-
-

Front Page
-
Parameter Selection
-
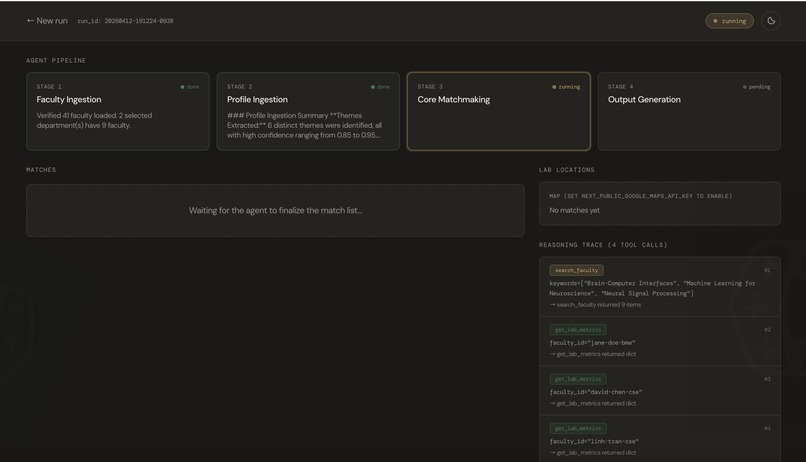
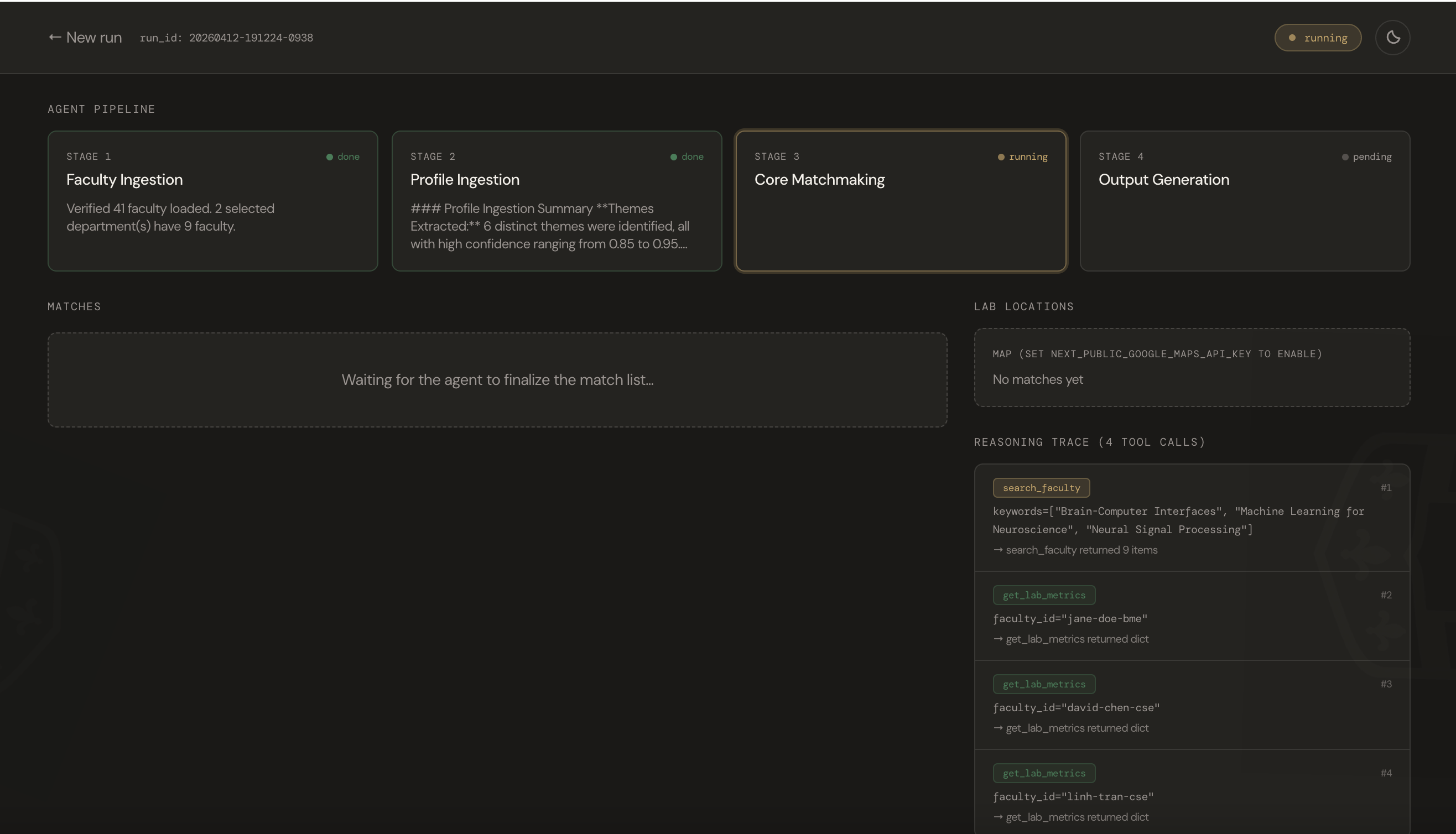
Agent Pipeline Running
-
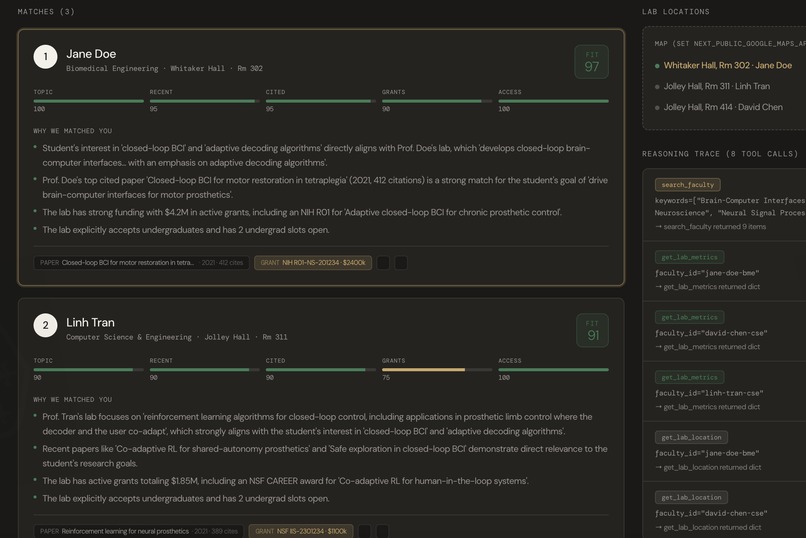
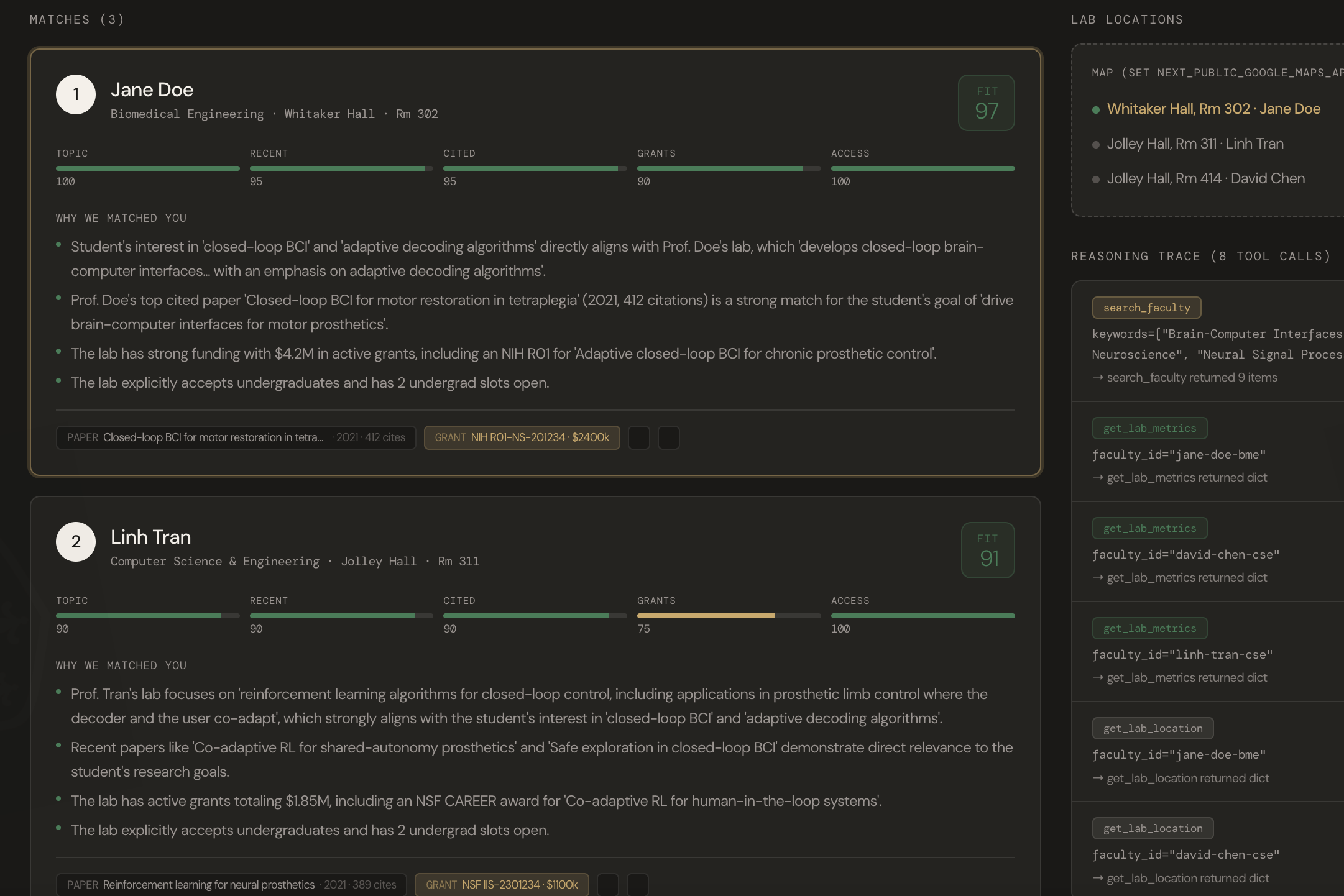
Results

Inspiration
As a team with many friends who want to do research, we know that finding faculty research opportunities at WashU is a frustrating, manual process that takes students 3+ hours per search. Students have to navigate fragmented department websites, parse dense publication histories, guess at lab availability, and cold-email professors with no idea if there's a real fit. Even with prompting LLMs, this process is long and frustrating. This inequity means students without insider connections miss out on high-impact research. We wanted to turn that 3-hour struggle