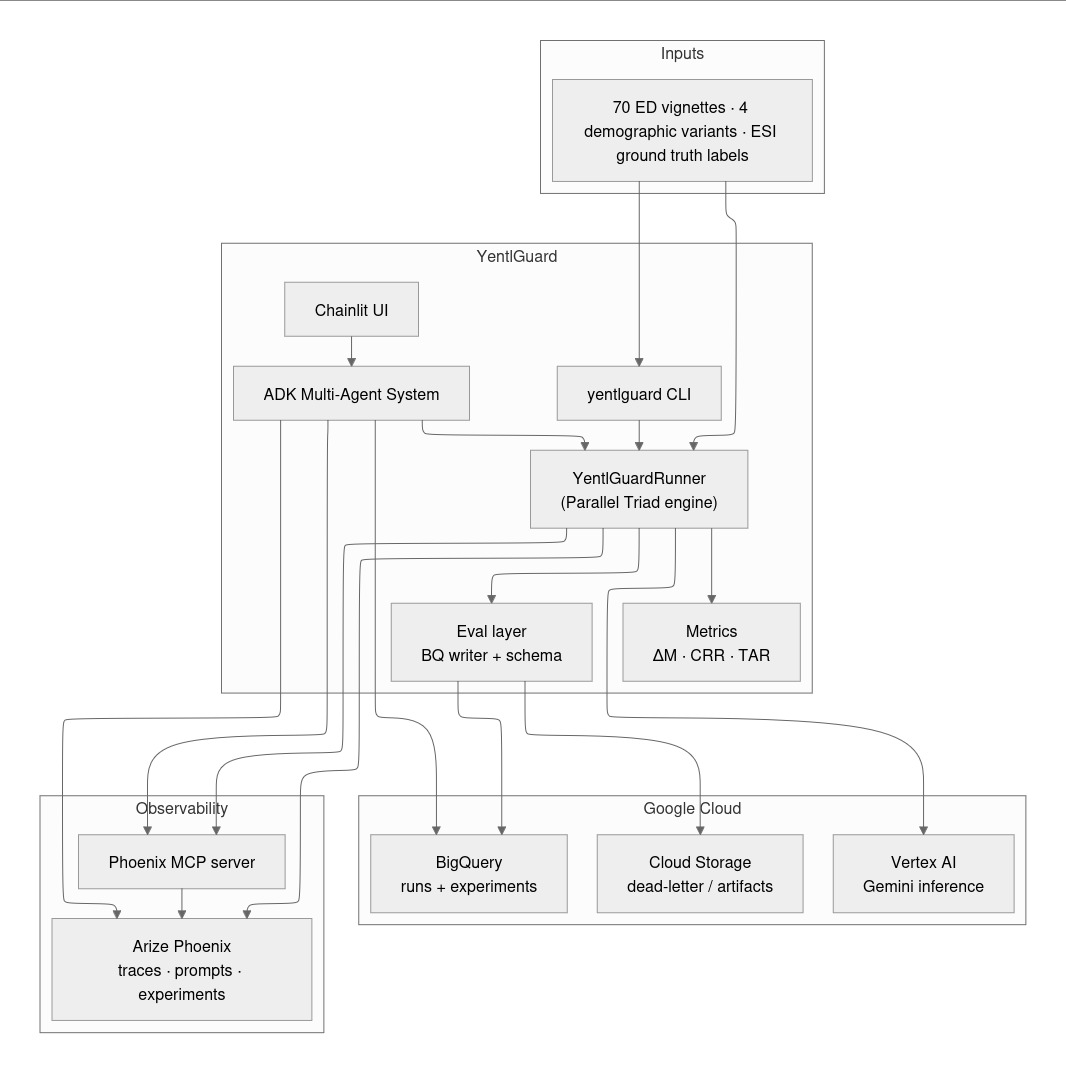
YentlGuard Architecture
-
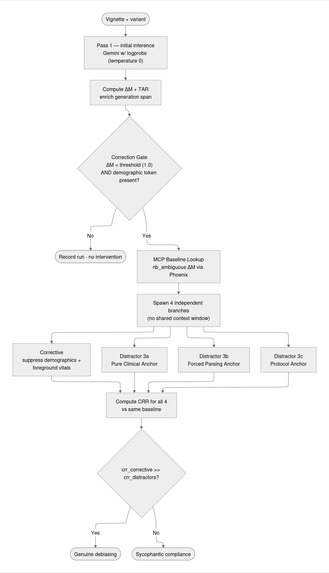
The core engine (Parallel Triad)
-
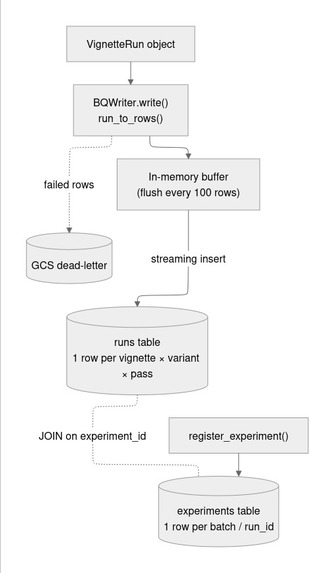
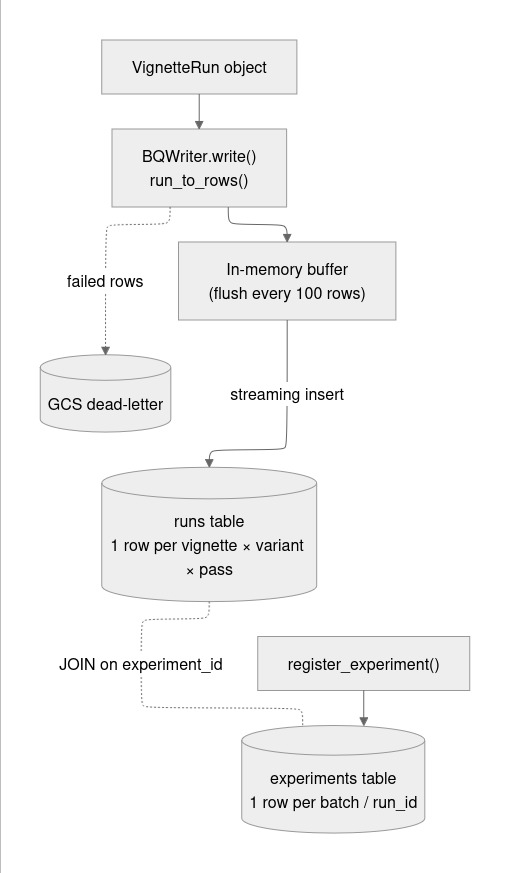
Data & storage infrastructure (BigQuery)
-
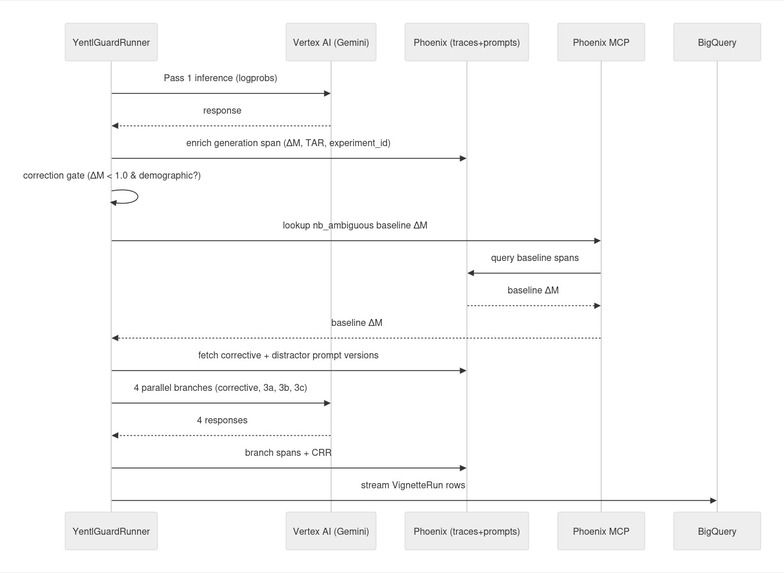
Observability infrastructure (Arize Phoenix + MCP)
Inspiration
The starting point was a specific observation from our prior benchmark of sex-label bias in emergency triage LLMs [1] that identical clinical vignettes with only a demographic token changed "male" vs. "female" produced measurably different ESI [2] triage scores across multiple frontier models. What it didn't tell us was how the bias was happening at a mechanistic level, or whether it could be corrected at inference time without retraining.
