-
-
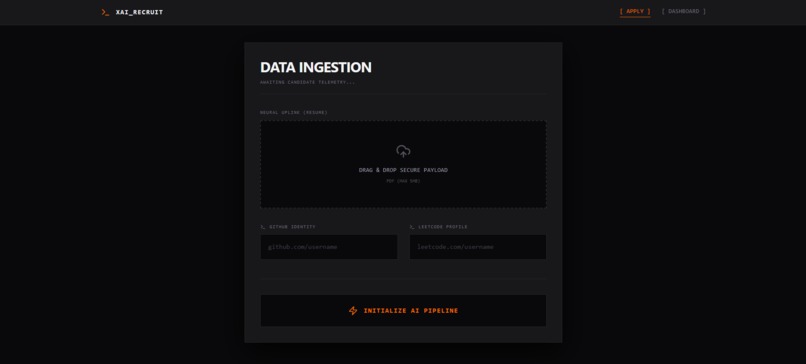
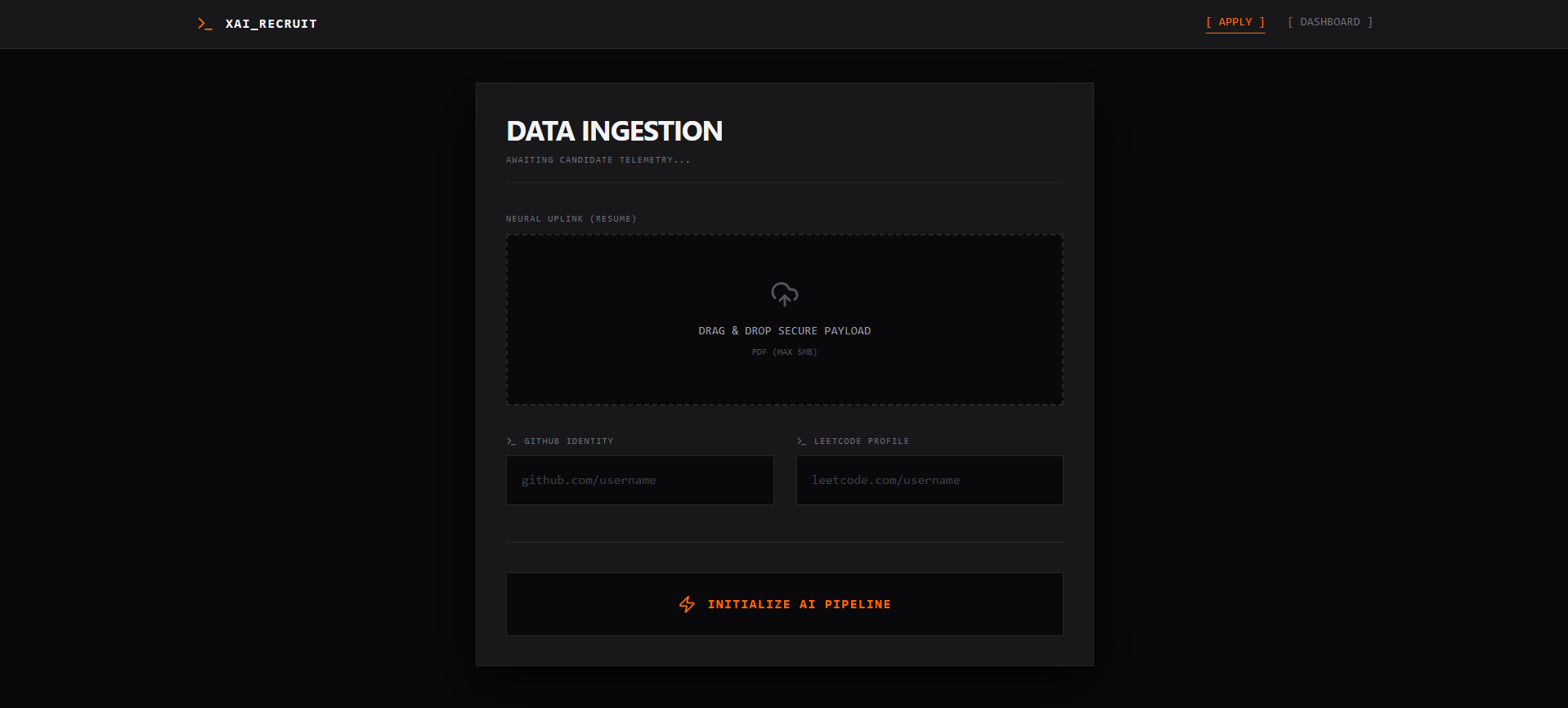
candidate dope box and AI pipeline initalizer
-
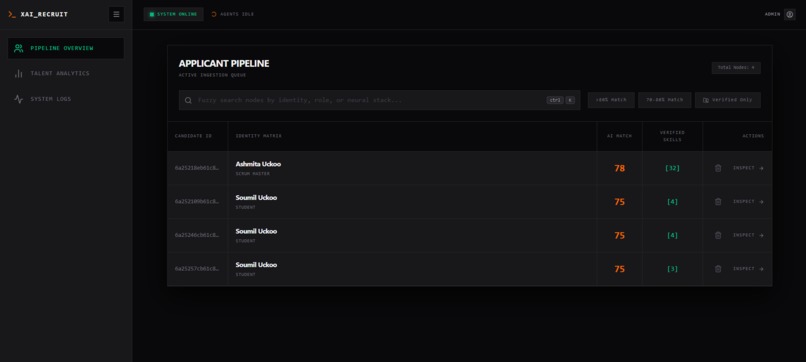
dashboard
-
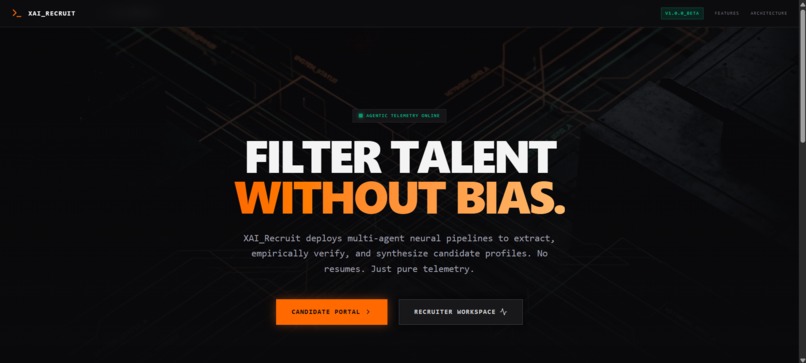
landing page
-
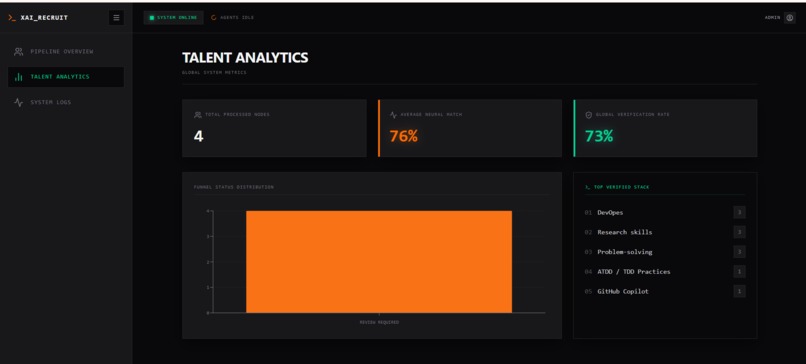
dashboard
-
dashboard
-
dashboard
-
dashboard
Inspiration
I was frustrated by the broken paradigm of modern technical recruitment. Traditional Applicant Tracking Systems (ATS) rely on fragile regex algorithms and keyword matching. They suffer from massive false-negatives (filtering out brilliant engineers who didn't perfectly format their resumes) and false-positives (letting through bad candidates who simply copy-pasted jargon in white text). I realized the hiring process shouldn't be about what a candidate claims, but rather what I can empirically verify. I wanted to build a system that acts like a Principal Engineer screening a candidate, rather than a mindless keyword filter.