into a 5-minute, AI-powered experience — giving every student equal access to the best-fit research opportunities on campus.
What it does
Research Matchmaker takes a student's personal statement and runs it through a four-stage Gemini agentic pipeline to produce:
- A ranked list of 5 faculty matches, each with a compatibility score and a clear reasoning trace ("Why we matched you") showing which papers, grants, and research themes drove the decision.
- Lab metrics — grant funding status, undergraduate openness, recent publication activity — so students can make informed decisions.
- A personalized cold email draft per match, ready to copy and send.
The entire process takes under 5 minutes. The live dashboard streams progress in real time as each stage completes, so students can watch the agent reason through their profile.
How we built it
Backend: Python FastAPI on Cloud Run
The agent service exposes a single POST /run endpoint. When a student submits their statement, a background task launches the four-stage agent pipeline, each agent fitted with their own unique function:
Faculty Ingestion — Checks whether the Firestore faculty database has sufficient coverage for the student's research themes. If coverage is thin (< 3 candidates per theme), it scrapes live WashU department pages using
httpxand a Gemini HTML-parser agent (no BeautifulSoup or Playwright — all parsing is done by Gemini on raw HTML). New profiles are enriched with papers from the Semantic Scholar API.Profile Ingestion — Sends the personal statement to Gemini to extract structured interest vectors, technical skills, and background facts.
