-
-
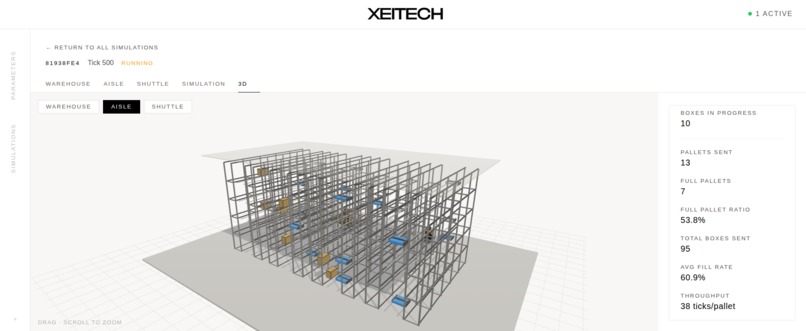
3D demo of a warehouse with multiple constraints.
XEITECH: Intelligent Warehouse Automation
The Problem Worth Solving
Modern automated warehouses management is a complex topic. Boxes arrive at random, get stored wherever and, when a pallet needs filling, the system scrambles. Shuttles race across aisles, robots wait, pallets ship half-empty. The math is simple: every empty slot on a dispatched pallet is money left on the floor.
At HackUPC 2026, we took on the Inditex Tech challenge, a real warehouse simulation problem designed to test how efficiently a fully automated logistics system can be optimised from scratch.
Inditex Tech posed exactly this problem: given a physical warehouse model with constrained shuttles, shared aisles, and a robotic packing arm, build the scheduler that makes it run as fast and as efficiently as possible.
What We Built
XEITECH is a full-stack warehouse simulation platform with a high-performance C++17 optimization engine at its core, a Python/FastAPI streaming backend, and a React frontend for real-time visualization.
The simulation models a physical warehouse: boxes arrive on an input belt at ~1,000/hr, get stored in aisles by shuttles (one per Y-level), and are later retrieved and packed onto 12-box pallets by a robotic arm. Every decision — where to store a box, which box to retrieve next, which destination family to fill — is driven by heuristics that we benchmarked, tuned, and fought over.
Architecture
- C++17 scheduler runs deterministic discrete-event simulation. Sub-millisecond ticks. A three-stage pipeline per tick: Belt feed → Robot tick → Aisle tick. This is where all the interesting logic lives.
- Python / FastAPI wraps C++ via pybind11 bindings, manages simulation lifecycle, and streams events to the frontend over WebSocket with playback speed control (0.5×, 2×, pause/resume). C++ runs in a
ThreadPoolExecutorwithpy::gil_scoped_release— true parallelism, no blocking. - React + Vite frontend for launching simulations and watching the warehouse work in real time.
Critical Architecture Decisions
1. Tick pipeline as a three-stage bus
Every simulation tick is split into Belt → Robot → Aisle. This forces a clean separation of concerns and makes the simulation deterministic and reproducible. Each stage cannot observe side effects from the same tick — no ordering bugs, no hidden coupling.
2. SSTF-inspired shuttle scheduling with aging
Shuttle instruction queues use a disk-scheduling inspired priority formula — the same insight that drives hard-drive head seeking. Wait time, stock bonuses, and seek cost are weighted together. Starvation is prevented via an aging factor that boosts low-priority instructions the longer they wait. Too much aging and the system thrashes; too little and low-priority slots wait forever. Finding the balance was one of our core engineering challenges.
3. Pull scheduling model
Shuttles immediately request their next instruction upon completing a mission. No idle ticks, no polling. The system self-drives. This single decision eliminated nearly all idle time between shuttle missions.
4. Input placement heuristic (findBestInputSlot)
When a box arrives, every free Z=1 slot is scored:
- Ideal X position (close to port)
- Z-level penalty (avoid wasting Z=1 if Z=2 is free)
- Proximity to next expected pickup
- Shuttle load balance
5. Dual-Command output heuristic (findBestBoxForShuttle)
Output retrieval minimises total shuttle travel using:
cost = |shuttle.x − box.x| + |box.x − port.x|
Tiebreaks favour slots where Z=1 is occupied and Z=2 exists (Dual-Command Cycle pattern — one trip, two tasks), and prefer larger X values to consolidate free space near the port.
