-

"They called me a Mad Man", source: https://youtu.be/fzGBRDpf5GU?t=102
-

"Metaverse", source: https://youtu.be/pjNI9K1D_xo?t=6
-
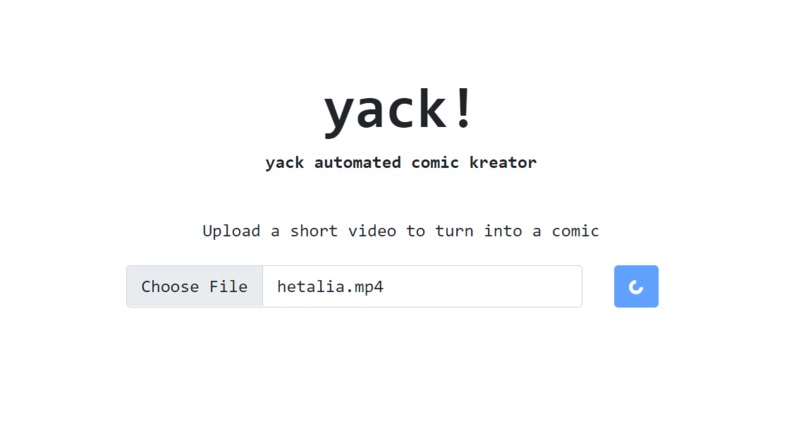
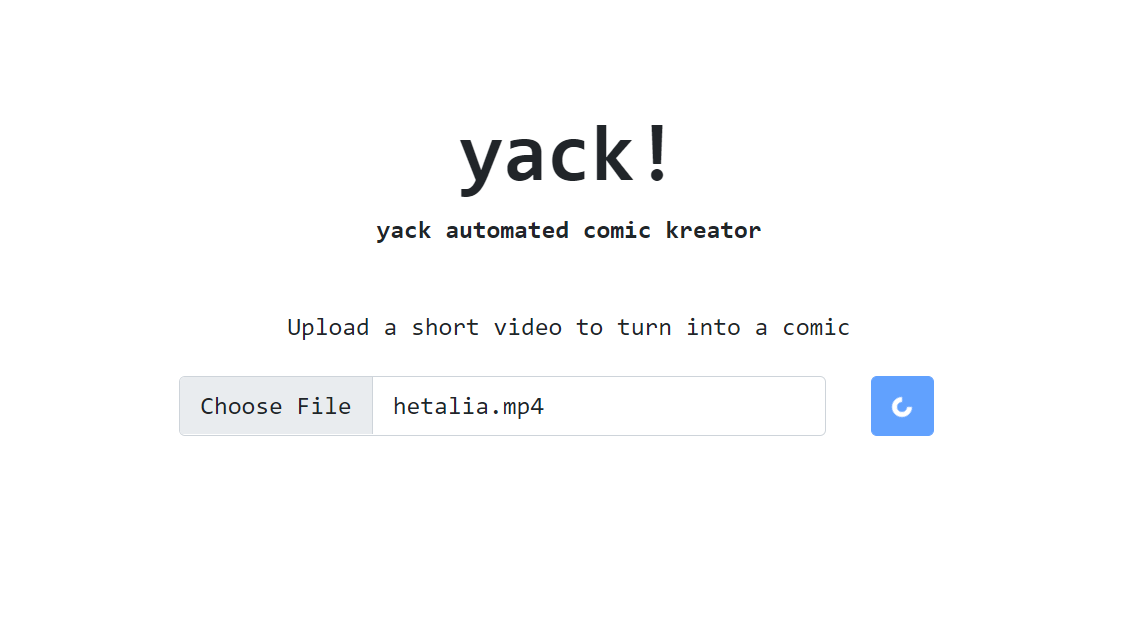
User interface (https://yack-qv3vu2mzpa-nw.a.run.app/)


Inspiration
Memes and manga. The Deepgram API being cool and easy to work with was also a big part of why we went with this idea.
What it does
Takes a video and analyses the audio, splitting the footage based on what is being said and who is saying it. Keyframes are found and transformed to resemble a comic book style, while computer vision is used to identify the active speaker and their location in the scene, to add speech bubbles correctly assigned to each speaker relaying the dialogue.
How we built it
We split the task into various components, which we then integrated into a complete pipeline. We then added a website for users to interact with and used Docker to create a portable, scalable and easily deployable server.
Challenges we ran into
- Dealing with the OpenCV vs NumPy coordinate systems between developers was quite difficult (they have different order of axes).
- Cross-platform development caused some issues (we were working with Windows, Linux and Apple).
- Placement for textboxes to avoid covering subjects of the scene was also not trivial.
- Layout algorithms are quite complicated.
Accomplishments that we're proud of
- We really like our processing pipeline.
- Facial detection works surprisingly well.
- The actual output comics actually made us laugh a few times.
What we learned
We got some good experience in development for reproducible builds across different systems. We also improved our abilities in write maintainable code through planning our structure together before starting development to ensure easier integration.
What's next for yack!
We want to replace the current styling to create the comic effect with a Style Trasfer GAN. We will also look into using Kubernetes for load balancing.
Built With
- deepgram
- dlib
- ffmpeg
- flask
- javascript
- opencv
- python











Log in or sign up for Devpost to join the conversation.