-
-

Infrastructure diagram
-
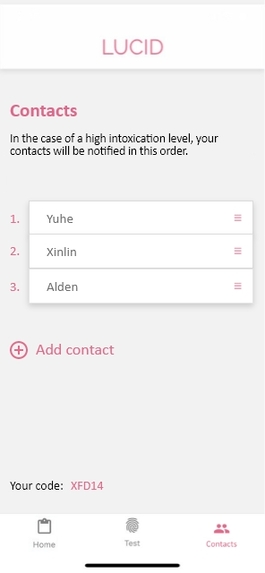
Contacts section
-
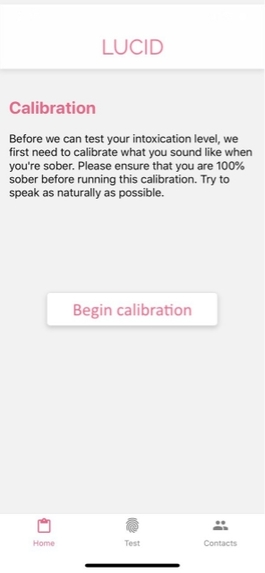
Calibration of the user's speech when sober
-
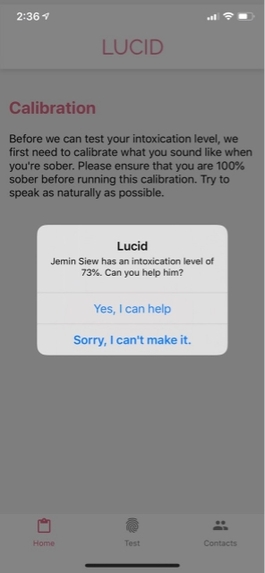
Notification when Lucid detects a high intoxication level



Inspiration
The United Nations health agency's reported that alcohol causes more than one in 20 deaths globally each year, including those resulting from drink driving, alcohol-induced violence and abuse and a multitude of diseases and disorders.
Yet another study conducted in the US found that 11% of women have experienced alcohol or drug-facilitated sexual assault at some point in their lives, and 5.5% of men were made to penetrate someone else through alcohol/drug facilitation.
We imagined a world where there was much more lucidity, and a clearer awareness about one’s own degree of intoxication to avoid making dangerous decisions. Why were we relying on legacy devices like breathalyzers that were expensive and impractical, when we could bring this knowledge into the hands of the masses?
We believed that if the individual could signal for help once they were past a certain threshold of intoxication, they would be able to get themselves out of potentially precarious scenarios.
What it does
We created an intuitive app that could enable users to self detect their level of intoxication, automatically reaching out to saved contacts once the user presented that they were overly intoxicated.
How we built it
Our app detects intoxication on two fronts, leveraging both mental and verbal cues in order to come to a conclusion on the user’s intoxication level.
Since intoxication causes impairment of cognitive functions (Fillmore, 2007), the basis of checking for intoxication is through time-sensitive simple logic puzzles. The app will ask the user a series of questions. A sample question would be: “If you have to wake up for a meeting at 8am tomorrow, what should you do?”. The user is expected to respond with possible commands, that wit.ai can then process. If the user returns an incoherent or illogical answer, the audio file of the user’s response will be sent together with a notification to the user’s saved contacts.
This audio file will also be processed by our RNN ML model, which will consider the following speech properties that are affected by intoxication (Marge, 2011):
- Clarity of pronunciation: Intoxicated users tend to have poorer speech clarity
- Pace of speech: Intoxicated users tend to speak slower
- Pitch accents: Intoxicated users have higher/lower emphasis frequencies as compared to when they were sober
Challenges we ran into
We were limited by the fact that we did not possess a comprehensive dataset of audio files at varying degrees of intoxication. This dataset would be necessary in order to build the speech recognition capabilities of our app. In order to mitigate this limitation, our app will also actively be collecting data. This happens when we send the audio file of the user’s response to his saved contacts, and the contact responds to this audio file by identifying it as “Sounds OK” (not intoxicated) or “I’m on my way” (intoxicated). Clicking either of these buttons serve as a human form of verification, generating data that is cleanly labeled as either intoxicated or not. These datasets can then be used to further refine our RNN model, improving its accuracy in detecting intoxication via audio files.
Accomplishments that we're proud of
Building a working prototype!
What we learned
Data considerations - we wanted to make sure that users' privacy was not compromised, and so we thought also about anonymizing our data collection as well.
What's next for Lucid.ai
Refining our Machine Learning model and ensuring higher degrees of accuracy for our product.
Built With
- adobe-xd
- flask
- python
- react-native
- wit.ai



Log in or sign up for Devpost to join the conversation.