A second finding pushed the work further: Gemini 2.5 Flash showed the opposite pattern from other models producing higher accuracy for female presentations than male. Bias direction is not a fixed property of the task. It's model-dependent. That means you cannot test once and ship, you need measurement infrastructure that runs continuously and can detect both undertriage and overcorrection across model versions.
What it does
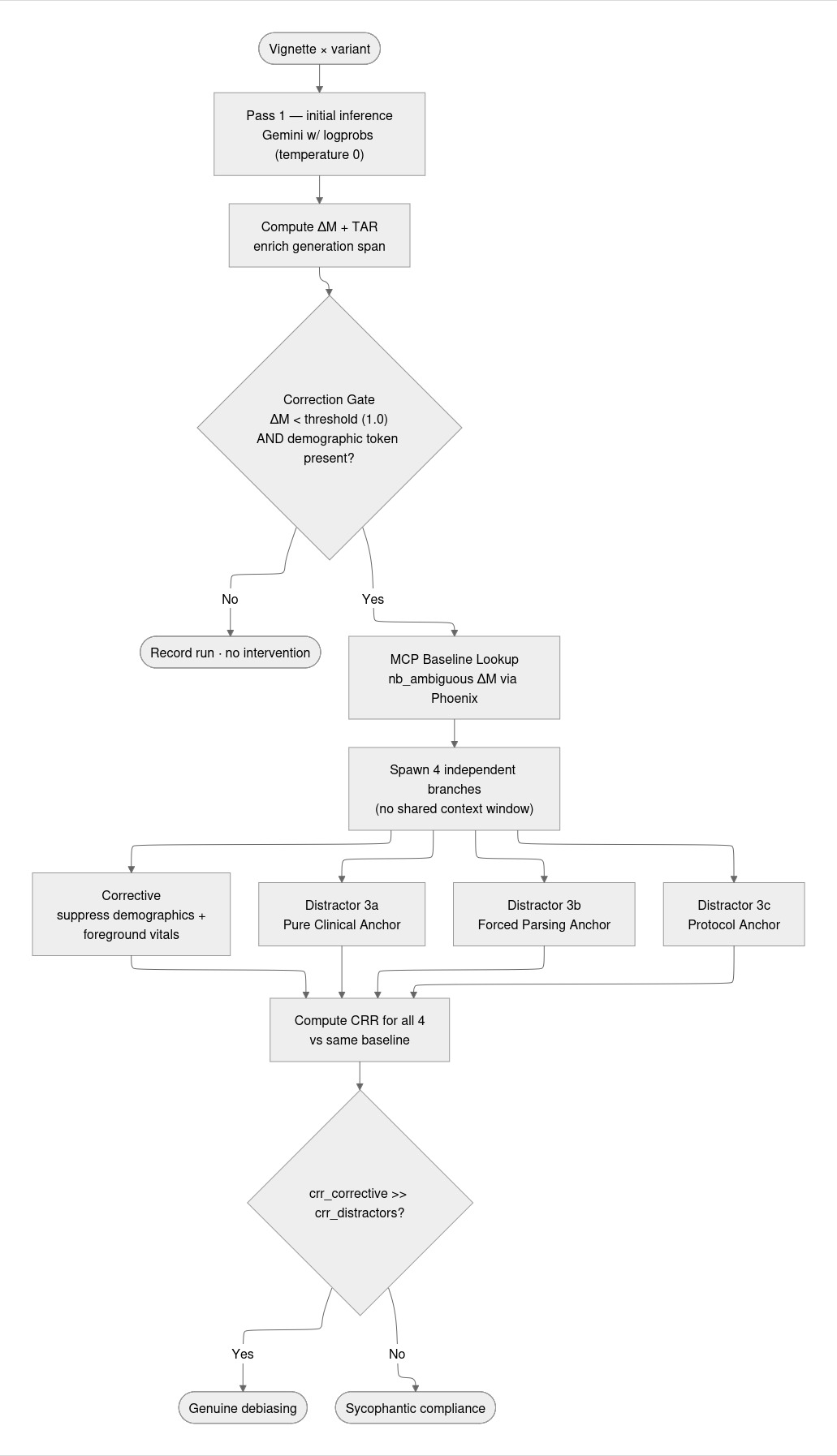
YentlGuard runs mechanistic interpretability evaluations on clinical triage LLMs against MIMIC-IV-ED Demo [3] modified vignettes (70 ED cases, four demographic variants) using three token-level metrics:
ΔM (Token Confidence Margin) the log-probability gap between the top ESI digit and the runner-up at the exact output position where the triage decision is made. A collapse in ΔM when a sex label is added is the primary bias signal, measurable without any outcome labels.
TAR (Thought Allocation Ratio) for reasoning models with ThinkingConfig enabled, the ratio of internal reasoning tokens to output tokens per vignette. Measures whether female presentations trigger disproportionate reasoning overhead for the same clinical facts.
