Inspiration
Our inspiration for this project stemmed from the need to optimize productivity in various settings such as lectures, meetings, and brainstorming sessions. We wanted to create a tool that could seamlessly capture spoken content and transform it into structured, visual data, allowing users to easily grasp the relationships between different concepts discussed. In an era where time management is crucial, having a tool that can provide immediate insights from spoken words is invaluable.
What it does
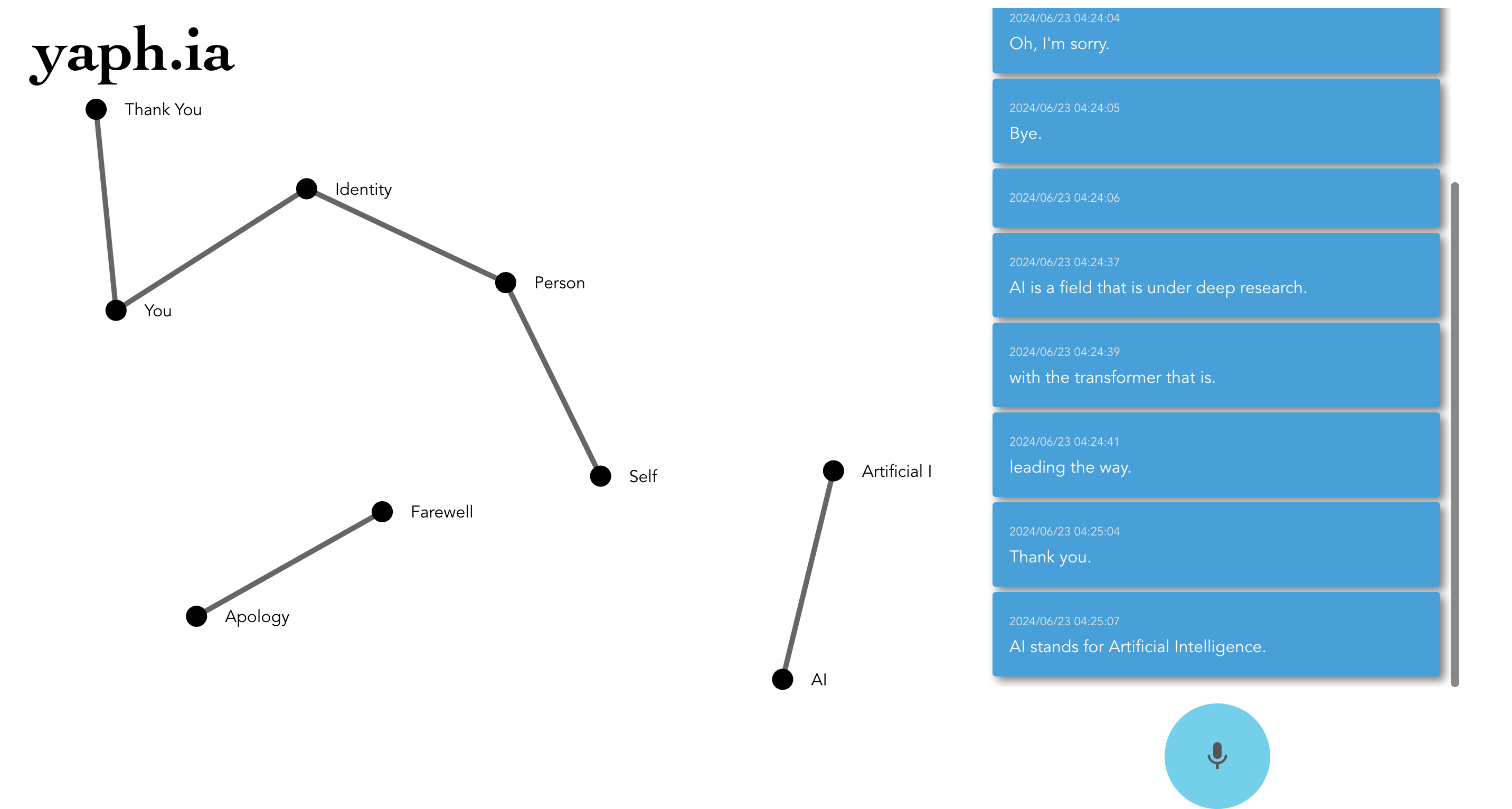
The tool is a real-time speech-to-graph productivity application that listens to speech and converts it into text using OpenAI's Whisper. This text is then fed into GPT-4, which generates an adjacency list representing the relationships between important concepts discussed. This adjacency list is displayed on a React frontend using D3.js, showing nodes and links annotated with concise information. The tool provides a comprehensive understanding of how all discussed elements are interconnected, making it extremely useful for capturing and analyzing the flow of ideas in various scenarios.
How we built it
We built the tool by integrating several cutting-edge technologies:
OpenAI Whisper for real-time speech-to-text conversion. GPT-4 for processing the transcribed text and generating an adjacency list of concepts and their relationships. D3.js for creating a dynamic and interactive visualization of the concepts and their links. Next.js for the frontend and backend framework, enabling a responsive and user-friendly interface. LangChain to streamline the integration between different APIs and manage data flow.
Challenges we ran into
One of the main challenges was getting the physics of D3.js to work correctly. The nodes and links often went off-screen, making the graph hard to navigate and interpret. Another significant challenge was fine-tuning the GPT-4 prompt to accurately extract important concepts without introducing too much noise, which required careful balancing and numerous iterations.
Accomplishments that we're proud of
We are proud of creating a tool that has the potential to significantly enhance productivity and comprehension in various contexts. The integration of speech-to-text, AI-driven concept extraction, and interactive visualization is a complex task, and successfully bringing these components together into a functional and useful tool is a major achievement. Additionally, the tool's ability to provide real-time insights and a clear visual representation of spoken content is something we are particularly proud of.
What we learned
Through this project, we gained valuable experience in:
- Integrating the OpenAI API and leveraging its capabilities for speech-to-text and text analysis.
- Working with OpenAI's Whisper for accurate and real-time transcription.
- Utilizing LangChain to handle API interactions and data management.
- Building interactive visualizations with D3.js and addressing the challenges associated with graph rendering.
- Enhancing our skills in prompt engineering to fine-tune AI responses for specific use cases.
What's next for yaph.ia
We plan to take this project further by reducing the latency of speech transcription to improve real-time performance and refining the prompt engineering process to ensure even more accurate extraction of important concepts. Additionally, we aim to add user-friendly features such as bookkeeping graphs via authentication, allowing users to save and manage their visualizations. Another key enhancement will be implementing a feature to highlight corresponding transcribed text when nodes are hovered over, providing a seamless way to navigate between the graph and the original speech content. Lastly, we will continuously improve the user interface to make the tool more intuitive and accessible for a wider audience.
Built With
- langchain
- next.js
- openai

Log in or sign up for Devpost to join the conversation.