6. Robot heuristic family — the big tradeoff
The robot is the decision-maker: it picks which destination family to fill next. We benchmarked five heuristics:
| Heuristic | Strategy |
|---|---|
largest_stock |
Always target the family with the most boxes in the silo |
random |
Pick a family uniformly at random |
stock_proximity |
Weight families by stock × proximity to port |
nearest |
Always target the family whose boxes are closest to output |
coop |
(2-robot only) Coordinate to avoid targeting the same family simultaneously |
Benchmark Results
All runs: 1,000 boxes/hr · 4 aisles · 8 shuttles/aisle · 60 slots/shuttle · Pallet capacity = 12
| robots | heuristic | avg ticks / filled pallet | pct filled | avg cap | avg moves / 10³ |
|---|---|---|---|---|---|
| 1 | largest_stock |
72.8 | 1.000 | 1.000 | 69.4 |
| 1 | random |
84.6 | 0.954 | 0.990 | 66.3 |
| 1 | stock_proximity |
127.4 | 0.980 | 0.997 | 52.7 |
| 1 | nearest |
151.2 | 0.933 | 0.977 | 52.4 |
| 2 | largest_stock |
50.5 | 1.000 | 1.000 | 76.3 |
| 2 | random |
83.4 | 0.956 | 0.993 | 67.4 |
| 2 | coop |
96.0 | 0.995 | 0.998 | 59.7 |
| 2 | stock_proximity |
107.4 | 0.995 | 1.000 | 57.2 |
| 2 | nearest |
135.5 | 0.919 | 0.982 | 56.4 |
Primary metric — avg ticks / filled pallet: lower is better. It captures both speed and pallet completeness in one number.
Key Findings
largest_stock dominates throughput. Its simplicity is its strength — committing to the deepest inventory minimises pallet switches and keeps fill rates at a perfect 100%. Adding a second robot drops avg ticks/filled_pal from 72.8 → 50.5 — a 31% speedup with zero additional code complexity.
Proximity-aware heuristics trade speed for energy. stock_proximity and nearest produce roughly 25% fewer shuttle moves than largest_stock. At industrial scale, that means less mechanical wear and lower energy consumption — a real cost difference in a 24/7 operation.
There is no universally optimal heuristic. The right choice depends on your constraint: if throughput is the bottleneck, largest_stock + 2 robots wins unconditionally. If energy cost matters and throughput is not saturated, coop (2 robots) or stock_proximity (1 robot) are worth the tradeoff.
The Brick Walls
Z-axis blocking was our hardest bug. A box placed at Z=1 blocks the box behind it at Z=2. Early builds had shuttles deadlocking themselves — the box they needed was trapped behind another they had just placed. The input heuristic's W4=10 weight emerged from hours of debugging this exact failure mode.
Shuttle instruction priority was a balancing act. Naive FIFO caused starvation under load. Pure distance minimisation ignored stock urgency. The SSTF + aging formula took several iterations to get right.
Parallel simulation correctness. Running multiple simulations concurrently through a single pybind11 binding required careful GIL handling. Missing a single py::gil_scoped_release in one code path caused sporadic deadlocks that were near-impossible to reproduce under normal load.
Heuristic interaction effects. Tuning the robot heuristic in isolation gave misleading results — the input placement and output retrieval heuristics interact in non-obvious ways. A configuration that looked optimal with a random input heuristic degraded badly once the smarter one was enabled. We had to benchmark combinations, not individual heuristics.
Conclusions
We built a modular, benchmarkable simulation engine from first principles in under 48 hours. The clearest lesson: the robot's family-selection heuristic is the single highest-leverage decision in the entire system. Everything else — shuttle routing, input placement, output retrieval — is dominated by whether the robot commits correctly to a destination family.
The largest_stock heuristic's dominance in throughput is a useful real-world result: the best warehouse scheduling algorithm is often the simplest one you can reason about clearly under pressure. Complexity only earns its keep when the constraint you are optimising for (energy, wear, cost) is explicitly different from raw throughput.

Log in or sign up for Devpost to join the conversation.