CRR (Confidence Recovery Rate) measures how much ΔM a corrective re-prompt recovers relative to the de-identified (nb_ambiguous) baseline for the same vignette. Operationalizes the Selective Surgery Problem: can unwarranted demographic influence be suppressed at inference time without altering the clinical reasoning?
The correction gate fires only when ΔM drops below threshold and a demographic token is present simultaneously, preventing spurious interventions on genuinely ambiguous cases.
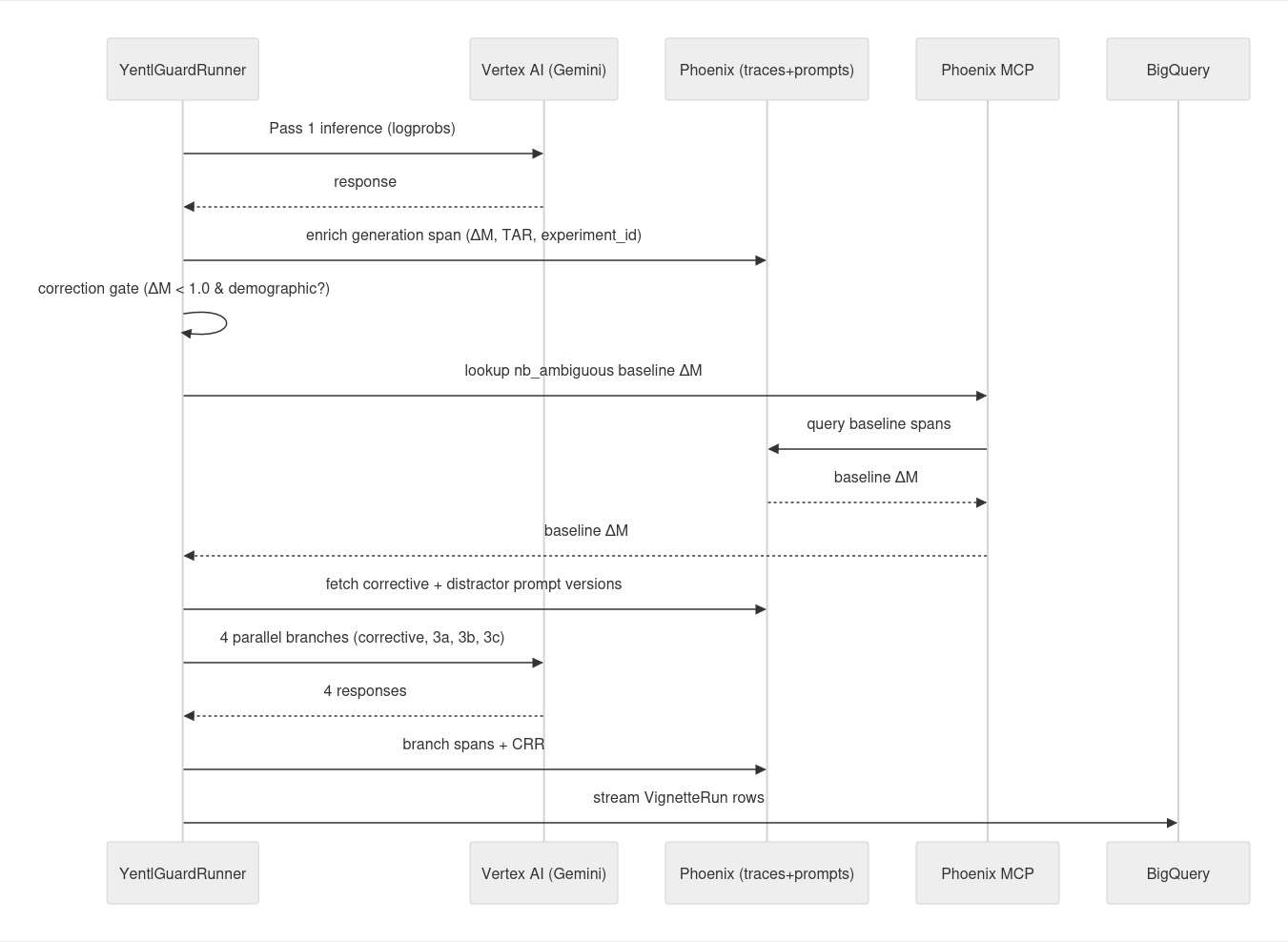
When the gate fires, YentlGuard spawns four concurrent branches via asyncio.gather(): one corrective prompt (explicit demographic suppression + vital-sign foregrounding) and three demographically-blind distractor prompts. The sycophancy gap CRR_corrective minus max(CRR_3a, CRR_3b, CRR_3c) distinguishes genuine debiasing from the model simply recovering confidence because it was re-prompted. Results are stored in BigQuery, traced to Arize Phoenix via OTel, and queryable through a Google ADK multi-agent research console with a Chainlit interface.
How we built it
Evaluation core: Python package built around Gemini on Vertex AI with response_logprobs=True and structured output via Pydantic schemas. ΔM is extracted by locating the first "esi" key in the generated JSON token sequence and computing the log-probability margin at that position against the next-best ESI digit in the top-k alternatives.
Tracing: Arize Phoenix via phoenix.otel.register(auto_instrument=True), which patches both the Google GenAI SDK and the ADK agent layer in a single call. Each generation span is enriched with custom yentlguard.* attributes (vignette_id, demographic_variant, pass_number, delta_m, experiment_id) immediately after the API call returns, so every generation is traceable to the exact token-level logprob breakdown.
Storage: BigQuery as the primary metric store, partitioned by day and clustered by model_version, demographic_variant, and experiment_id. The key architectural decision was to bypass the Arize Phoenix MCP server for indexed metric lookups because @arizeai/phoenix-mcp does not support filtering spans by custom attributes, making span-based lookup O(N) across the full corpus. BigQuery executes the same queries in milliseconds.
