-
-
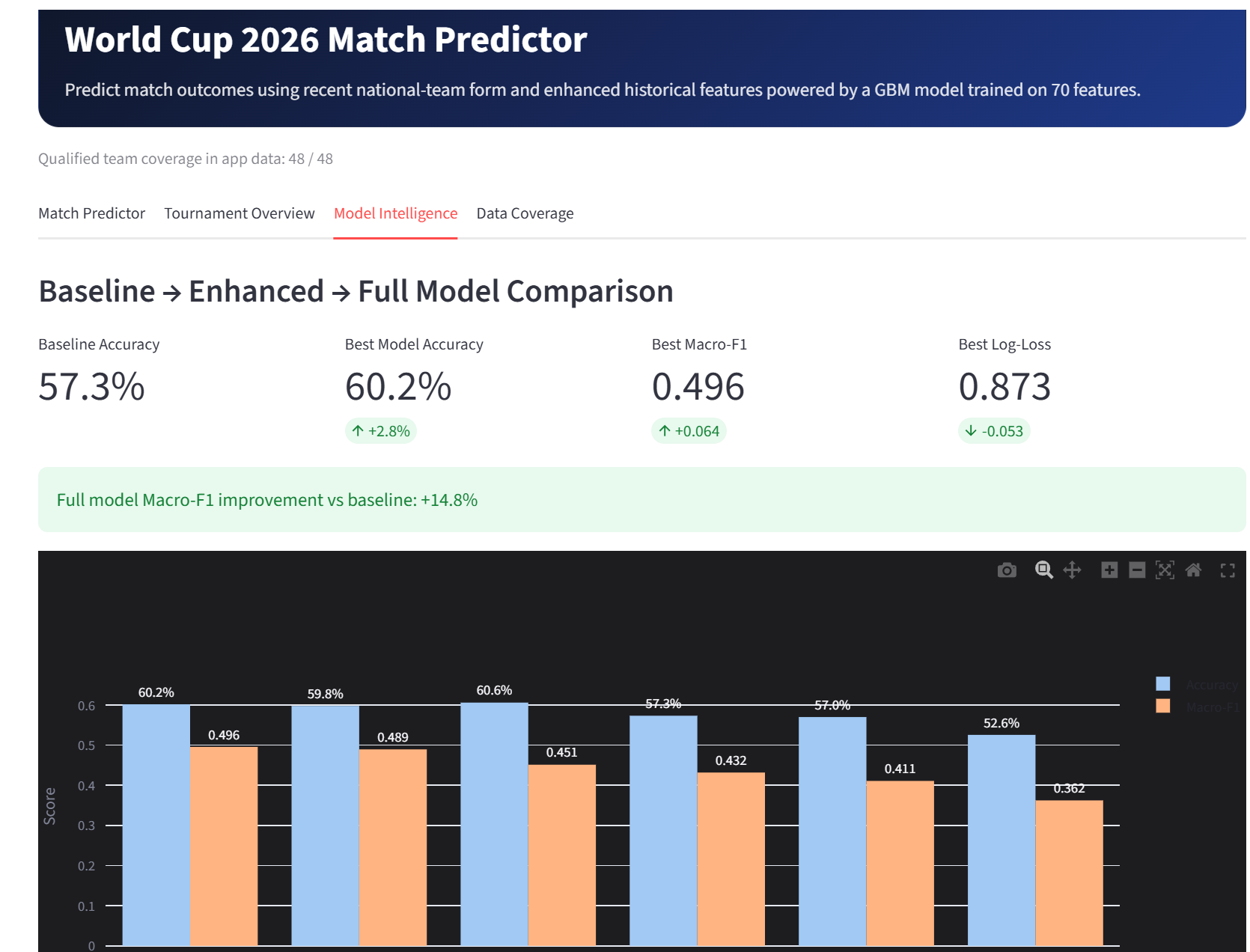
Model Intelligence
-
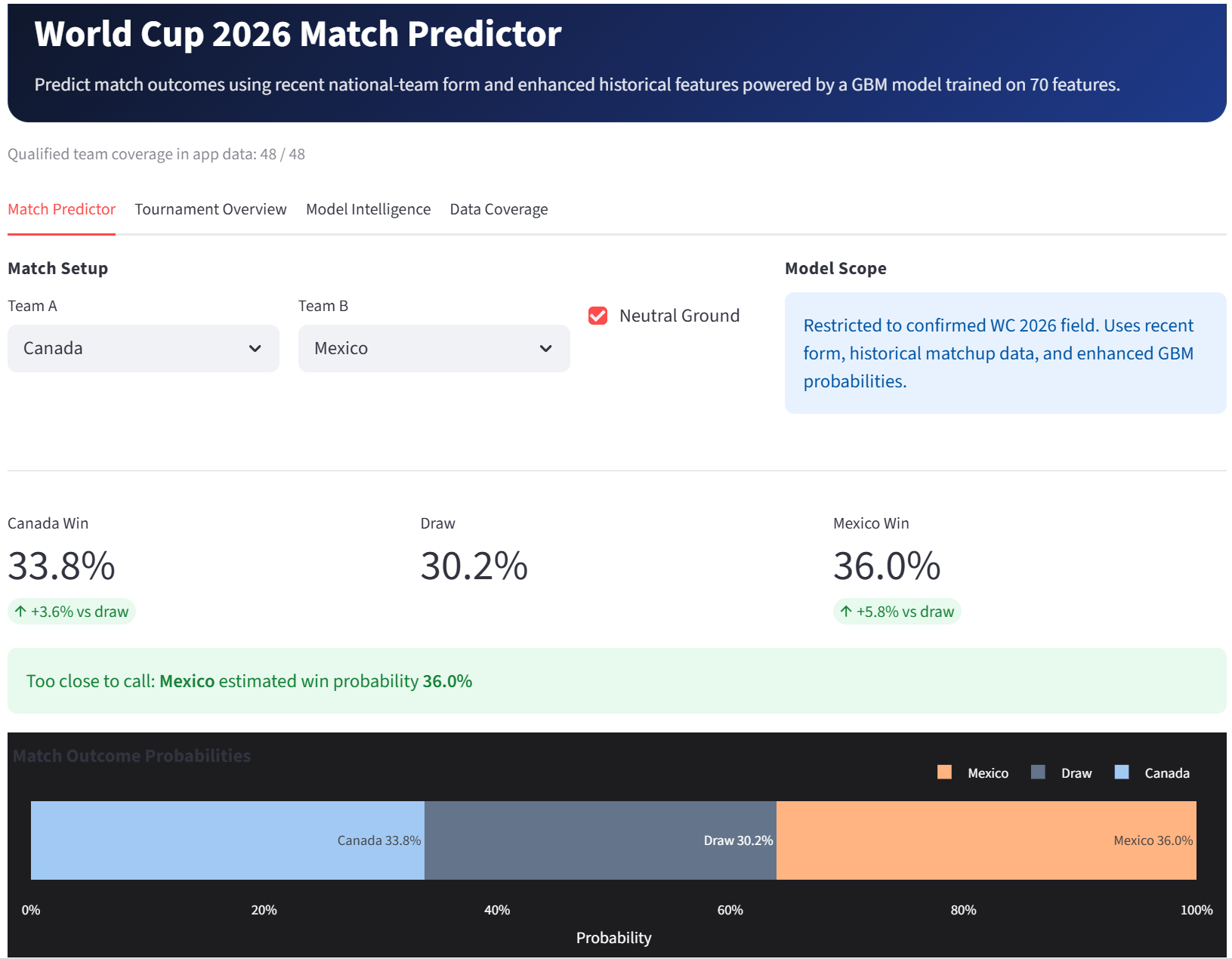
Match Predictor
-
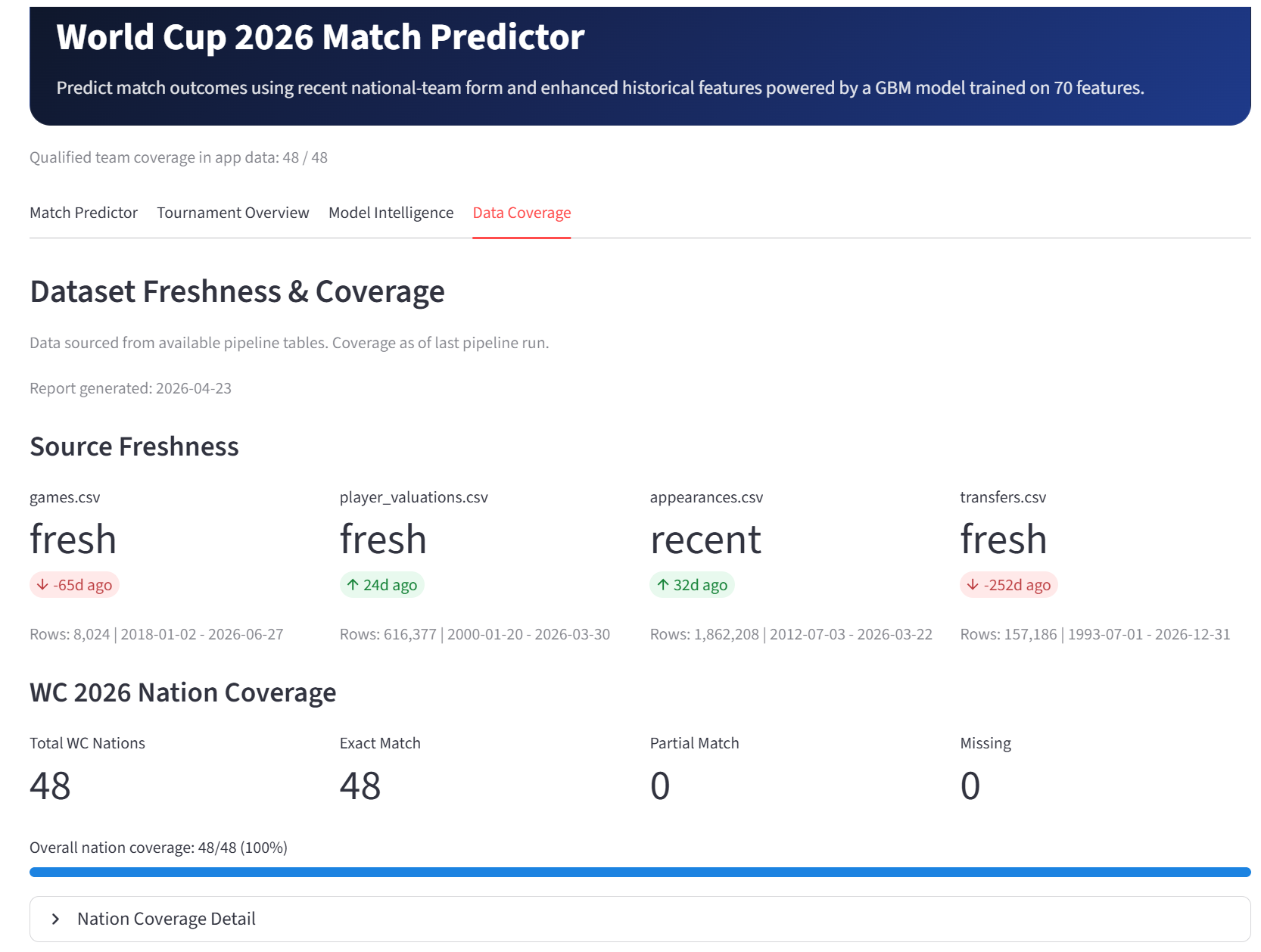
Data Coverage
