-
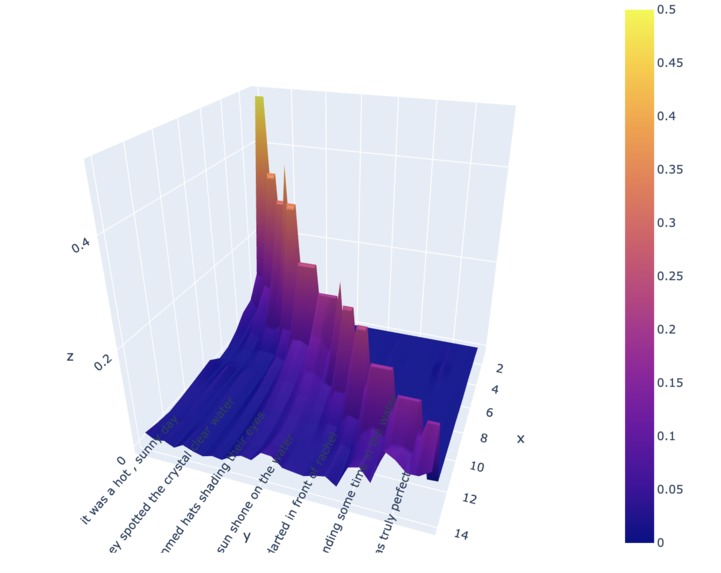
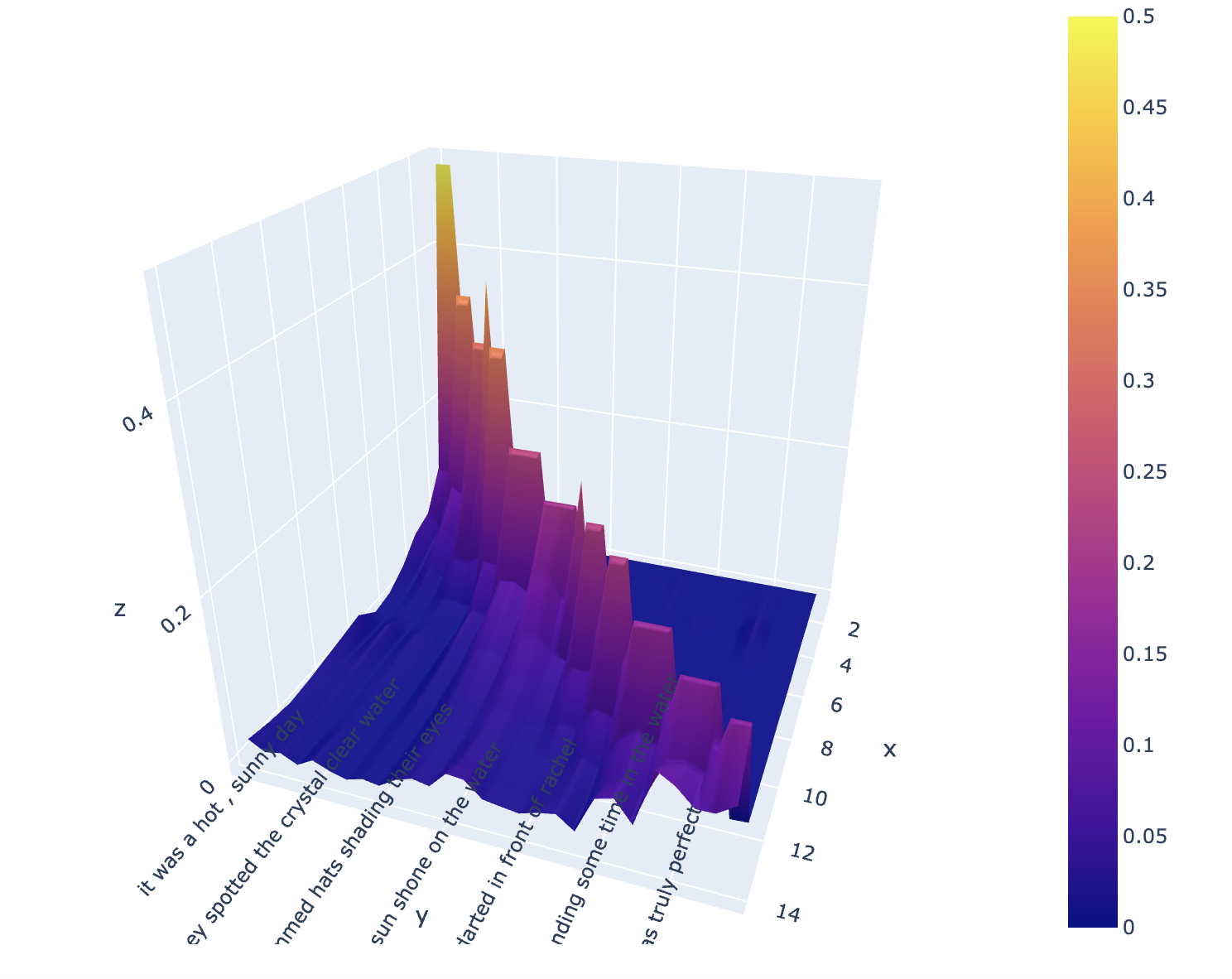
An example mapping the predictions our model generates between propositions in a text
-
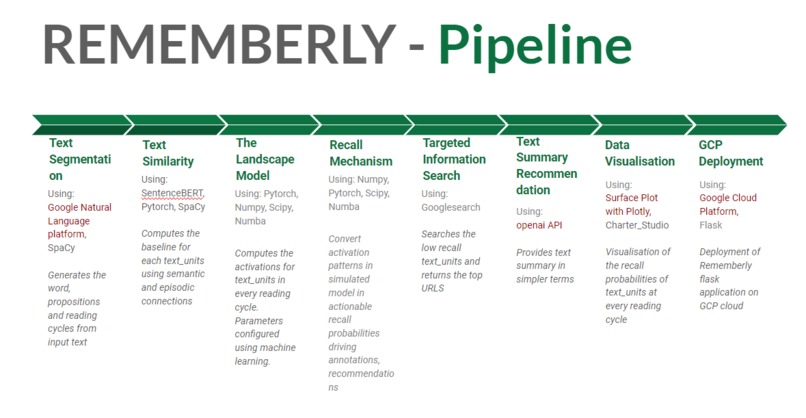
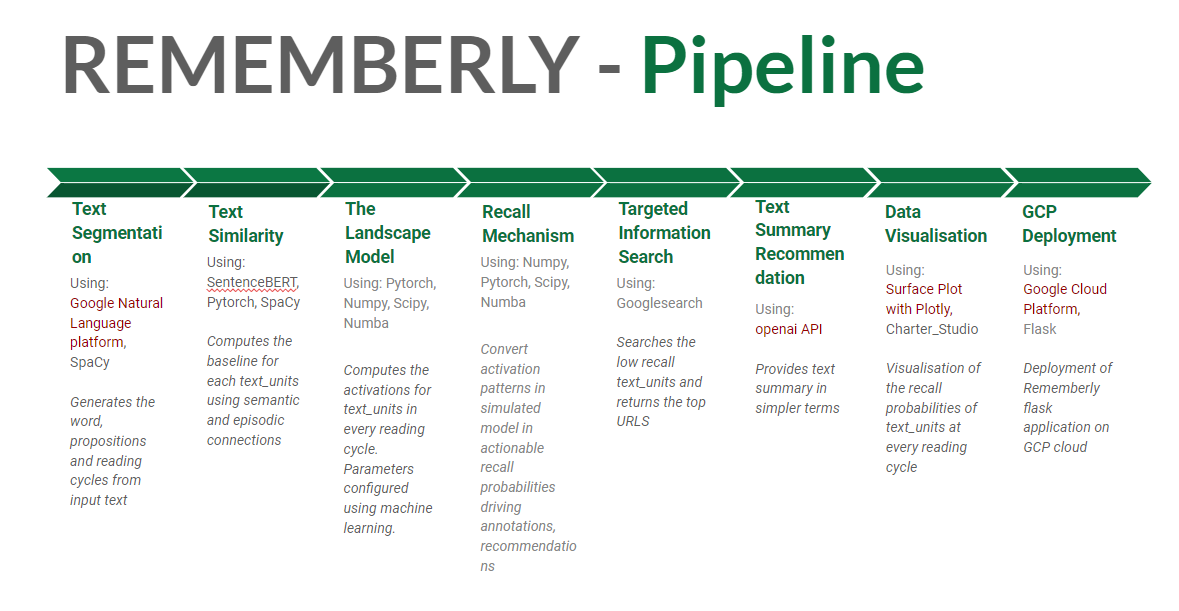
Rememberly Pipeline outline
Rememberly
In the world of science fiction, AI systems execute esoteric simulations to anticipate and react to your every thought and move - the stuff of nightmares. With our project, we imagine how such a system might work in the context of education - anticipating where learners might need extra attention, and addressing that need efficiently. We prototype an end-to-end platform that integrates a computational cognitive model of reading comprehension with cutting-edge machine learning for natural language processing to:
- Preprocess any arbitrary text for simulation in our cognitive model
- Predict the representations of the text that readers might build as they read it, identifying potential knowledge gaps
- Annotate the text with supplementary explanations and resources to address anticipated gaps and optimize for educational outcomes
- Explain the basis of our recommendations with beautiful, interactive landscape visualizations of model state evolution across the course of simulation
- Validate and update model parameters using data collected across diverse experimental contexts