What it does
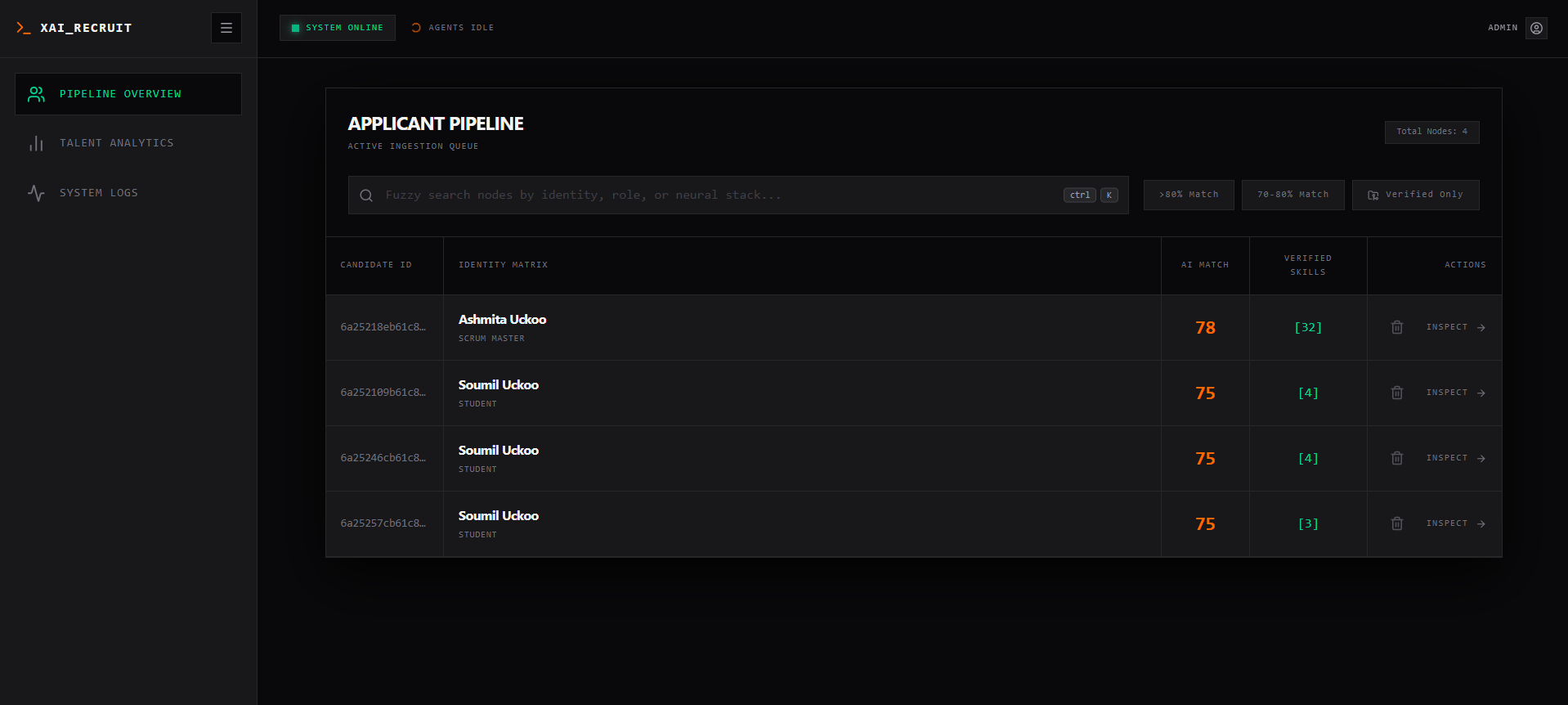
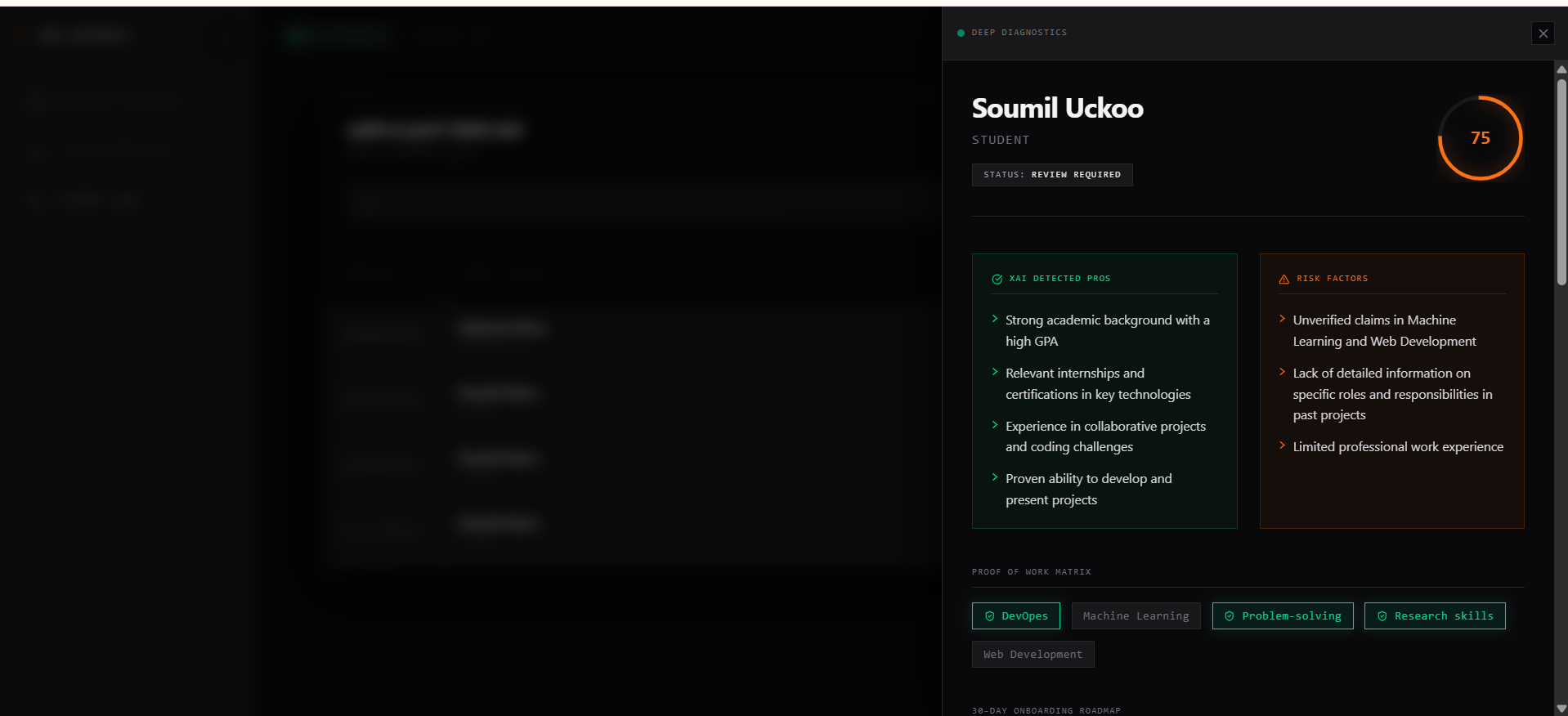
XAI_Recruit is an agentic technical talent filtering platform. It deploys autonomous, multi-agent neural pipelines to deeply analyze resumes without human bias.