-
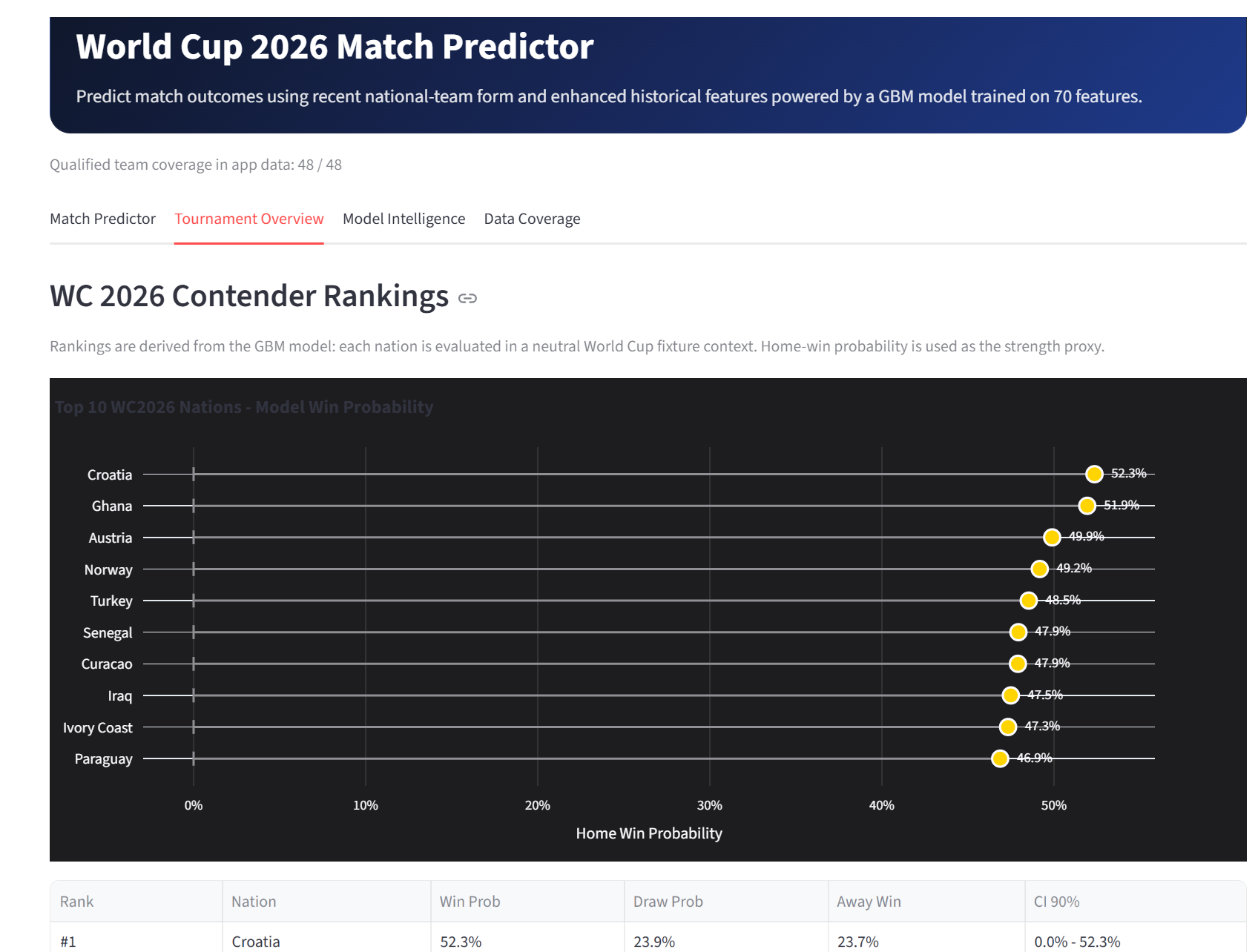
Tournament Overview
Inspiration
We wanted to build something that felt genuinely AI-native rather than just a static analysis notebook. The 2026 World Cup was the perfect setting: it is globally recognizable, outcome-driven, and full of debate. Instead of casually asking, "Who is the favorite?", we wanted to see whether we could build a full prediction system inside Zerve that goes from raw football data to engineered features, trained models, and a deployed interactive app.
