-
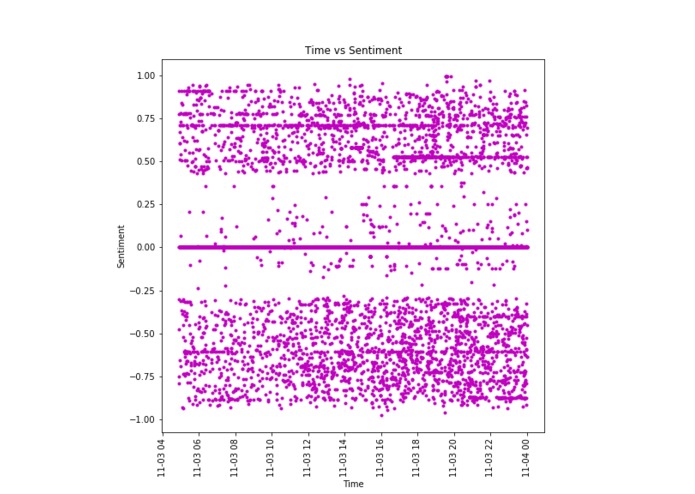
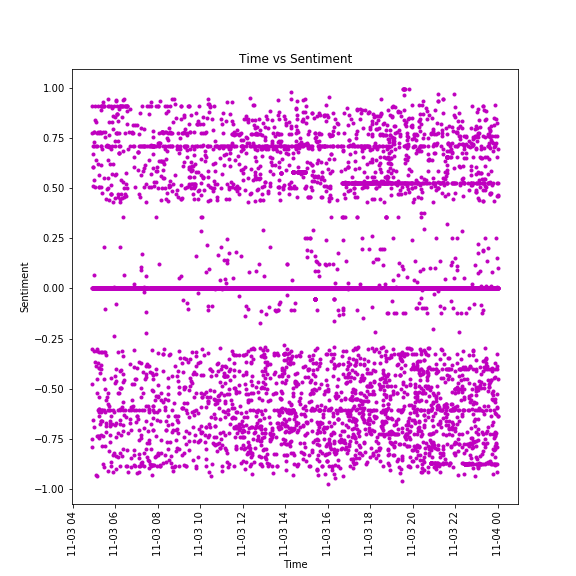
A time series of sentiment data for the term "iPhone"
-
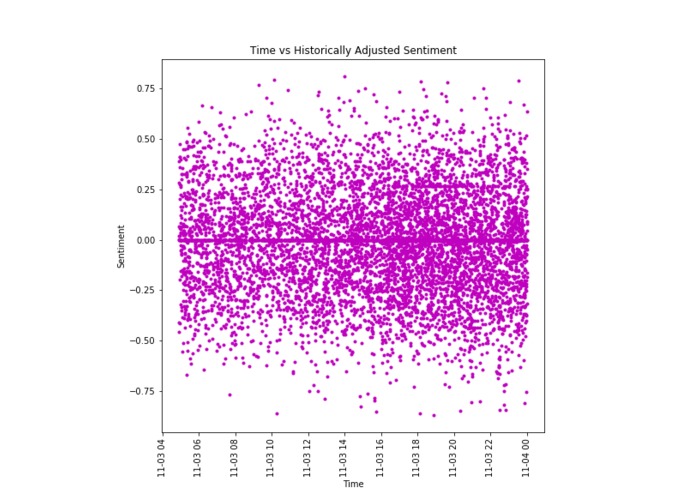
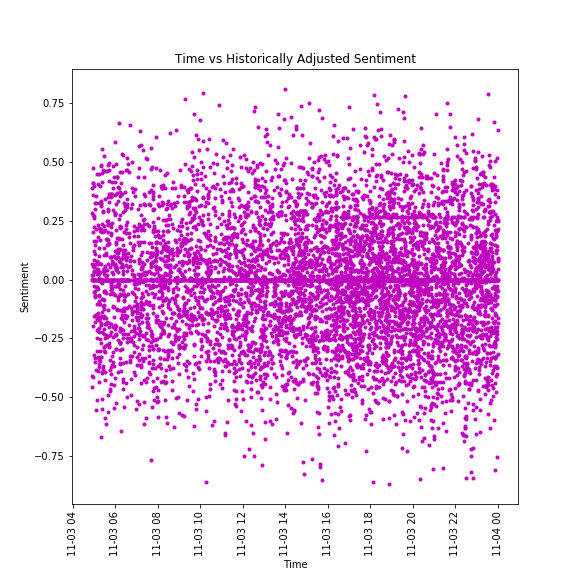
The same sentiment data adjusted for users' emotional profiles for the term "iPhone"
-
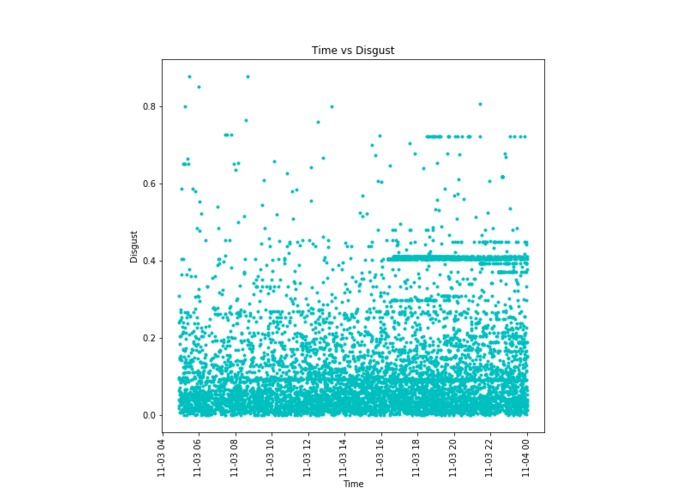
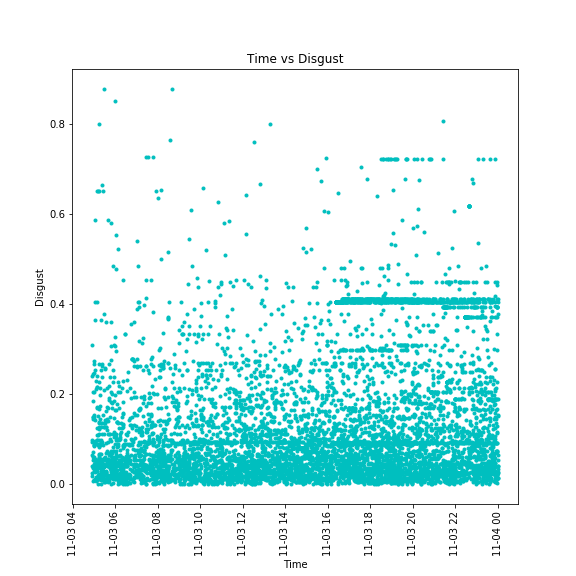
A time series of disgust emotional data for the term "iPhone"
-
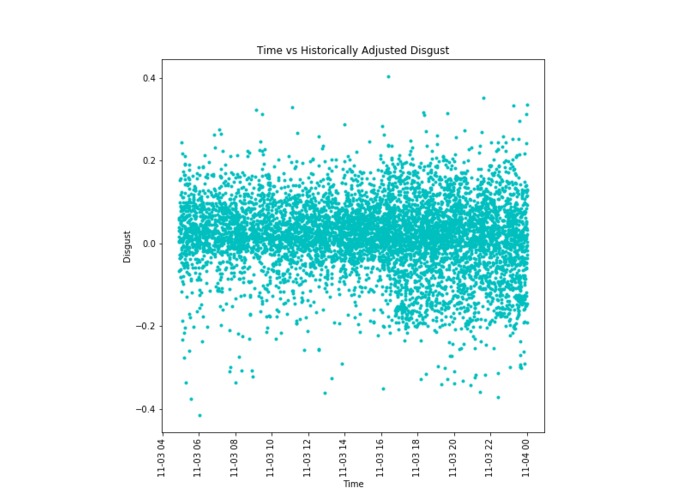
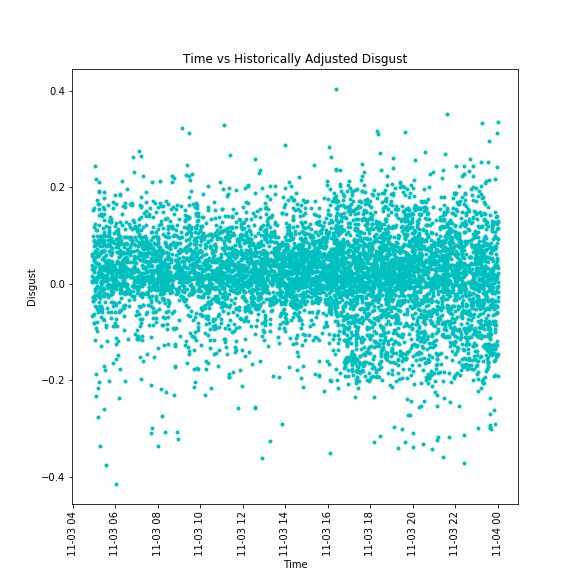
The disgust emotional data adjusted for users' emotional profiles for the term "iPhone"
-
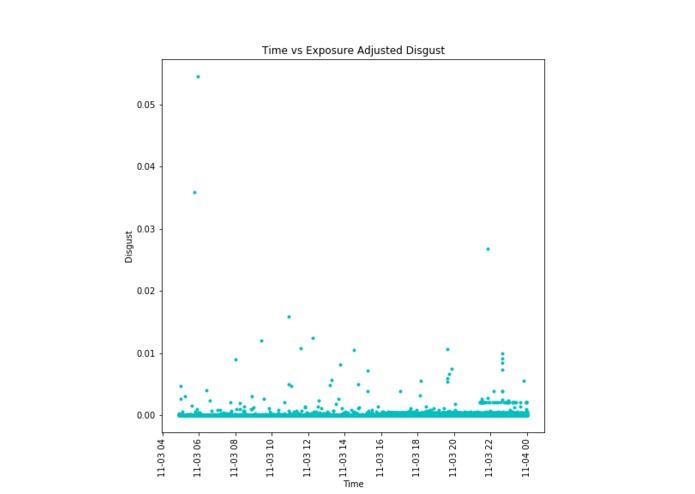
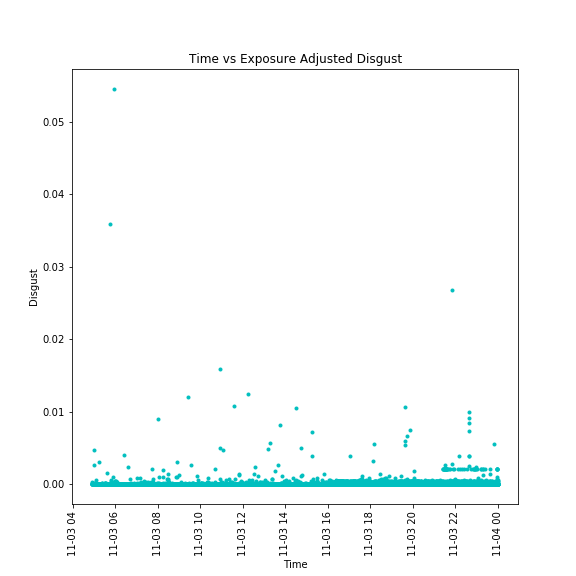
The disgust emotional data adjusted for exposure levels for the term "iPhone"
-
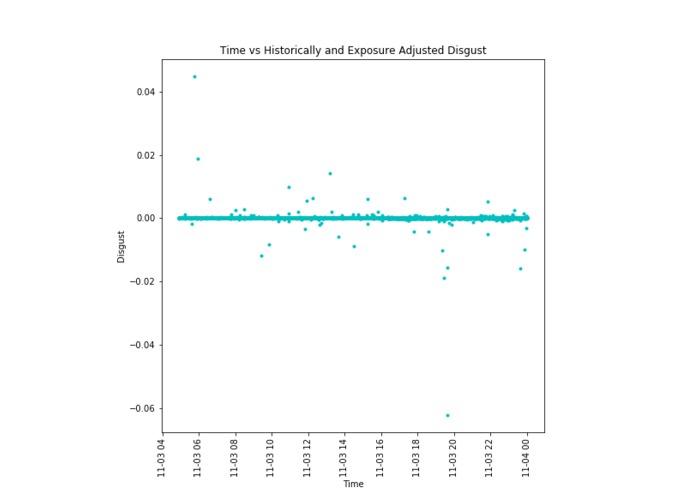
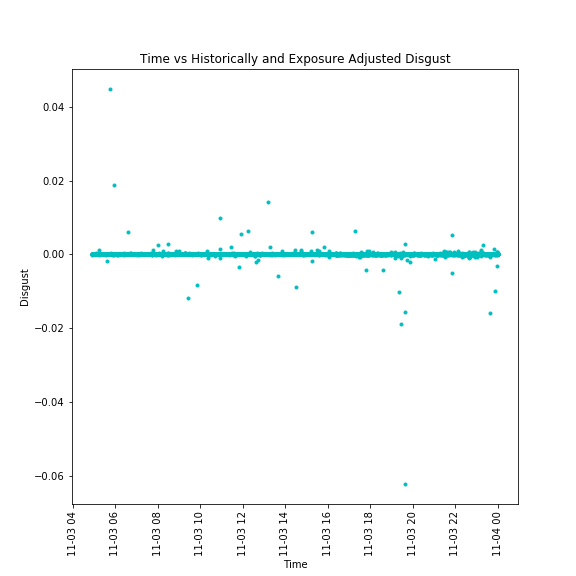
The disgust data adjusted for both historic emotional profile and exposure levels for the term "iPhone"
Inspiration
We wanted to find some way to make Social Media quantifiable. Specifically to be able to have a reliable data stream to later analyze how social perception affects market data. With Watson, we are able to better understand what marketing information is hiding in your Twitter feed.