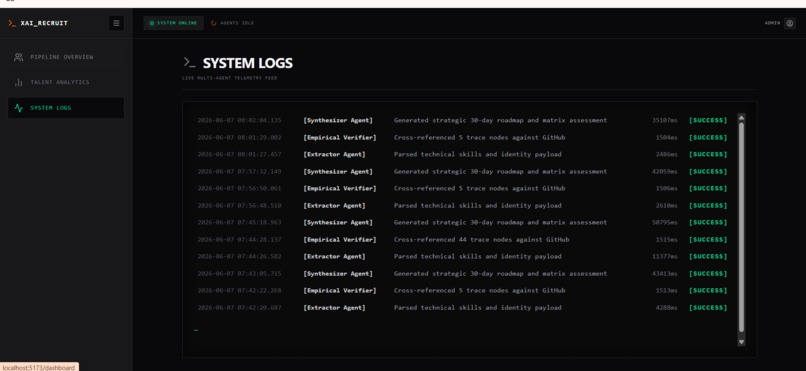
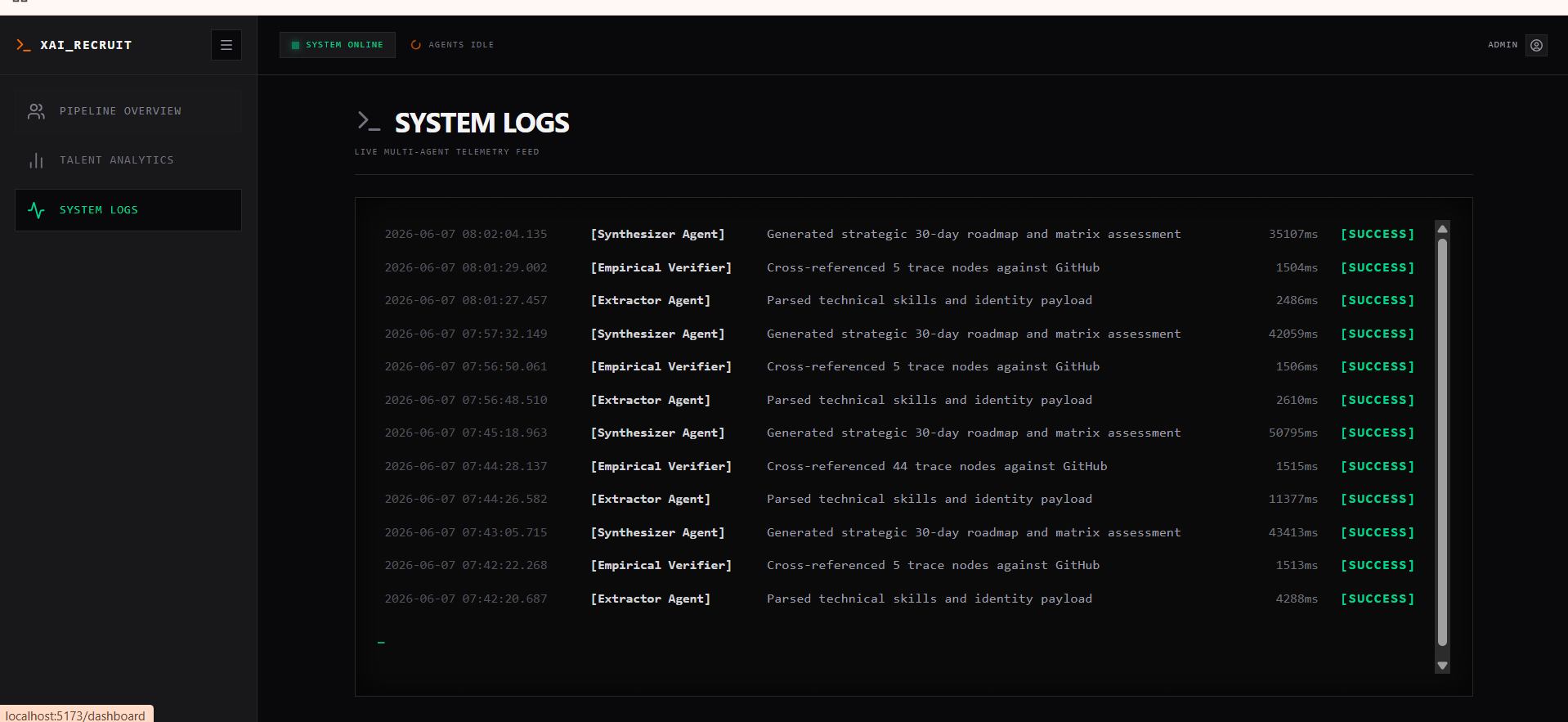
- A lightning-fast Qwen-7B Extractor Agent aggressively parses unstructured PDF data to extract technical claims.