What it does
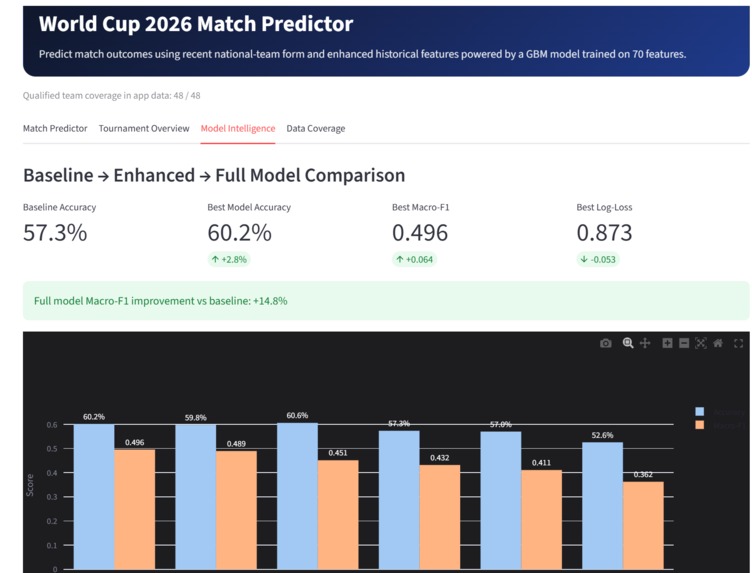
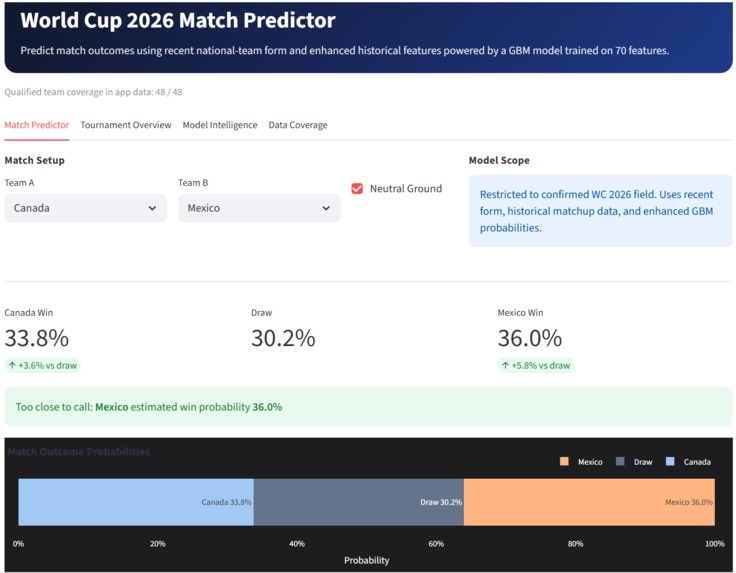
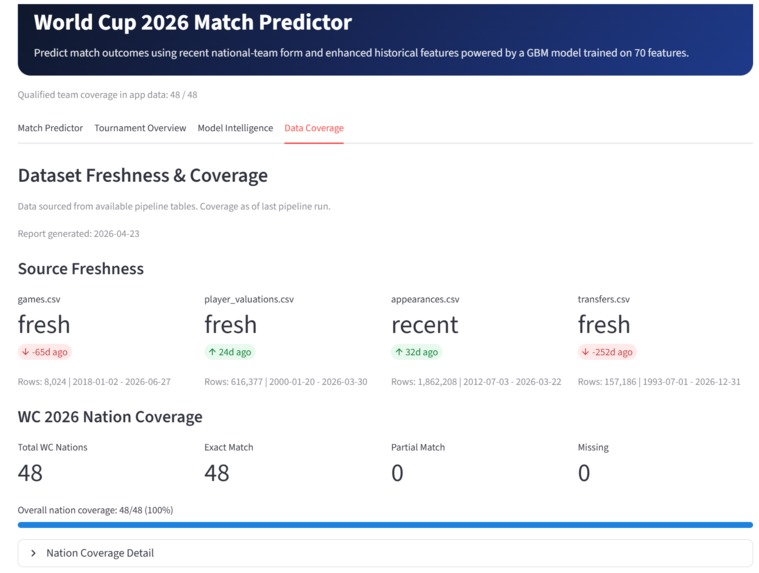
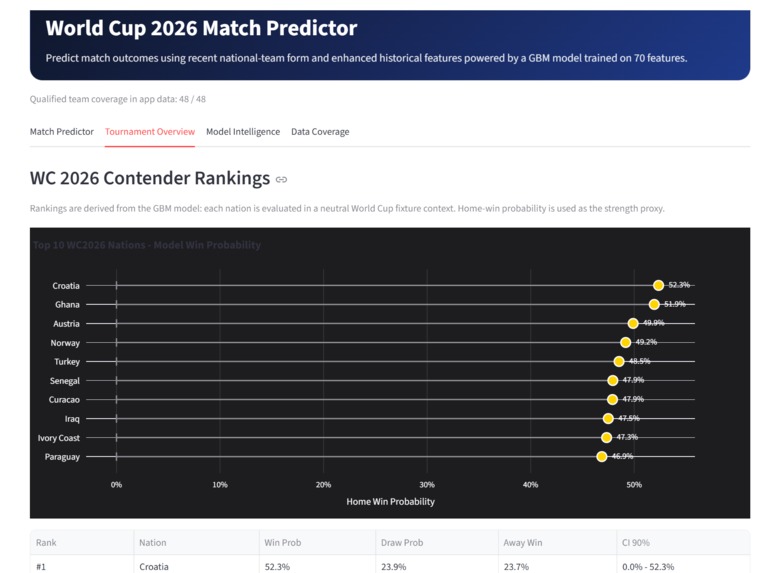
This project is an end-to-end football forecasting system built in Zerve, with World Cup 2026 as the flagship module. The deployed app allows users to select matchups among the qualified teams and view win, draw, and loss probabilities, recent-form comparisons, head-to-head history, contender rankings, model comparison, feature importance, and data coverage information.
