-
-

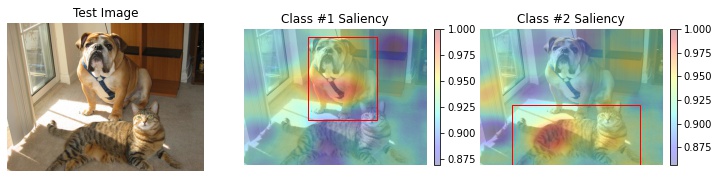
Saliency for image classification
-

Saliency for object detection
-

Saliency for deep reinforcement learning


Inspiration
Deep learning has undergone a recent revolution, enabling predictive models that are learned directly from data and can perform well on downstream tasks. Unfortunately, these models are also "black boxes", and in mission-critical situations, their lack of interpretability presents a serious barrier to use. We aim to support the field of explainable artificial intelligence (XAI) by developing tools and resources for explaining and interpreting deep learning models.
To address this in part, we are developing an open-source toolkit xaitk-saliency. The toolkit is designed to help explain complex, black-box machine learning algorithms in various domains, including image classification, object detection, and reinforcement learning. The toolkit currently provides interface classes and implementations to compute “visual saliency maps” from black-box models, which help to reveal what a model pays attention to when it makes its prediction. By nature of its design, the toolkit is modular and easily extendable, allowing reuse of components across different domains and even software frameworks, including models developed outside of Pytorch, such as scikit-learn or Tensorflow.
What it does
The xaitk-saliency package is an open-source, explainable AI toolkit for visual saliency algorithm interfaces and implementations, built for analytic and autonomy applications. The toolkit provides saliency map algorithms as a form of visual explanation of black-box models in domains such as image classification, object detection, and deep reinforcement learning. Several example notebooks are included that demo the current capabilities of the toolkit. The xaitk-saliency package will be of broad interest to anyone who wants to deploy AI capabilities in operational settings and needs to validate, characterize and trust AI performance across a wide range of real-world conditions and application areas using saliency maps.
How we built it
xaitk-saliency is open-source and written in Python 3. We focus on black-box, perturbation-based saliency algorithms such as sliding-window occlusion (Zeiler and Fergus, ‘13) and Randomized Input Sampling for Explanations or RISE (Petsiuk et al., ’18). As such, we split the process of saliency map generation into: 1) an image perturbation step and 2) a perturbed output scoring step. Each of these sub-components have different interfaces and implementations, making them reusable and extendable across domains. For many of our examples, we leverage pretrained models provided by Pytorch and/or torchvision. We also provide abstract interfaces that encapsulate black box models, making it easy to apply our framework to arbitrary models in Pytorch (or other software libraries).
Challenges we ran into
Finding a niche for black box saliency map algorithms that complements current existing tools in this ecosystem, such as Captum. Developing generalizable interfaces and proper data structure for storing and passing around data (e.g. using numpy arrays vs. PIL images).
Accomplishments that we're proud of
Having a flexible and modular framework that allows for reuse of components and can be easily extendable across multiple domains, such as image classification, object detection, and reinforcement learning. Being able to support models built in Pytorch, as well as other software frameworks for interoperability purposes.
What we learned
Good open-source software practices, such as creating good documentation, a Contributing.md file for new developers and contributors, and setting up robust continuous integration workflows. Leveraging existing functionality within Pytorch/torchvision to create demos and examples.
What's next for xaitk-saliency
Support for other black-box saliency algorithms, such as LIME, SHAP, or anchor-based approaches which require computation of super-pixels on the image first.

Log in or sign up for Devpost to join the conversation.