Inspiration
Given the upcoming presidential election, we wanted there to be a fun way for people to determine which candidate aligned more with their interests, if they were to throw away all their pre-conceived notions about each candidate. We were interested in using Natural Language Processing and we all love reading xkcd comics, so we decided there was an interesting way we could integrate these two traditionally disparate tasks – reading funny comics vs. reading about presidential candidate election info/platforms.
What it does
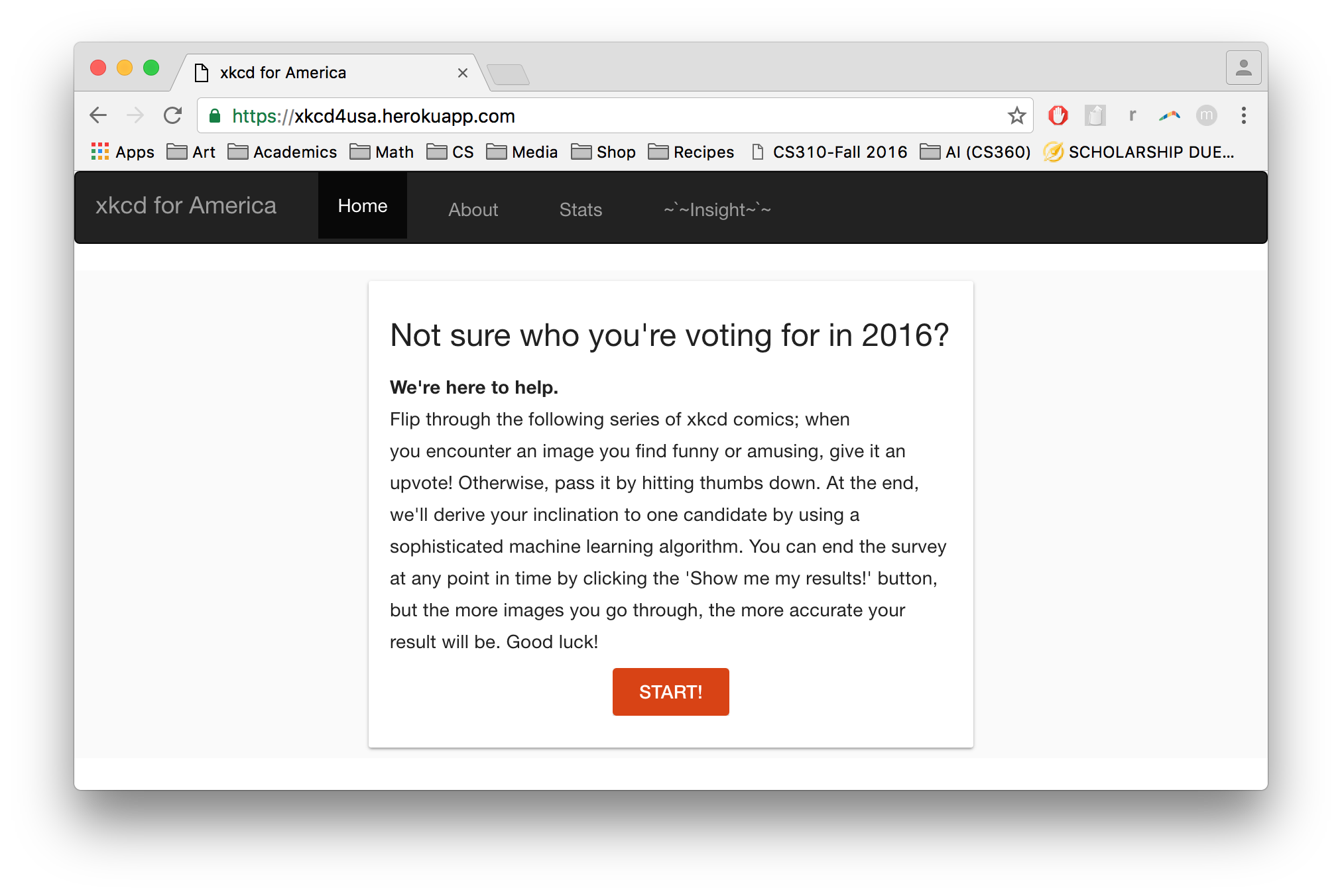
Essentially, we boiled it down to the very basics. Our users visit our site to find what appears to be a very simple quiz. You flip through a series of xkcd comics, and you either upvote it or downvote it to indicate whether you found it interesting/funny. At the end, we determine which candidate you have a closer affinity with and show you the collective data of all the people who've participated!
How we built it
We curated the speeches of Trump and Clinton from their election campaigns, as well as nearly all of Trump's tweets from the last year. From this text corpus, we ran the latent Dirichlet allocation (LDA) algorithm in order to get a collection of 'topics' (Trump topics and Clinton topics) – these topics were then mapped to the most closely corresponding xkcd comics. From there, we built a front-end interface where users could indicate their interest in each xkcd comic, which we tracked the results of to display a diagnosis at the end, regarding whether they displayed more interest in Clinton topics vs Trump topics.
Challenges we ran into
- Finding good, equal sources of data
- Cleaning the data in a way that the LDA algorithm could accept it
- Making sense of the LDA algorithm's results (tendency to give garbage topics)
- Making the bar graph show up with data results
Accomplishments that we're proud of
- It works!!
- We've found a good deal of interested users, originally we weren't sure if people would like it :)
What's next for xkcd For America
We definitely think there's a lot of fun to be had with the data we have and our platform.
- Collecting more user data to make better visualizations and possibly compare with how this measures up to their preconceived candidate preference.
- Comparing the frequency that candidates used of SAT words in their speeches to determine who'd be more likely to attend college in 2016
- And more!


Log in or sign up for Devpost to join the conversation.