-
-
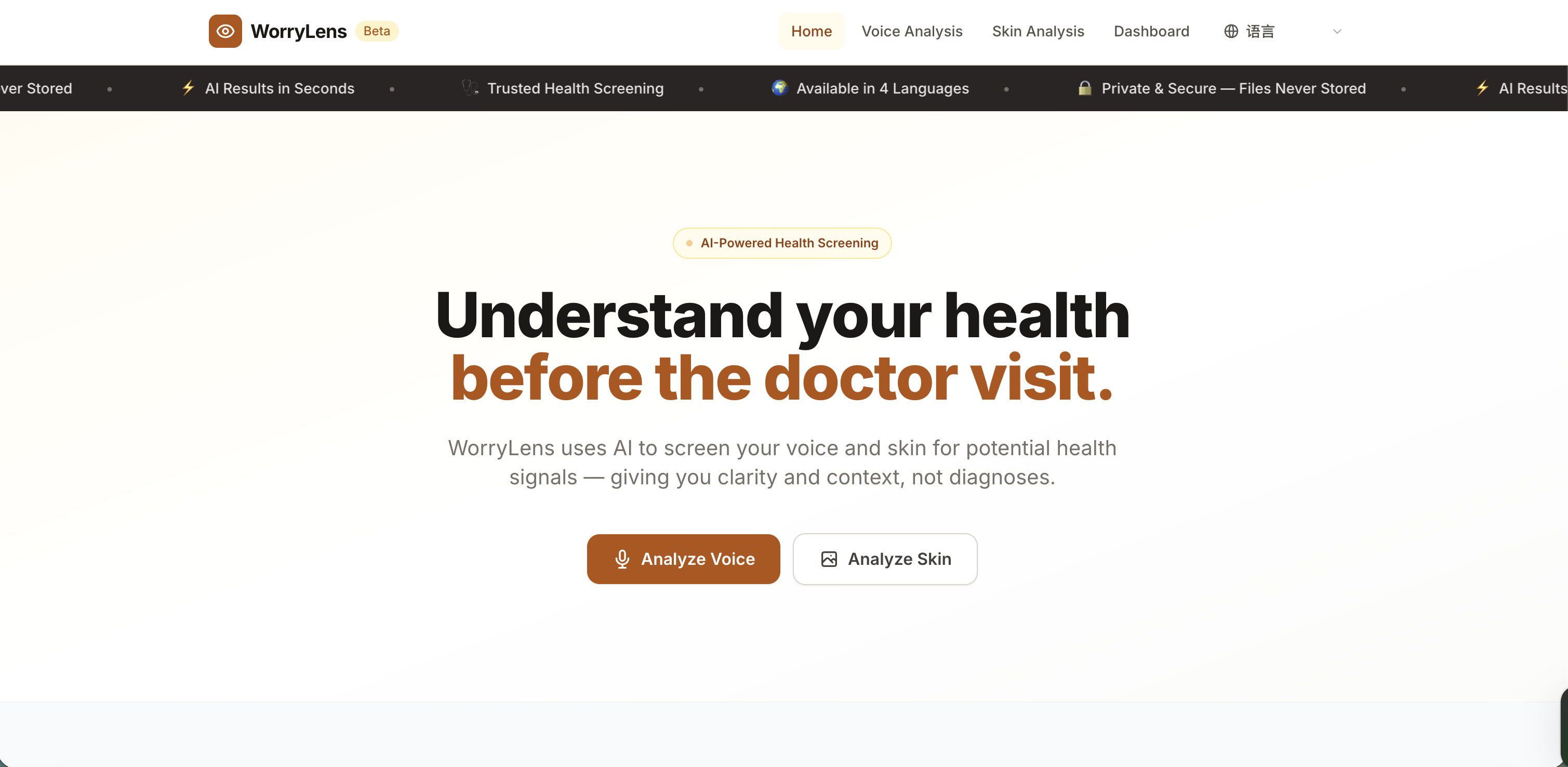
Home Page Layout
WorryLens — Multimodal Health Signal Intelligence
Inspiration
Medical anxiety often starts small. A minor symptom leads to a search, which quickly spirals into worst-case scenarios. Existing tools provide information, but not clarity—they leave users to interpret risk on their own.
WorryLens was inspired by a simple idea:
Instead of asking users to guess what’s wrong, what if we could read signals directly from the body?
Your voice and skin already contain measurable indicators of stress, fatigue, and potential health irregularities. We wanted to turn those raw signals into something structured, grounded, and actionable—before anxiety takes over.
What it does
WorryLens is a multimodal AI health signal analyzer that uses:
- Voice input to detect stress, fatigue, and vocal irregularities
- Camera input to assess skin condition, hydration, and visible anomalies
These signals are transformed into structured features and combined into a unified interpretation.
Instead of returning generic AI responses, WorryLens provides:
- signal-based health insights
- confidence-aware feedback
- grounded, non-diagnostic guidance
At its core:
$$ \text{Insight} = f(\text{Voice}, \text{Skin}, \text{User Context}) $$
How we built it
We designed WorryLens as a signal → structure → reasoning pipeline:
Input Layer
- Browser-based microphone and camera capture
- Real-time voice and image acquisition
- Browser-based microphone and camera capture
Feature Extraction
- Voice → speech patterns, pacing, and tone analysis
- Skin → computer vision heuristics (texture, color variation, contrast)
- Voice → speech patterns, pacing, and tone analysis
Multimodal Fusion
- Convert signals into structured features
- Combine into a unified representation of user state
- Convert signals into structured features
Reasoning Layer
- AI interprets structured inputs
- Outputs grounded insights instead of raw generated text
- AI interprets structured inputs
Challenges we ran into
Signal noise & variability
Lighting conditions and background noise impacted reliability, requiring normalization and fallback handling.Avoiding the “GPT wrapper” trap
We moved beyond text-in/text-out by building a structured pipeline with real intermediate signals.Trust vs. overclaiming
Providing useful insight without implying diagnosis required careful framing and confidence-aware outputs.
Accomplishments that we're proud of
- Built a true multimodal system combining voice and visual signals
- Designed a structured reasoning pipeline, not just a chatbot
- Addressed a real and widely experienced problem (health anxiety)
- Delivered a working real-time product within hackathon constraints
What we learned
- Multimodal systems are significantly more complex than text-based AI
- Users trust systems that show how conclusions are formed
- Explicit uncertainty improves credibility and usability
- Solving real problems requires balancing technical accuracy with human psychology
What's next for WorryLens
- Improve signal accuracy with better normalization and calibration
- Add confidence scoring and uncertainty visualization
- Integrate clinical grounding and medical reference layers
- Expand to additional health signals beyond voice and skin
- Develop into a pre-diagnostic companion tool for everyday health awareness


Log in or sign up for Devpost to join the conversation.