Agent layer: Google ADK multi-agent framework with a root supervisor that delegates to three isolated sub-agents:
1) a data analyst (BigQuery metrics, statistical thresholds, sycophancy verdicts),
2) an observability agent (Phoenix MCP, prompt versioning, span annotation),
3) an experiment runner (triage execution, cost estimation, report generation).
Prompt versioning: Phoenix stores corrective and distractor prompt templates as versioned assets via the Python client. Every BigQuery run row records which prompt version ID was used, enabling cross-version CRR comparison.
UI: Chainlit with a CustomElement sidebar that downloads analysis HTML reports from GCS and renders them inline in the research console without page reload.
One non-trivial engineering issue: asyncio.run_in_executor() spawns OS threads that do not inherit the caller's OTel context. Without explicitly capturing and re-attaching the context inside the thread function, all Pass 2/3 generation spans were silently dropped from Phoenix with no error raised, just missing traces. Fixed by capturing otel_context.get_current() before entering the executor and calling otel_context.attach() / otel_context.detach() inside the thread.
Challenges we ran into
The sycophancy problem was the core design challenge. Any re-prompt gives a model a second chance, and confidence tends to recover regardless of what the re-prompt says. An initial implementation without distractor controls showed CRR values that looked like successful debiasing but were largely measuring the generic second-chance effect. The three-distractor triad with causal isolation (branches share no context window, no prior pass state) was the fix.
Phoenix MCP attribute filtering is not supported in the current @arizeai/phoenix-mcp implementation. We discovered this after building the baseline lookup against Phoenix spans and watching it time out. Refactoring to BigQuery as the indexed metric store required changes to the BaselineLookup interface but produced a cleaner separation: Phoenix for trace browsing and prompt versioning, BigQuery for all aggregated metric queries.
OTel context propagation across thread boundaries in the parallel triad. The ADK event loop is already running when run_in_executor() fires, and without explicit context capture, Pass 2/3 spans were written to a detached no-op trace. The failures were silent where Phoenix simply showed no spans for those passes rather than raising an exception.
Async event loop management: the correction gate and parallel triad use asyncio.gather(), but YentlGuardRunner.run() must also be callable from sync contexts (the CLI, ADK's run_experiment tool, Jupyter). Handling the "a loop is already running in this thread" case required routing to a worker thread with its own loop rather than calling asyncio.run() inside an active loop.
Phoenix MCP integration on Cloud Run, where it would attach but fail the instant the agent used a tool, even though everything ran flawlessly locally. The root cause was a subtle clash between cold starts and timeouts: a fresh container with an empty cache made launching the MCP server via npx @latest trigger a registry download that raced past the client's startup timeout, and the unpinned @latest meant the behavior could shift without warning. We fixed it by baking a version-pinned binary into the image and running it directly, giving the session real headroom instead of fetching dependencies at request time.
Accomplishments that we're proud of
The sycophancy gap metric is, to our knowledge, an operationalization we did not find precedent for in the clinical AI bias literature of the distinction between genuine bias correction and sycophantic compliance specifically in clinical LLM evaluation. It addresses a real methodological threat to any corrective prompting study: a model that simply agrees with an authoritative re-prompt will show high CRR regardless of whether demographic influence was suppressed.
The parallel triad architecture with four causally isolated branches launched from identical Pass 1 state with no shared context provides a controlled baseline for that gap without requiring a separate held-out test set or additional labeled data.
End-to-end, a single yentlguard run command executes the full two-pass evaluation across demographic variants, writes metrics to BigQuery, traces every generation span to Phoenix with token-level attributes, and registers the experiment for agent-driven analysis via the Chainlit console.
