-
-
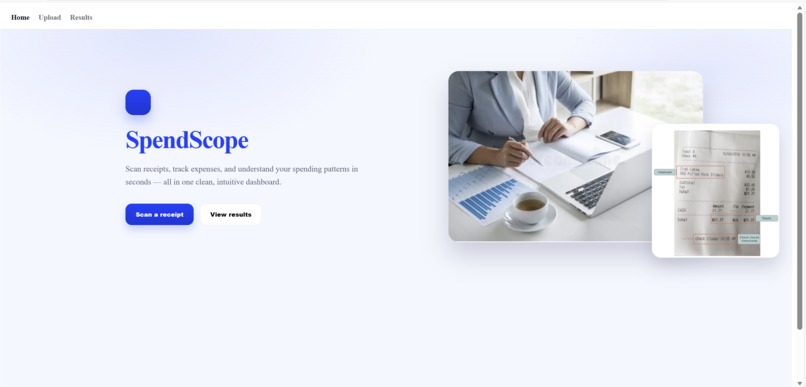
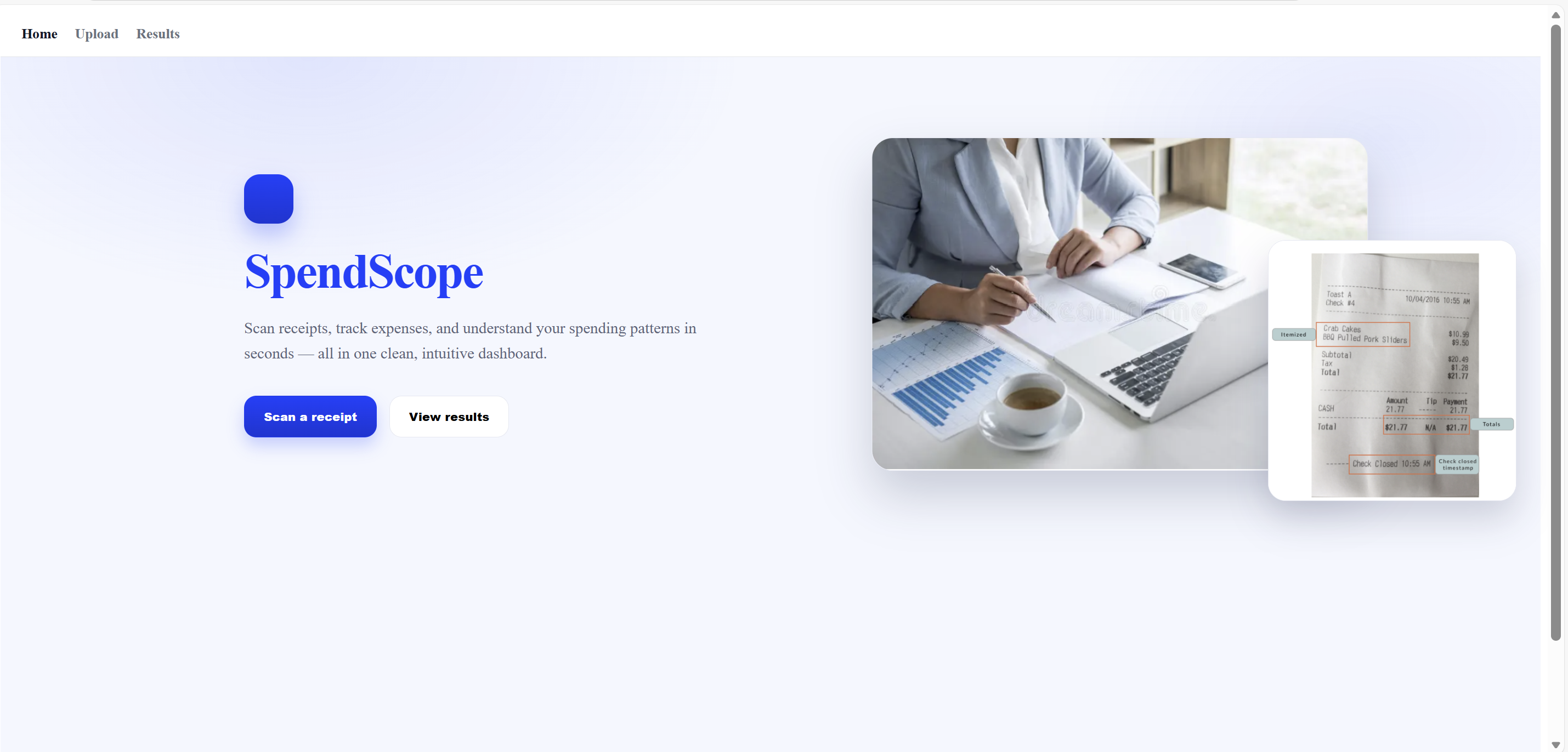
Main Page
-
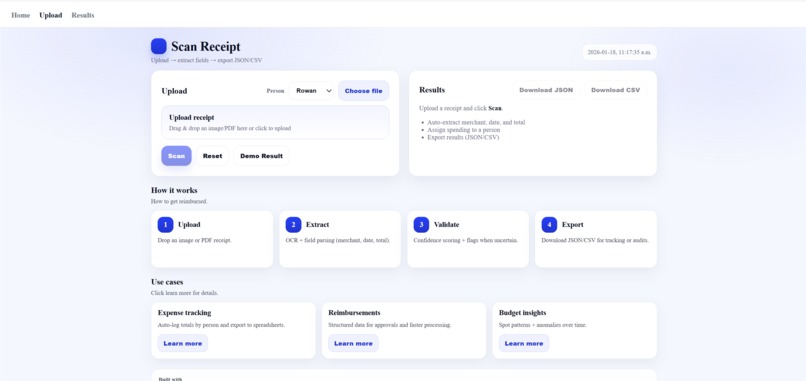
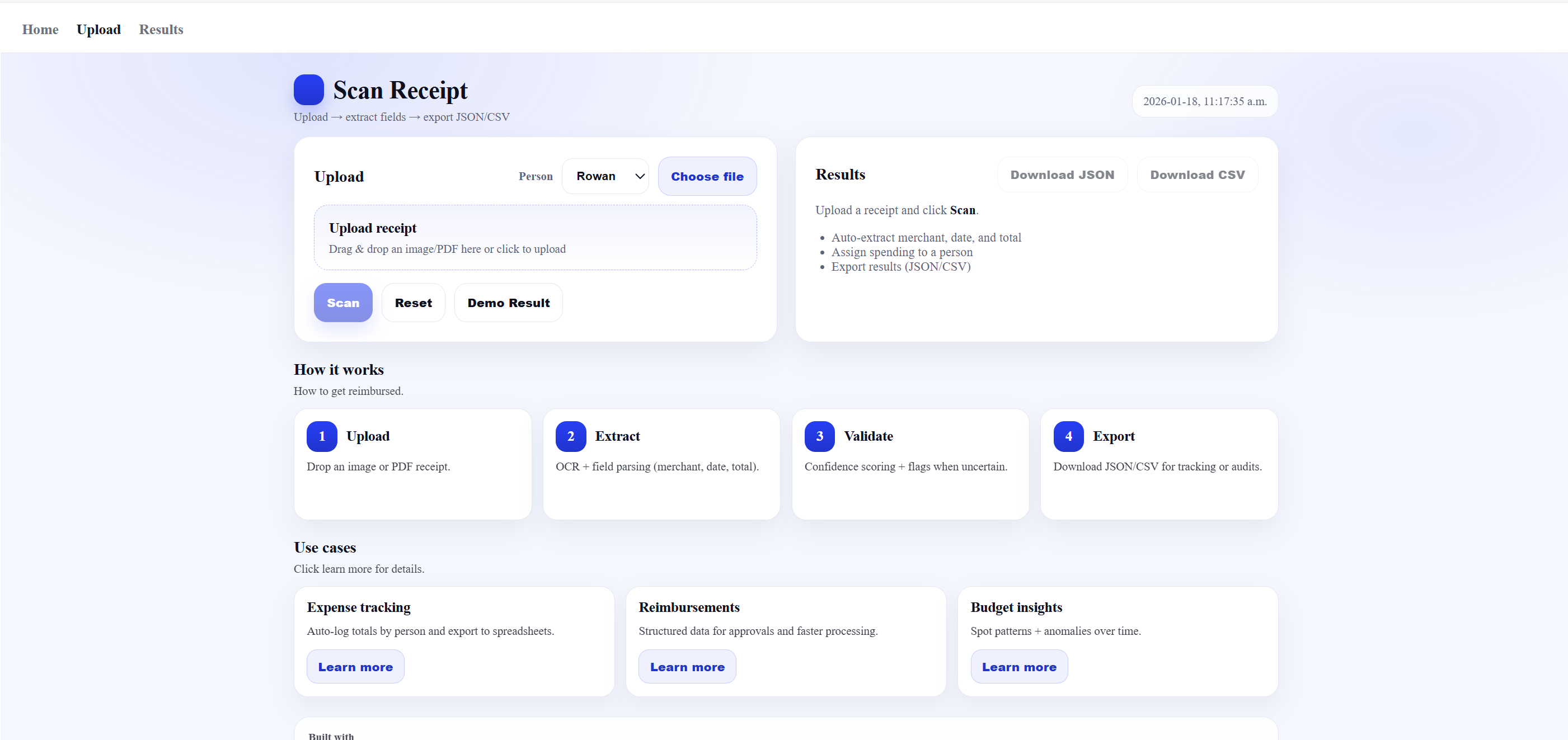
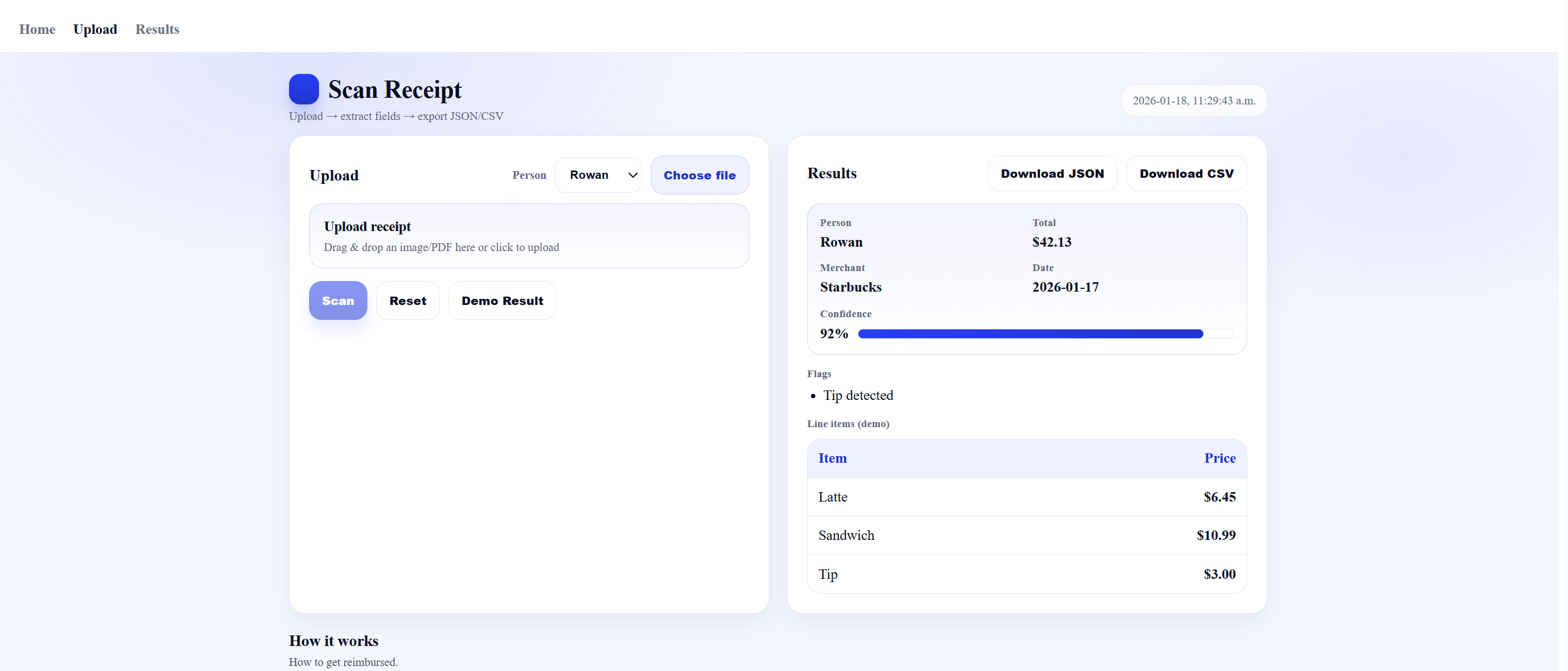
Upload Page
-
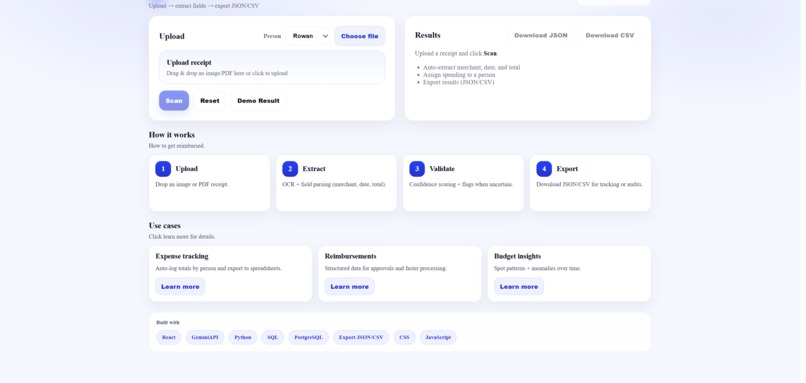
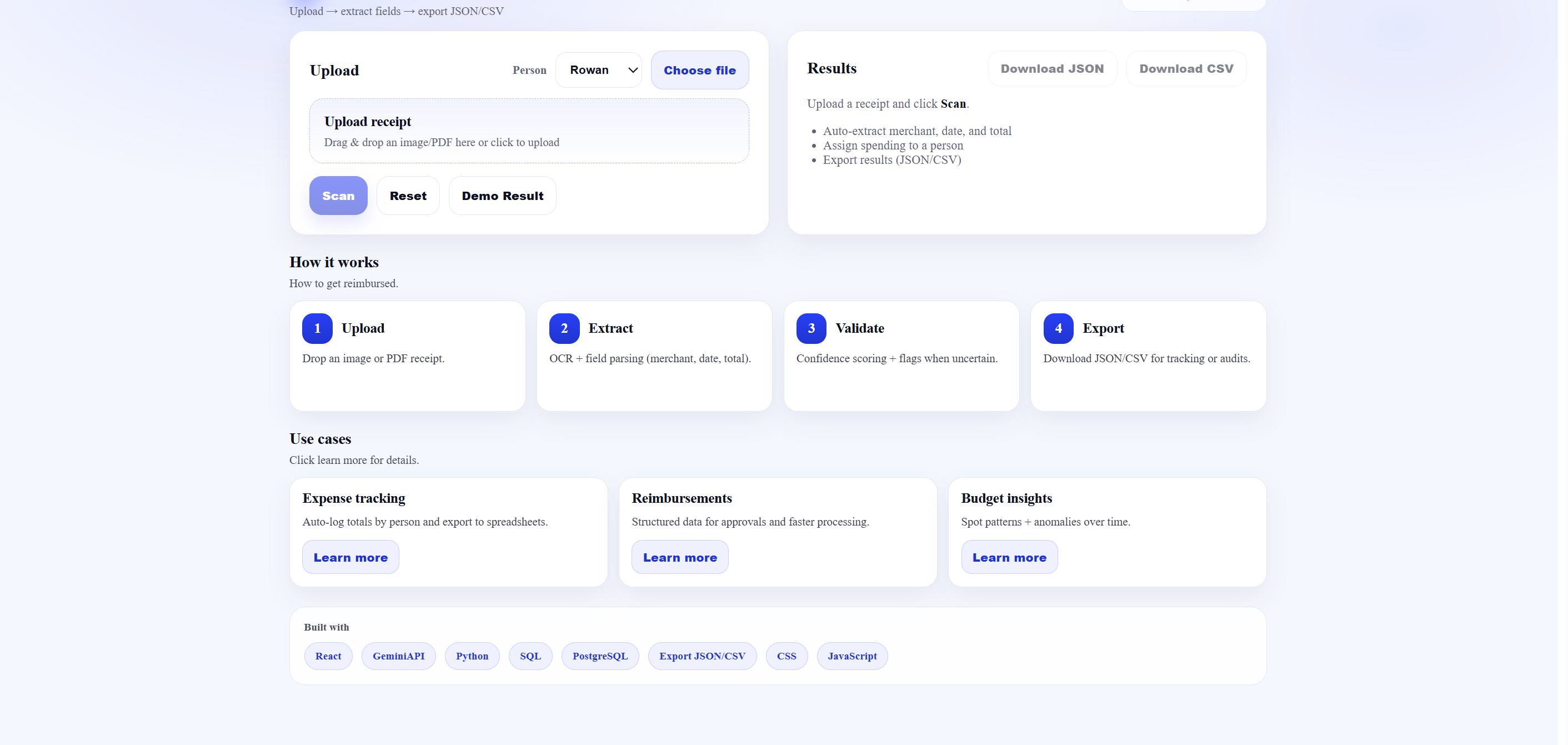
Bottom Upload Page
-
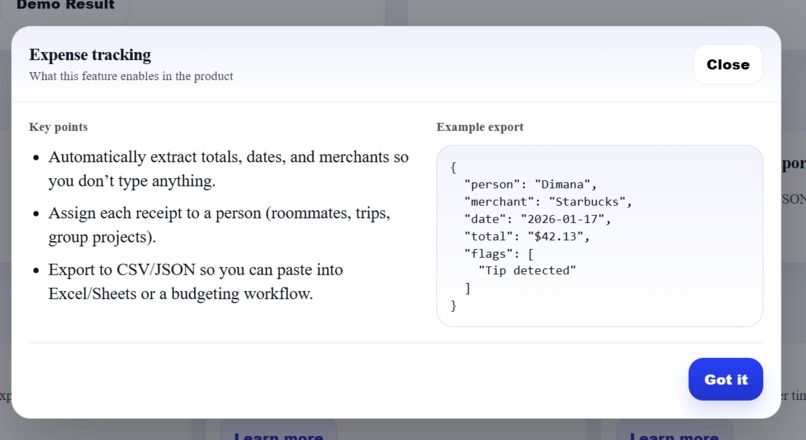
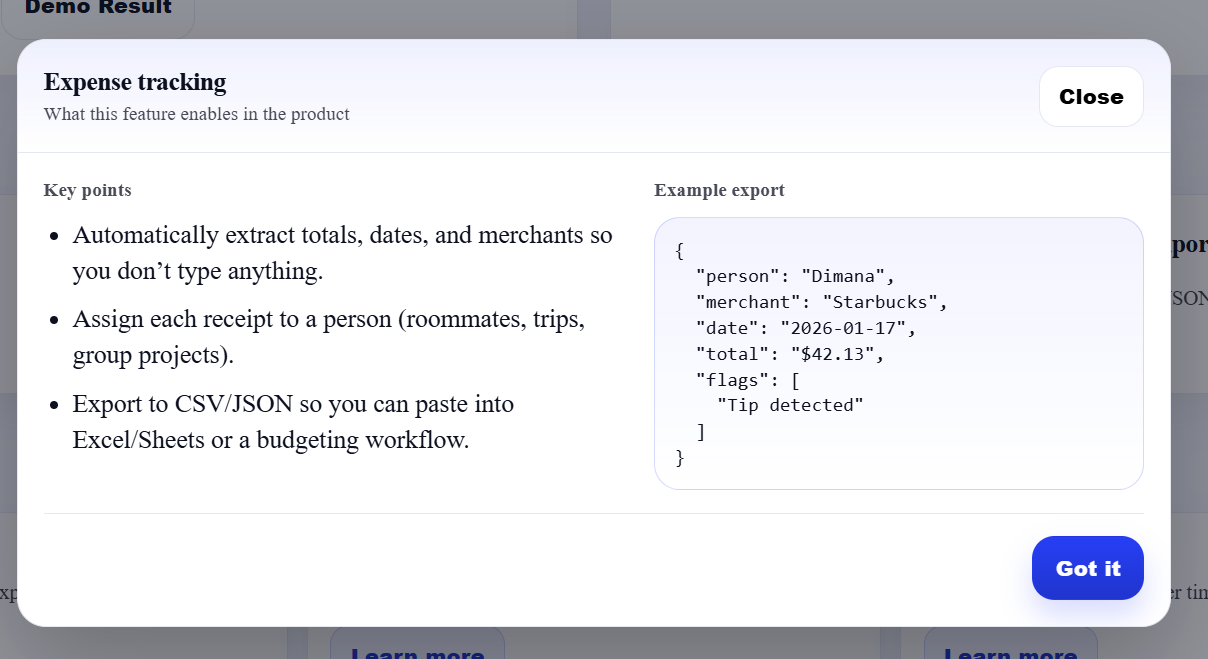
Learn More Button
-
View Result Button
-
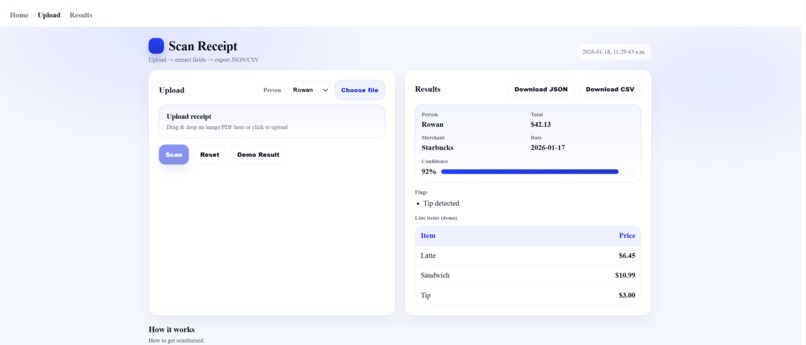
Demo
-
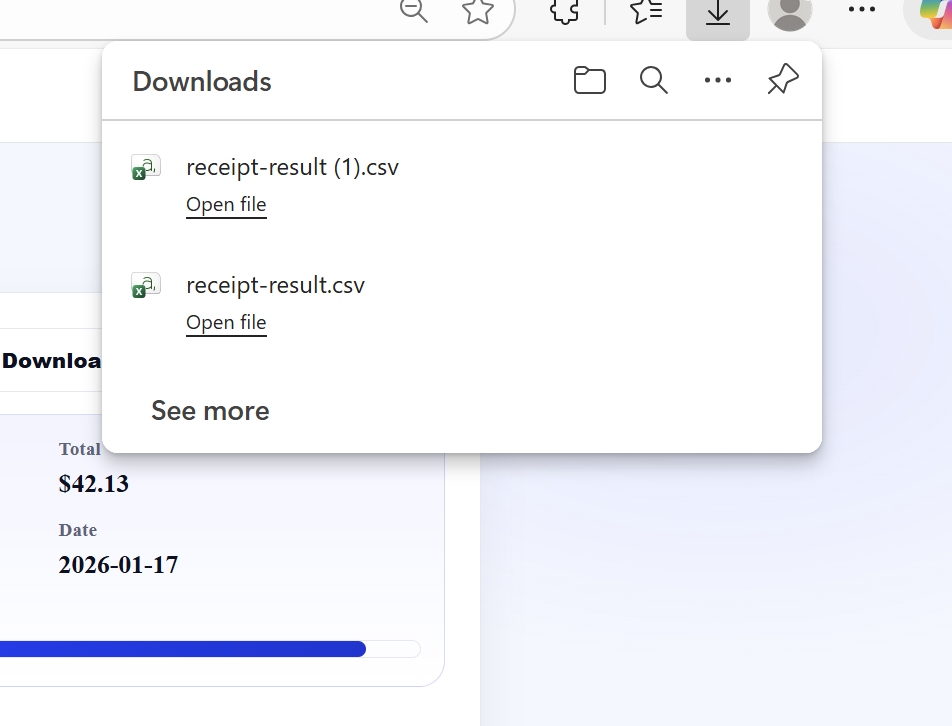
Downloads Receipts to Excel
-
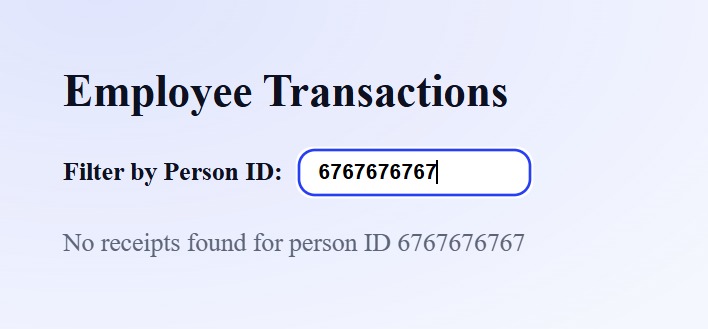
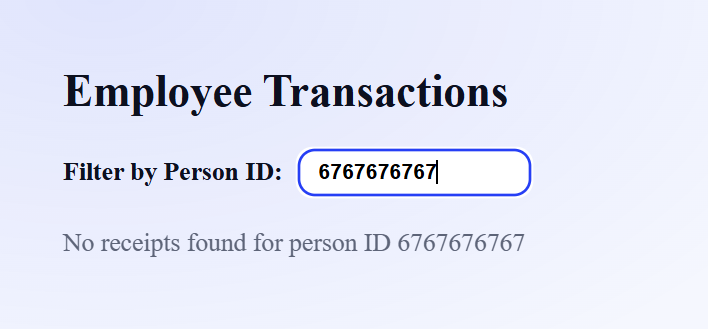
Employee ID Example