What It Does
We are able to use what we built to get a data stream to quantify social media reception to both individual products, and companies overall. We can use both Watson and Wikipedia to get higher level associations between the companies and their products. We can then use these relations to understand how a company as a whole is being represented on social media. We can use Watson to quantify both emotion and tone of tweets to gauge a public perception of the company and its products. The hope is to leverage this quantification of public perception to better understand what happens not just on the clock, but after hours as well.
How We Built It
We utilized Twitter’s, Wikipedia’s and Watson’s API calls to leverage Natural Language Understanding to make sense potentially mountains of untapped big data. We first took advantage of Watson’s knowledge base, to find the terms most synonymous with a company. We take a high-level Wikipedia summary of the company, and utilize Watson to identify the core concepts found there. From we suggest that a user query twitter around these terms, but also give them the ability to edit the list. From here we mine Twitter for all the most recent tweets involving these terms and let Watson understand both emotion and sentiment of these tweets. From here we go back historically and build and emotional profile for each user who recently tweeted relating to the company. This allows us to adjust our data to understand how severely the companies actions illicit a response from the individual. We also take into account the potential exposure that these tweets can have. We added a low-level GUI, to bridge the technical gap that often accompanies the budding field of Natural Language Processing.
Accomplishments We’re Proud Of
1) We can keep up with a day to day stream with only consumer level access. We do lose a lot of time, but it is nice to have something that can provide real-time data without any expensive computing costs.
2) We built out a GUI interface. We’re not the biggest devs, but we realize that a GUI allows more people to potentially be able to find trends in social media data.
Challenges We Faced
1) API Call restrictions. On a consumer level we had a finite amount of requests that we could send to twitter. This meant that nearly 7 hours of the hack, was devoted to data mining. The good news is, that an enterprise level Twitter API, you could easily keep up with a real-time stream of tweets.
2) 20 Hour Data Set. Our hopes coming in were that we could potentially observe how the public reception of a product and or company can influence market values of publicly traded companies, especially in the first hour frenzy or the trading day.
Where to Go From Here
1) See above. Because we have the ability to mine a stream of data, we can slowly collect temporal data and begin to observe long term trends.
2) Other textual data. Reddit, albeit anonymous, gives great API access and allows us to search through a user’s post history to build an emotional profile.
3) We have to clean this code-base up a lot. It is a hackathon; hacky code is great for a quick build, but if we want to use this again, we should clean what we have.
What We Learned
1) We’re a team of first hackers, and 60% freshman. It was a great experience and had a ton of fun doing it.
2) Only 2 members of the team were of computer focused majors, and both were freshmen. This was a great hands experience to dive into a larger scale project for students with very little experience in programming.
3) Soylent is gross.
Built With
- ibm-watson
- python
- wikipedia-api

Log in or sign up for Devpost to join the conversation.