-

-
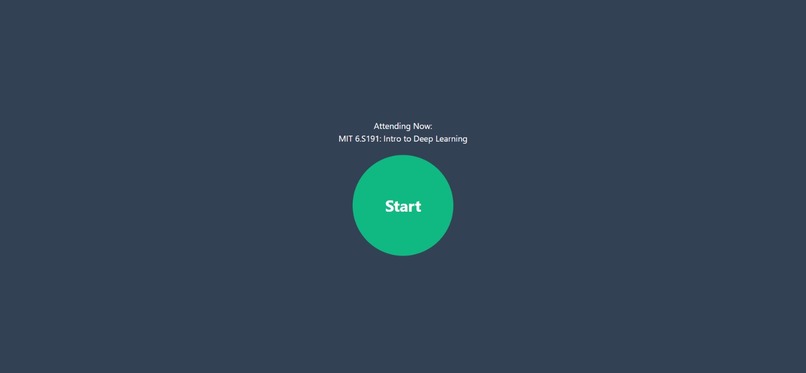
Classroom mode
-
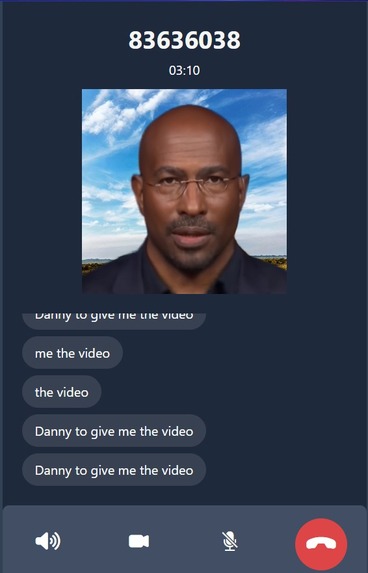
Transcript and lip sync on phone
-
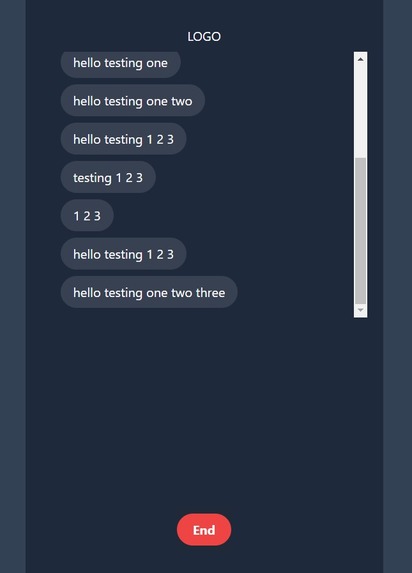
classroom transcript