Under the app, the project includes a modular pipeline for:
- ingesting and standardizing football data
- resolving team-name mismatches across sources
- engineering form, head-to-head, competition, player-value, appearance, lineup, transfer, and country-context features
- validating feature coverage
- training and comparing baseline, enhanced, and full models
- preparing app-ready assets for deployment
How we built it
We built the project directly in Zerve using a block-based workflow. The pipeline starts from raw football tables and moves through cleaning, feature engineering, model training, model comparison, and app deployment. One of the strengths of the project is that the same environment is used for both analysis and product delivery.
The modeling workflow combines:
- recent team form
- historical head-to-head signals
- competition context
- squad-value proxies
- transfer activity
- broader football context features
The final app is deployed as a Streamlit experience and designed to be usable, not just analytical.
Challenges we ran into
The hardest part was not training a model, but making the whole system coherent end-to-end. Football data has inconsistent team naming, mixed source structures, and multiple levels of granularity. We had to resolve naming mismatches such as national-team aliases, align feature contracts between training and deployment, and make sure the deployed app was consuming the same model outputs and feature structure produced upstream.
Another challenge was balancing ambition with stability. It is easy to keep adding more signals, but much harder to keep the pipeline reliable, explainable, and deployable. I focused on building something that was modular, transparent, and actually runnable inside Zerve.
Accomplishments that we're proud of
We are most proud of turning a football forecasting idea into a complete, working product inside one Zerve workflow. Instead of stopping at model training, the project now includes ingestion, cleaning, feature engineering, model comparison, app asset preparation, and a deployed interactive application.
We are also proud that the project is transparent rather than purely predictive. The app does not just output win probabilities. It also exposes recent-form comparison, head-to-head context, contender rankings, model comparison, feature importance, and data coverage information, which makes the system more interpretable and more useful to end users.
Another accomplishment is that the workflow is genuinely AI-native. The project was developed iteratively in Zerve blocks, with the agent assisting in writing code, debugging issues, refining feature pipelines, and helping move from raw data to a usable deployed product.
What we learned
We learned that building a useful sports prediction system is as much about system design as it is about modeling. Reliable feature engineering, naming consistency, validation, and deployment contracts all have a major impact on the final quality of the product.
We also learned that richer football prediction comes from combining multiple layers of signal. Recent form matters, but matchup history, competition context, squad-strength proxies, and transfer signals all help make the model more credible and stable than a simple results-only approach.
Finally, we learned how effective an AI-native workflow can be for data science projects. Zerve made it possible to iterate across the full lifecycle in one place instead of splitting work across disconnected notebooks, scripts, and deployment tools.
What's next for World Cup 2026 Match Predictor
The next step is to expand the current World Cup 2026 experience into a broader international football prediction system. The current app already provides the World Cup-facing module, but the underlying pipeline can be extended to support a more general national-team prediction product.
We also want to strengthen the data layer with more official and higher-frequency tournament context, such as FIFA rankings, World Cup schedule metadata, and richer squad availability signals. That would make the forecasting layer more responsive and improve trust in the model outputs.
On the product side, the long-term goal is to evolve this from a single tournament-focused app into a modular football analytics product, with World Cup 2026 as the flagship experience and broader national-team forecasting as the next major expansion.
Built With
- boosting
- data
- football
- gradient
- kaggle
- numpy
- pandas
- plotly
- python
- scikit-learn
- streamlit
- zerve

Log in or sign up for Devpost to join the conversation.