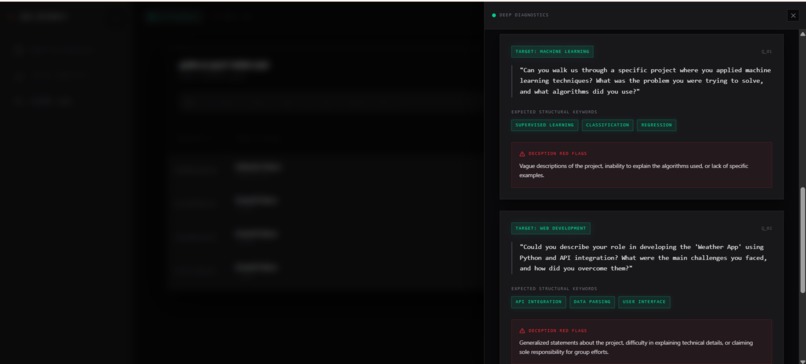
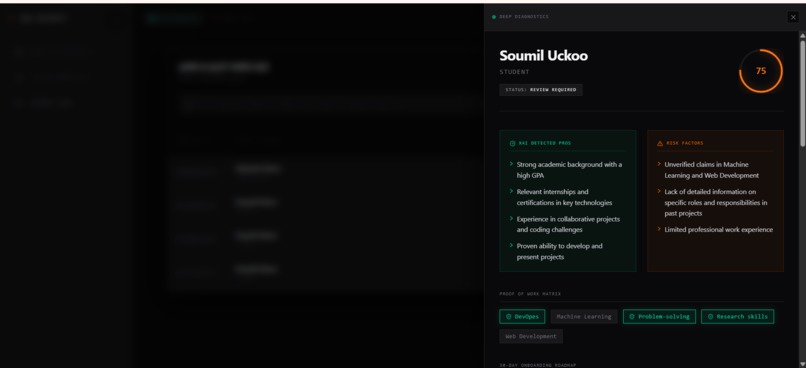
- The Empirical Verifier instantly cross-references every claimed technology against public open-source footprints (e.g., GitHub), establishing a strict Proof-of-Work matrix.
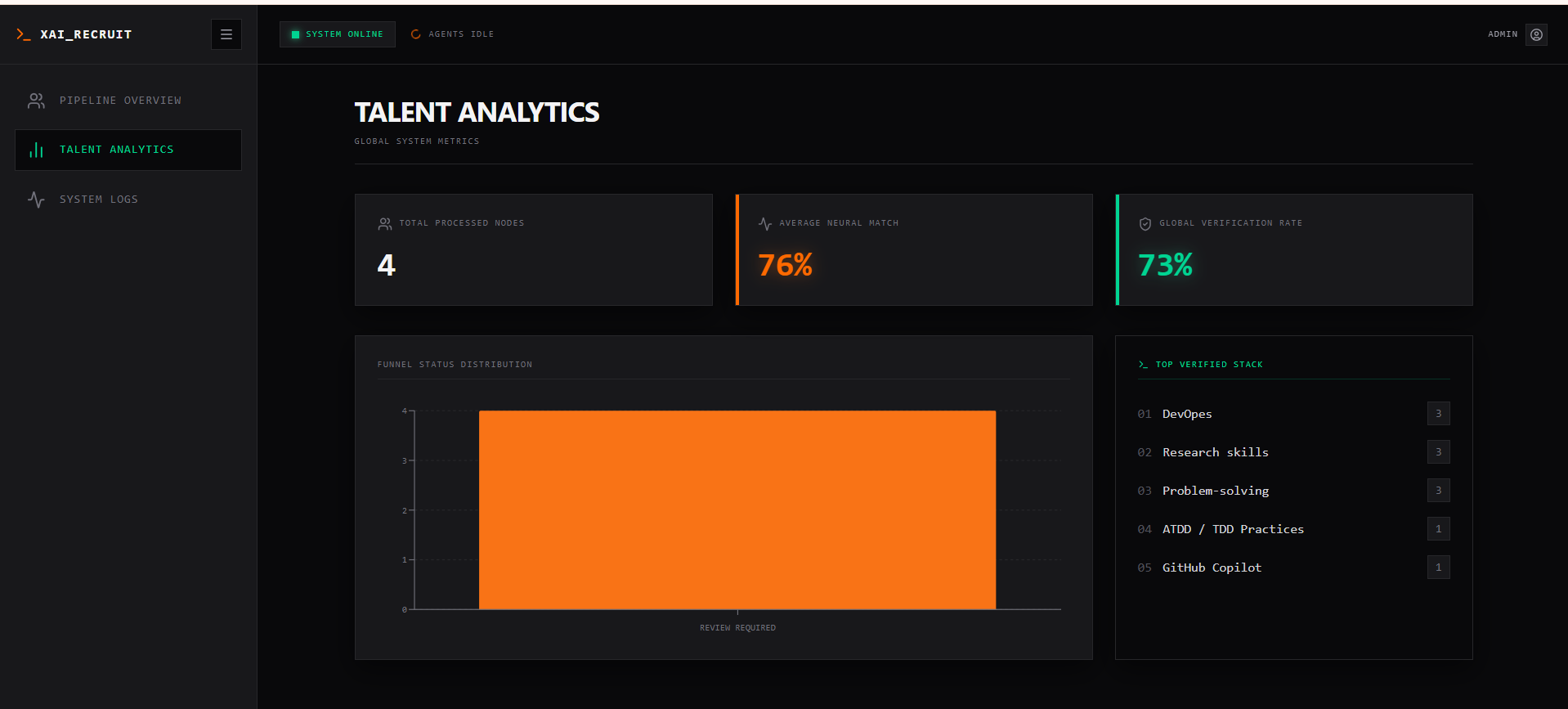
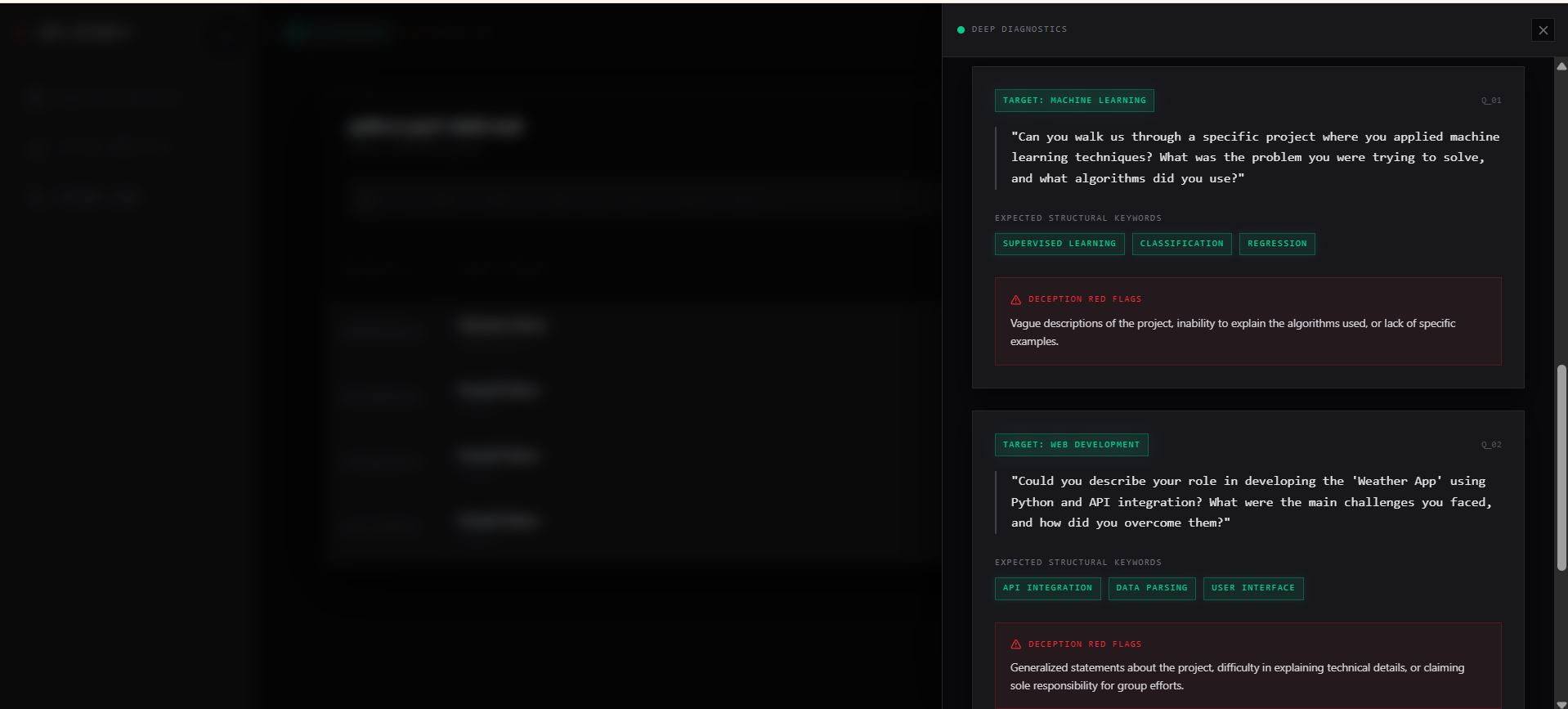
- Finally, a heavy-duty Qwen-72B Synthesizer Agent evaluates the verified data, calculates a highly accurate Match Score, generates a custom 30-day onboarding roadmap, and builds an AI Inquisitor Playbook—a custom set of technical interview questions designed to spot deception regarding any unverified resume claims.
How we built it
I engineered a strict, decoupled architecture:
- Frontend: React 18, Vite, and TailwindCSS styled in a brutalist "Cyber-Industrial" dark mode (Zinc, Neon Orange, Emerald). I utilized Framer Motion for radial telemetry animations.
- Backend Orchestration: A Node.js/Express engine handling PDF binary extraction via
multerandpdf-parse. - Infrastructure: To run massive 70B+ parameter open-weight models without crippling cloud GPU costs, I routed my architecture exclusively through the Featherless AI serverless inference platform.
