-
-
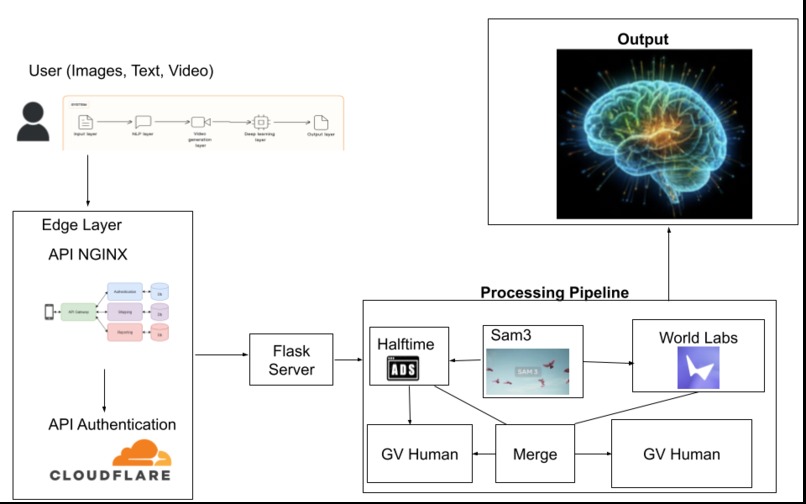
System Design
-

Environment

Inspiration
Video ads today are either generic interruptions that disrupt immersion, or expensive, manual product placements that don’t scale. We wanted to build an artificial intelligence that would transform static information into customizable, personalized visual environments: given a video + transcript + a brand goal, our system can pick the right moment to place something, generate the asset during a tight time window, and optionally hand off the cleaned scene into a video-to-world pipeline (World Labs) so the same content can become an interactive 3D environment.
What it does
Xperience is an API that transforms visual media (images, videos, etc) into personalized curated 3D simulations. Users upload a video, subtitles, and a natural language prompt that describes how they want the experience modified. The system analyzes the content, identifies relevant moments using vector search, and generates a structured 3D simulation centered around the most meaningful segments. The API manages the full generation lifecycle, including media processing, AI-based modification, and artifact retrieval. Each request creates a job that can be tracked through clear status updates, and the final simulation can be retrieved through dedicated endpoints. All workflows are handled through a stateful, versioned API designed for predictable integration and scalable deployment.
How we built it
3D generation & hosted inference
fal.ai (fal_client): Used to run Hunyuan3D v3 image-to-3D from extracted frames (multi-view inputs) and download GLB outputs.
Tripo3D API (Native v2): Upload frame → generate 3D model → rig/idle animation preset → download GLB.
Motion extraction / animation input
Move.ai: Used for motion extraction (outputs an animated FBX / skeleton+motion that your pipeline then consumes).
External provider APIs used by the backend
Luma API: Video-to-video edit (submits modify jobs, polls status, downloads edited mp4).
World Labs API: World generation (async operation pattern; outputs world artifacts like .spz).
Kie.ai “Nano Banana” API: Background cleaning / generating a “clean” background image from an input frame.
Backend API (what the server is built on)
Flask (Python): REST API server (routes like POST /api/v1/jobs, GET /api/v1/jobs/{id}, downloads, public provider-fetch routes).
Gunicorn: Production WSGI server for running Flask in deployment.
python-dotenv: Loads .env config locally (provider choice, keys, storage backend, etc.).
requests: HTTP client used for calling external provider APIs from the backend.
OpenAPI 3.1 YAML (contracts/openapi.yaml): The API contract/spec.
Spectral (Stoplight) + Node.js 20: Lints the OpenAPI spec in GitHub Actions CI.
We used Actian Vector Database as the vector database for embeddings and similarity search, powering a RAG (Retrieval-Augmented Generation) flow where we store vectors, retrieve the most relevant chunks, and feed that context into generation. The vector service is hosted behind Cloudflare (Cloudflare as the deployment edge/routing layer), and we use SQLite on Cloudflare to persist user inputs and metadata.
Challenges we ran into
Designing the job schema required balancing simplicity with flexibility, especially when tracking asynchronous states and artifact locations. We had to ensure job metadata remained consistent across both local and S3-backed storage modes. It was also difficult to manage structured metadata without introducing race conditions during state updates. Handling real-time job updates without confusing the user required careful state management. It was also complex to manage file uploads and reflect asynchronous processing states clearly in the UI. Designing a contract-first API while integrating external AI providers required careful abstraction. Managing multipart uploads and asynchronous job processing introduced complexity. Switching between mock and real providers without breaking the API surface required clean architectural separation. Translating conceptual memory reconstruction into meaningful visual output required experimentation with scene structure and rendering workflows. Ensuring generated experiences felt immersive without overwhelming the system was technically demanding. It was also a challenge to balance realism with performance constraints.
Accomplishments that we're proud of
We successfully designed a job metadata system that tracks lifecycle states and output locations cleanly. The database structure supports both development and production-lite deployments. Our persistence model allows consistent job retrieval and artifact management through simple API calls. We built a clean, intuitive interface that allows users to upload media, track job progress, and download outputs easily. The frontend clearly reflects backend state transitions. The system works smoothly across modern browsers and provides a polished user experience. We built a fully functional, versioned REST API that supports asynchronous AI video generation. The backend cleanly abstracts provider logic and supports environment-based switching. Our system handles uploads, processing, storage, and artifact retrieval through consistent endpoints. We developed customizable visual experiences that enhance the generated video output. The 3D modeling layer adds depth and personalization to reconstructed memories. It strengthens the immersive quality of the platform while remaining compatible with the API-driven workflow.
What we learned
We learned how important clear state modeling is in asynchronous systems. Structuring metadata early made the API more predictable and easier to debug. We also gained experience handling persistent storage across different environments. We learned how to manage complex state transitions in React while keeping the interface intuitive. Real-time updates reinforced the importance of clear feedback loops in user-facing systems. We also improved our understanding of integrating API-driven workflows into modern frontend frameworks. We learned the value of separating provider logic from the API surface. Explicit job state modeling made debugging and testing much easier. We also gained hands-on experience integrating third-party AI generation services in a predictable way. We gained experience designing visual representations that feel dynamic and emotionally engaging. We learned how rendering decisions impact performance and usability. The process reinforced the importance of aligning visual design with system capabilities.
What's next for XPerience
Next, we should make the OpenAPI specification fully align with the actual server behavior so the contract accurately reflects the current request/response shapes and all live endpoints across Jobs, Semantic, and Bridge. After that, we should move execution to a true asynchronous architecture by introducing a queue and background workers so long-running pipelines don’t block the web process and the system scales cleanly in real deployments. Once the execution layer is solid, we can deepen the semantic pipeline by generating multimodal embeddings that combine information from extracted video frames and the transcript, rather than relying on transcript-only meaning. Finally, we should add persistent personal preference profiles, capturing things like brand likes/dislikes, stylistic constraints, and safety boundaries so the “main character” personalization carries across sessions and consistently shapes generated content over time.





Log in or sign up for Devpost to join the conversation.