Inspiration
Managing corporate expenses is still done manually by many large organizations, making the process time-consuming and highly error-prone. Teams waste valuable time uploading receipts, re-entering amounts, and correcting mistakes. We wanted to build SpendScope to automatically scan receipts, extract key information, and make corporate expense tracking faster, cleaner, and more reliable.
What it does
SpendScope automates corporate expense processing by allowing users to upload receipt images and convert them into structured, usable data. Once a receipt is scanned, the system extracts key information such as the total amount and prepares it for storage and further processing. This significantly reduces manual data entry and minimizes human error, laying the groundwork for faster and more reliable expense tracking for organizations.
How we built it
We built SpendScope using a full-stack approach. The front end was developed with React, along with HTML, CSS, and JavaScript, to create a simple and intuitive interface for uploading and scanning receipts. On the back end, we used Python to handle receipt processing and integrated Optical Character Recognition powered by the Gemini API to extract information from receipt images. Extracted data is stored and managed using PostgreSQL and SQL, and the system is exposed through APIs. The application is deployed using DigitalOcean. The development was highly iterative, with frequent debugging, refactoring, and testing as we connected each component into a complete end-to-end workflow.
Challenges we ran into
One of the biggest challenges was working with unfamiliar technologies, particularly on the front-end side, while still making meaningful progress within the limited hackathon timeframe. Integrating the front end with the back end introduced additional challenges, including managing file paths, APIs, and data flow between components. Debugging OCR behaviour and handling different receipt formats required experimentation and quick problem-solving. Additionally, none