Inspiration
As a group, we wanted to leverage our knowledge in Machine Learning and AI to be able to help persons with disabilities achieve a better lifestyle and be a part of mainstream society.
What it does
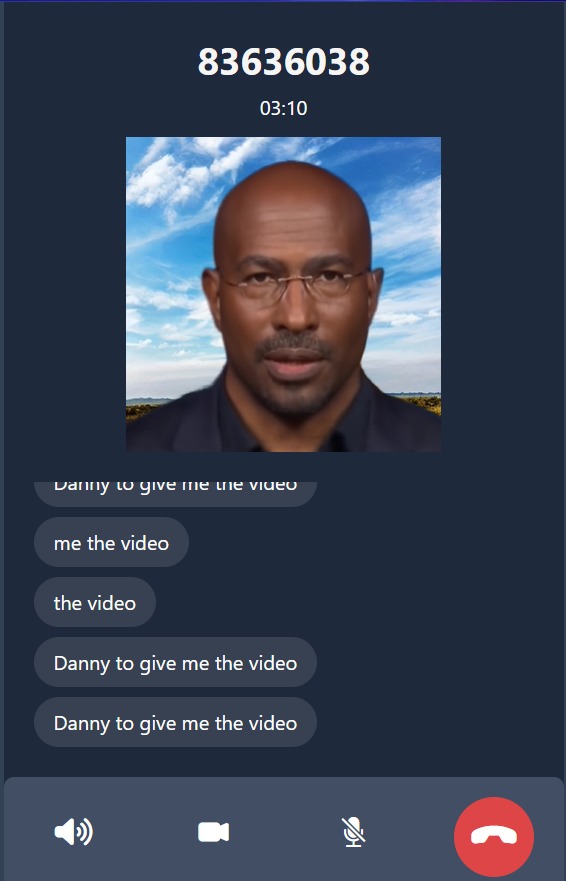
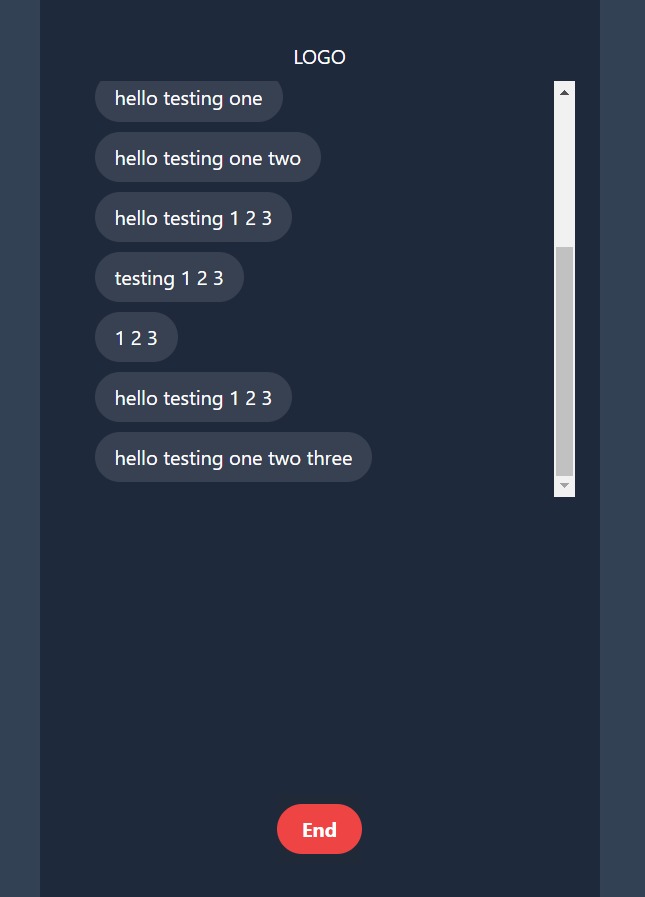
Xpress call generates a real-time talking portrait with accurate lip movements that mimic the person that is being recorded. We created 2 use-cases as web applications, 1 which is a WhatsApp call interface and the other is a classroom call. For the WhatsApp call, when both persons are connected to the call, the application will start recording the talking person's audio, and outputs a live transcript as well as a generic avatar with lip movements that will be similar to the speaker. The use-case is for when a hearing-impaired person is on a voice call, he/she still can read the lips of the speaker without the actual speaker being on the call The classroom call also works the same as the WhatsApp call, a useful scenario for this use-case is that when in a large lecture theatre where the speaker's lip movements cannot be seen clearly, persons with impaired-hearing can make use if this application to read the lips of the speaker from their device.
How we built it
The real-time talking portrait is generated using a novel framework called Real-time Audio-spatial Decomposed Neural Radiance Field (RAD-NeRF). This is a deep learning model that converts audio data into head and lip movements. The model we used is from a GitHub repository that contains the PyTorch reimplementation of the research paper. When using the web application, the audio of the talking person will be recorded and passed into the model that is on the back-end server, and the output which is the talking portrait will be shown on the call interface. The real time transcription is generated using p5.js with the same audio recording. The web application is built using tailwindcss, and we used JavaScript as well as Flask for the back-end
Challenges we ran into
A challenge that we ran into is converting the audio files from .blob filetype generated on the client side to a .wav filetype which is the required filetype to be passed into the model, which we eventually managed to solve. Another challenge is trying to host the application on the cloud and getting it to work seamlessly, as we have limited time and little experience in hosting on the cloud.
Accomplishments that we're proud of
To be able to ideate and build a working prototype within just 24 hours is a challenge for all of us and to be able to complete it is an achievement for us.
What we learned
Through this hackathon, we were able to learn more about the novel RAD-NeRF model, we also learnt more about server-side development and cloud hosting.
What's next for Xpress Call
The eventual idea is to improve the accuracy of the lip movements of the RAD-NeRF model and also for users to be able to use their own facial portraits for the talking portrait, and for it to be a Business-to-Business service, where we sell our software to other companies to allow them to integrate our software.
Built With
- ai
- deep
- flask
- github
- javascript
- machine-learning
- ml
- socket
- socket.io

Log in or sign up for Devpost to join the conversation.