-
-
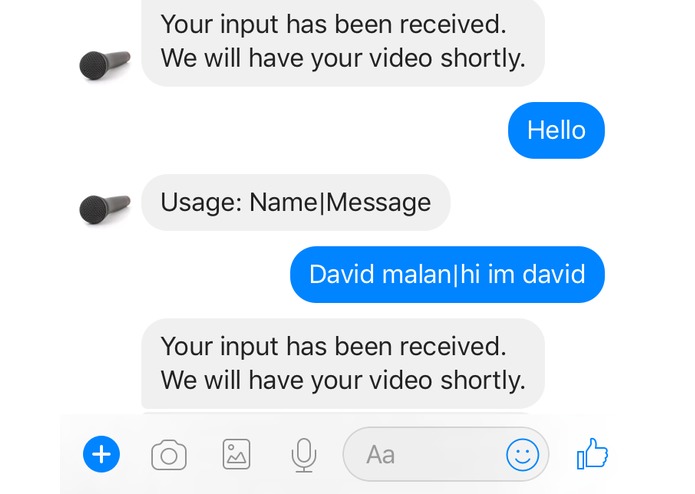
Example of user input from Facebook Messenger
Inspiration
-Inspired by baracksdubs and many "Trump Sings" channels on YouTube, each of which invests a lot of time into manually tracking down words. -Fully automating the process allows us to mass-produce humorous content and "fake news", bringing awareness to the ease with which modern technology allows for the production and perpetuation of generated content. -Soon-to-emerge technologies like Adobe VOCO are poised to allow people to edit audio and human speech as seamlessly as we are currently able to edit still images. -The inspirational lectures of Professor David J. Malan.
What it does
We train each available "voice" by inputting a series of YouTube URL's to main.py.
download.py downloads and converts these videos to .wav files for use in speech.py, which uses Google's Cloud Speech API to create a dictionary of mappings between words and video time-stamps.
application.py implements user interaction: given a voice/text input via Facebook, we use these mappings to concatenate the video clips corresponding to each word.
How we built it
First we decided on Python due to its huge speech recognition community. This also allowed us to utilize a collaborative online workspace through Cloud9 which helped facilitate concurrent collaboration.
We used google's speech api because we saw that it was very popular and supported time stamps for individual words. Also, they had very elegant json output, which was a definite bonus.
Next, we figured out how to use the packages pytube and ffmpy to grab video streams from youtube and convert them, with speed and without loss of quality, to the needed .wav and .mp4 formats.
At the same time, one of our team members learned how to use python packages to concatenate and split .mp4 videos, and built functions with which we were able to manipulate small video files with high precision.
Following some initial successes with google speech api and mp4 manipulation, we began exploring the facebook graph api. There quite a bit of struggle here with permissions issues because many of the functions we were trying to call were limited by permissions, and those permissions had to be granted by facebook people after review. However, we did eventually get facebook to integrate with our program.
The final step we took was to few remaining unconnected pieces of the project together and troubleshoot any issues that came up.
During the process, we were also investigating a few moonshot-type upgrades. These included ideas like the use of a sound spectrogram to find individual phonemes of words, so we could finely tune individual words, or generate new words that were never previously said by the person.
Challenges we ran into
A big challenge we ran into was that the Google Speech API was not extremely accurate when identifying single words. We tried various things like different file/compression types, boosting sound (normalizing/processing waveform), improving sound quality (bitrate, sampling frequency).
Another big challenge we ran into was that when we tried splicing the small (under 1 or 2 second) video files together, we realized they lost their video component, due to issues with key frames, negative timestamps, and video interpolation. Apparently, in order to save space, videos store key frames and interpolate between the key frames to generate the frames in between. This is good enough to fool the human eye, but it required that we do a lot of extra work to get the correct output.
A third big challenge we ran into was that when we communicated with the facebook api through our flask website, facebook would resend our flask page post requests before we were completed with processing the information from the previous post request. To solve this issue, we grabbed the post request information and opened new threads in python to process them in parallel.
A fourth big challenge we ran into was that wifi was so slow that it would take around 1 minute to upload a 1 minute video to Google's cloud for speech processing. Thus, in order to analyze large videos (1+ hours) we developed a way to use multiple threads to split the video into smaller segments without destroying words and upload those segments in parallel.
Accomplishments that we're proud of
We have a scalable, modular structure which makes future expansion easy. This allows us to easily switch APIs for each function.
What we learned
[Web Services APIs]
Speech to Text Conversion: --Google Cloud API --CMU Sphynx (Experimental Offline Speech-To-Text Processing with the English Lanugage Model) Facebook API Integration: --Accepting input from user via automated messenger bot development --Posting to Facebook Page
[Web Services Deployment]
Flask and Python Interfacing
[Python]
Multi-file Python package integration Team-based Development
[Video and Audio Conversion] --FFMPEG Video: Efficient Splicing, Keyframes, Codecs, Transcoding --FFMPEG Audio: Sampling Frequency, Sound Normalization
[Misc] --Automating the Production of quality memes --Teamwork and Coding while sleep-deprived
What's next for Wubba Lubba Dubz
We'd like to incorporate a GUI with a slider, to more accurately adjust start/end times for each word. Right now, we can only identify words which have been spoken exactly as entered. With Nikhil's background in linguistics, we will split an unknown word into its phonetic components. Ideally, we will build a neural net which allows use to choose the best sound file for each word (in context).



Log in or sign up for Devpost to join the conversation.