The project has lots of rough edges and will need further work to realize all these objectives seamlessly, but we managed to draft working code that prototypes each one these functionalities inside a dynamic, interactive web application.
Inspiration
Whether you’re an educator or a learner, trying to write up a compelling social media post, or doing your best to engage a community with important news events, you're thinking about how your work is going to come across. Will everything come through?
We can imagine an educator is preparing article, or writing a textbook, or has assigned students to read a certain text - maybe from the web, maybe a textbook chapter, maybe an academic paper. The educator is trying to decide which concepts from the paper is important for review; they don't have the resources to review it all. One factor of course is importance: they'll want to prioritize important ideas! But maybe they can't even cover every important idea. Another big factor is how much help students might need to really grasp and memorize the concepts. That's where a model of human memory for text might come in.
The various sidebars and figures added in your introductory econ textbook were selected and generated by a careful human author to emphasize content they thought needed it. With our model and platform built around it, these can be suggested automatically. The model identifies where extra emphasis may be worthwhile, while the OpenAI API helps find and summarize information that suggests exactly that necessary elaboration.
Along with generating this enhanced experience, we can explain our enhancements by visualizing how we predict those enhancements will sharpen a reader's understanding of the text, relative to a baseline. The result is an enhanced educational or content production experience generatable automatically from an arbitrary text.
Important Dependencies
See our attached project pipeline visualization or our Github repository for more details about how we built this.
Google Cloud Platform. We leverage GCP’s series of modular cloud services at various points along our pipeline. A GCP virtual machine hosts our web application and the Google Natural Language platform helped prototype our tokenization and preprocessing of text data.
OpenAI API. Wielding the mnemonic theory of elaborative encoding, we develop prompts for OpenAI API to elaborate on information singled out as cognitively vulnerable by our model. We try to annotate vulnerable text with this generated or searched-out text to facilitate understanding and later recall.
Plotly. We utilize Plotly to develop rich, multi-dimensional explorable visualizations of the pattern of activations anticipated by our model as users read texts.
sentenceBERT. A machine learning model that finetunes the BERT language model to achieve state of the art performance at predicting the semantic similarity of sentences.
Pytorch and Numpy. We wield these libraries to translate our model from its specification in an academic journal article into working code with parameters that can be trained against data.