- Telemetry: I implemented real-time Server-Sent Events (SSE) to stream the live thought-process of the AI agents directly from the backend to the frontend UI.
Challenges we ran into
- JSON Schema Hallucinations: Forcing a massive LLM to return strictly typed JSON structures (for my React frontend to parse) without conversational markdown bleeding into the payload. I had to heavily sanitize the output streams.
- Hardware Constraints: I initially struggled with the VRAM requirements needed to run an intelligent enough model to evaluate engineers. Migrating my
openaiSDK baseURL to the Featherless AI platform was the breakthrough that let me seamlessly trigger 72B parameter models in milliseconds. - Connection Latency: Long-running LLM inferences were causing standard HTTP requests to time out in the browser. I had to completely refactor the backend routing to support Server-Sent Events (SSE) to keep the connection alive via chunked streaming.
Accomplishments that we're proud of
I am incredibly proud of the AI Inquisitor Playbook. When my system detects that a candidate claims a skill but has zero public proof of work, it doesn't just reject them—it auto-generates 3 highly specific, structural interrogation questions targeting that exact claim. It even flags specific "Deception Red Flags" so non-technical HR recruiters can instantly spot if a candidate is bluffing.
What we learned
I learned the profound difference in orchestrating a Multi-Agent pipeline versus a standard single-prompt LLM call. By chaining disparate models (using a fast 7B model for cheap data extraction, and reserving the expensive 72B model solely for deep-reasoning synthesis), I exponentially reduced my latency and API overhead without sacrificing analytical intelligence.
What's next for XAI_RECRUIT
Autonomous Voice Screening: I plan to upgrade the AI Inquisitor Playbook from a text-based script for human recruiters into a fully autonomous, voice-to-voice screening agent. The system will actually call the candidate, ask the targeted technical questions, and run real-time sentiment and latency analysis to detect bluffing.
Built With
- 2.5
- and-vite-for-the-frontend
- css
- express.js
- featherless
- framer-motion-for-animations
- mongodb
- mongoose
- node.js
- openai
- qwen
- react
- server-sent
- tailwind
- typescript
- vite
- with-tailwind-css-for-styling


Log in or sign up for Devpost to join the conversation.