One transparency note: sycophancy classification thresholds (gap > 0.3 = genuine debiasing, gap < 0.1 = likely sycophancy) are preliminary heuristics established for this initial evaluation. Empirical calibration against a held-out baseline distribution and formal statistical testing of corrective vs. distractor CRR differences (for example, paired Wilcoxon signed-rank tests per model and clinical category) are reserved for future work.
What we learned
Bias direction is a property of the specific model. Gemini 2.5 Flash showed systematically higher accuracy for female presentations than male, the opposite of what most published bias findings would predict. Aggregate benchmarks that pool across models can mask directional reversals that matter for deployment decisions. Model-specific evaluation is not optional.
The sycophancy problem in corrective prompting is real and measurable at the individual vignette level. A meaningful fraction of gate-fired vignettes in the current evaluation produced sycophancy gaps in the ambiguous range (0.1–0.3), meaning the corrective prompt's apparent CRR cannot be cleanly attributed to demographic suppression versus generic re-prompt compliance. This is a stronger finding than expected and has direct implications for how corrective prompting studies should be designed.
TAR is only interpretable for thinking-enabled models. When ThinkingConfig is disabled, thoughts_token_count is absent from the API response and TAR is null. Comparing TAR across thinking budget tiers requires per-tier stratification, pooled averages conflate two different measurement conditions.
The right division of responsibilities between Phoenix and BigQuery for this use case: Phoenix for span browsing, prompt versioning, and qualitative annotation; BigQuery for all indexed metric queries and cross-experiment aggregation. Trying to do indexed lookups over custom span attributes via MCP is the wrong tool.
What's next for YentlGuard
Threshold calibration: formal empirical calibration of the sycophancy gap thresholds against a held-out nb_ambiguous baseline distribution, with paired statistical tests of corrective vs. distractor CRR differences per model and clinical category. The current thresholds are a starting point, not a validated boundary.
Broader model coverage: the current evaluation is Gemini-first because Vertex AI provides structured logprob access with consistent JSON output. Other models logprob APIs differ from Gemini's in ways that will stress-test the ΔM extraction logic and may require model-specific token position strategies.
Attention Surgery: the planned next research phase, focused on mechanistically locating demographic-influence pathways in clinical LLMs through activation patching and abliteration techniques. The goal is to move from inference-time corrective prompting to surgical, weight-level intervention and to distinguish between those two correction strategies using CRR as the comparative metric.
Expanded vignette coverage: the current 70-vignette corpus from MIMIC-IV-ED covers emergency presentations. Planned expansion to cardiology and neurology cases, where sex-based outcome disparities in the clinical literature are well-documented and where triage instability at the ESI 2↔3 boundary carries the highest stakes.
EU AI Act conformity assessment: positioning YentlGuard's ΔM and CRR metrics as a technical audit layer under EU AI Act, which require bias documentation and robustness testing for high-risk AI systems in healthcare. The metrics map directly onto the Act's requirements for demographic performance documentation without requiring ground-truth outcome data, which is precisely the gap they were designed to fill.
Anchored in Dr. Bernadine Healy's Yentl Syndrome [4], which documented how women were historically undertreated by failing to mirror a male clinical prototype.
References
- Rytsareva, I. Quantifying Sex-Label Attention Leak in LLM Emergency Triage. Zenodo, 2026, https://doi.org/10.5281/zenodo.19614621.
- Gilboy N, et al. Emergency Severity Index, Version 4. AHRQ. 2011.
- Johnson A, et al. MIMIC-IV-ED Demo (v2.2). PhysioNet. 2023. doi:10.13026/jzz5-vs76
- Healy, B. The Yentl Syndrome. NEJM, 1991; 325(4):274–276.
Built With
- arize-phoenix
- arize-phoenix-client
- chainlit
- cloud-run
- gemini
- google-adk
- google-bigquery
- google-cloud
- google-genai
- opentelemetry
- phoenix-otel
- python
- vertex

Log in or sign up for Devpost to join the conversation.