Spacy. The open-source software library for advanced natural language processing buttresses tools for open information extraction, enabling us to model comprehension and recall of information in text at the resolution of individual facts.
Other dependencies: numba to make code fast, scipy.optimize optimization library to fit parameters, flask to glue together our web application, Charter studio to host our Plotly visualization.
Important Dependencies
Yeari, M., & van den Broek, P. (2016). A computational modeling of semantic knowledge in reading comprehension: Integrating the landscape model with latent semantic analysis. Behavior research methods, 48(3), 880-896.
Karpicke, J. D., & Smith, M. A. (2012). Separate mnemonic effects of retrieval practice and elaborative encoding. Journal of Memory and Language, 67(1), 17-29.
Cutler, R., Palan, J., Brown-Schmidt, S., & Polyn, S. (2019). Semantic and temporal structure in memory for narratives: A benefit for semantically congruent ideas. Context and Episodic Memory Syposium.
Yeari et al (2016) updates the landscape model of reading comprehension with a specification of how to configure most of its parameters using latent semantic analysis. However, the model is not publicly available and cannot effectively simulate comprehension above the unit of the individual world. We build our own implementation that builds slightly on these ideas.
The concepts of retrieval practice and elaborative encoding form the foundation of our recommendation engine. By rephrasing and elaborating on vulnerable content in a text, we could be sure we were reinforcing people’s memories of parts of the text that might otherwise be left out.
Data to help validate and fit model parameters was shared from a separate research project carried out by Cutler et al (2019).
Some Challenges We Ran Into
Time constraints. Thirty-six hours in hand and a long list of “To Do’s” to accomplish the project with a team of majority beginner hackers located across the world was a challenge. To address this, we were careful to modularize each component of the pipeline so that each could be worked on asynchronous. Still, the final integration step was hard, and not fully realized.
Constructing Prompts for OpenAI. The Open AI API almost feels like MAGIC. It’s wonderful how easy and simply it is to use the API. The challenge in this area was to identify the right prompt to provide us the desired results consistently. We realised that the Open AI output was better for larger sentences rather than few words.
Model translation and fitting. English-language specifications of a model as complex as the landscape model of reading comprehension took some effort to clarify and make sense of. A lot of domain-specific background research was necessary to identify an accurate translation and make sure it fits well to data. See our validation notebook in the project repo for more information.
Validating the entire pipeline. With lots of moving parts, it was easy for any one component to go wrong, impacting downstream outcomes. These challenges were especially compounded by the threat of differences between our programming environments. Along with modularizing each step of the data pipeline to isolate bugs, we wielded the nbdev framework to help organize tests, documentation, and our function library concurrently. The Google Cloud Platform helped ameliorate environment differences: we could debug our app in a single context accessible to every teammate via the Cloud.
Accomplishments that we're proud of
- The rememberly web application
- Implementation of Landscape model
- Visualization of the model that provides an overall idea of the transitions in the recall probabilities
- Usage of OpenAI to provide text summary in the application
- Managing to create a working prototype in 36 hours!!
What we learned
With the majority of the team (3/4) being first-time hackers, the learning curve was definitely steep!
Aditya - Leveraging SentenceBERT to implement a transfer-learning version of the Landscape Model, gCloud and GCP app deployment, Rahul - Creating a Flask app, Using Git, Creating a VM Suchetha - Computational Modelling for Semantic Analysis with Landscape Model, OpenAI, Visualisation with plotly, Creating a Flask App Jordan - The wonders of pytorch, plotly, openai API; previously used far less advanced libraries for model implementation, visualization, application and expect to use these going forward
What's next for Working
- Creating a fully functioning web application that highlights text based on recall probabilities
- Use Recommendation AI to record user activity and provide personalised recommendations in the form of text summary or links
Built With
- flask
- gcp
- html
- javascript
- jupyter
- openai
- python
- sentencebert

Log in or sign up for Devpost to join the conversation.