of us had previously created or managed a database using PostgreSQL and SQL, which added a learning curve. Coordinating work across the team and resolving version control conflicts under time pressure further tested our collaboration and communication skills.
Accomplishments that we're proud of
Despite limited prior front-end experience, we quickly learned and shipped a functional and responsive user interface under tight time constraints. We successfully built an end-to-end pipeline that takes a receipt from upload to automated data extraction and storage. Most importantly, we collaborated effectively under hackathon pressure and delivered a fully functional prototype by coordinating tasks, debugging efficiently, and solving issues in real time.
What we learned
Throughout the hackathon, we learned how to rapidly pick up new frameworks and technologies while maintaining development momentum. We gained hands-on experience with front-end and back-end integration, ensuring smooth communication between APIs, data storage, and the user interface. We also strengthened our debugging and version control skills in a team environment, learning how to resolve conflicts and deploy fixes quickly. Above all, we learned the importance of clear communication, task delegation, and adaptability when working under strict time limits.
What's next for Work in Progress
Next, we plan to expand data extraction to include additional fields such as expense category, business unit, and spending breakdowns per employee or per year. We aim to introduce more corporate-focused features, including expense categorization, approval workflows, and analytics dashboards to improve financial visibility. On the product side, we want to further enhance the UI/UX for faster uploads and clearer insights. Finally, we plan to explore integrations with accounting and reimbursement platforms to make SpendScope a seamless part of existing corporate expense workflows.










Log in or sign up for Devpost to join the conversation.