Core Matchmaking — A multi-step Gemini tool-calling loop that autonomously decides which tools to invoke (
search_faculty,get_lab_metrics,get_lab_location) based on the student's unique profile. It evaluates semantic alignment between student interests and each faculty member's 5 most recent and 5 most cited papers, weighs active grant quality, and checks undergraduate openness. Every tool call is logged to Firestore and streamed to the UI's reasoning trace.Output Generation — Drafts a unique, non-generic cold email per match incorporating specific details from the reasoning trace, then writes the final bundle to Firestore.
Each stage has three layers:
- An agent prompt (loaded verbatim as the Gemini system prompt)
- A SKILL.md orchestration contract (hard gates, handoff validation)
- A Python script (deterministic I/O + LLM calls only where reasoning is needed)
Frontend: Next.js 16 + Tailwind + Firebase
The frontend listens to Firestore via onSnapshot for real-time updates. Key components:
- StageProgress — live pipeline tracker showing which of the 4 stages is running
- MatchCard — displays each match with score, reasoning chips, and key metrics
- LabMap — Google Maps integration pinning lab locations
- ReasoningFeed — scrollable feed of every tool call the agent made
- ColdEmailPanel — one-click copy of the generated outreach email
Infrastructure — Firebase + Cloud Run
Firestore acts as the shared state bus between backend and frontend: run status, stage progress, tool call logs, and final output all live under runs/{runId}. The backend writes; the frontend listens. No WebSocket server needed.
Challenges we ran into
- WashU faculty pages have wildly inconsistent HTML. Every department formats their listing differently. Instead of writing 11 custom scrapers, we feed raw HTML to a Gemini HTML-parser agent that extracts structured JSON. This was more resilient than any regex or BeautifulSoup approach we tried.
- Keeping the Gemini tool-calling loop focused. Early iterations of the Core Matchmaking agent would call tools in circles or fixate on irrelevant departments. Careful prompt engineering in the agent system prompt — plus a step counter and hard gate in the SKILL contract — kept it on track.
- Dry-run mode for rapid iteration. We needed to build and demo the full UI flow without burning Gemini API credits during development. Both
GeminiClientandFirebaseClientsupport aMATCHMAKER_DRY_RUN=1mode that returns realistic stub data through the entire pipeline.
Accomplishments that we're proud of
- End-to-end agentic pipeline — from raw text input to ranked matches with reasoning traces and cold emails, fully streamed to a live dashboard.
- Zero scraping libraries — the HTML-parser agent handles all web scraping via Gemini, making the system more robust to page layout changes.
- Semantic Scholar, ORCID, and OpenAlex enrichment — faculty profiles are automatically enriched with real publication data, not just what's on the department website.
- Full dry-run mode — the entire system (4 agents, Firestore, frontend) works end-to-end with zero API keys for rapid development and demo.
- One-command launch —
python3 start.pyboots both the backend and frontend from a single terminal.
What we learned
- Gemini's native function-calling is powerful but needs guardrails. Agent prompts must be specific about when to call tools and when to stop — vague instructions lead to loops.
- Using Firestore as a real-time state bus between backend and frontend is clean and eliminates the need for WebSockets or polling.
- Feeding raw HTML to an LLM for structured extraction is surprisingly effective and far more maintainable than writing custom parsers for each department.
What's next for WUSTL STEM AI Research Matchmaker
- Scale to 500+ faculty across all WashU departments with scheduled background re-ingestion.
- PDF/DOCX upload for personal statements and resumes (currently text-only).
- Multi-university support — the architecture is university-agnostic; expanding to other schools means adding department URL mappings and location data.
- Follow-up tracking — let students mark which emails they've sent and track responses.
- Faculty-side dashboard — surface incoming student interest to professors who opt in.

Log in or sign up for Devpost to join the conversation.