-
-
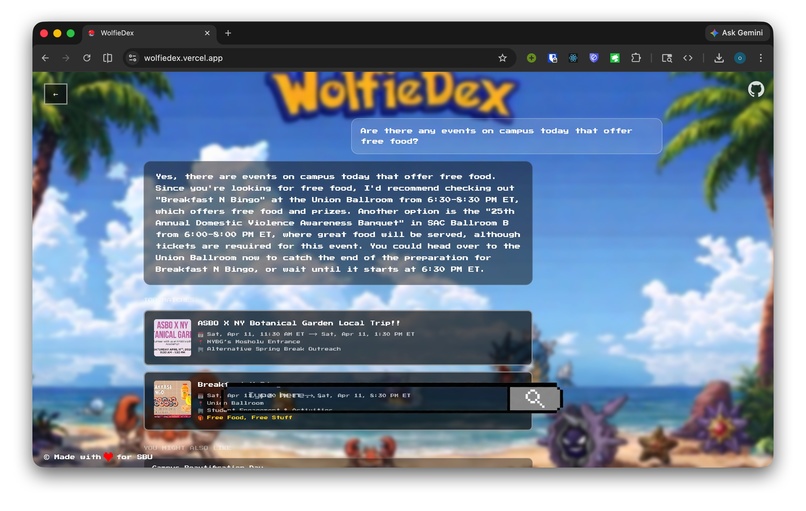
Search results
-
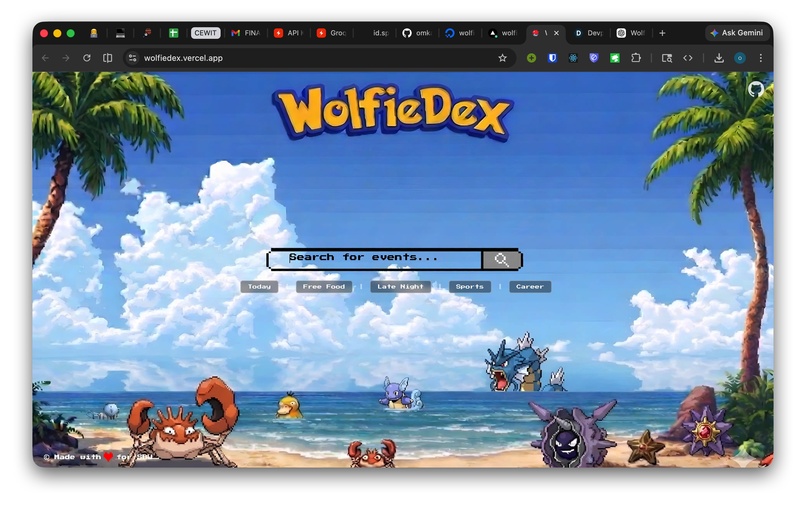
Home page
Inspiration
Campus event platforms are full of information, yet students still struggle to find the events that actually matter to them.
The problem is not missing data. The problem is mismatch. Students search by intent, mood, and outcome, while most event systems rely on filters, tags, and exact wording. Someone looks for "free food," while the listing says "complimentary catering." Someone asks for "something chill tonight," while the event page is written in formal campus language. Technically, the information exists. Practically, it remains hard to discover.
WolfieDex began with that gap. Stony Brook already had SB Engaged as the source of truth for campus events. What was missing was a retrieval layer that could interpret the way students naturally ask.
What It Does
WolfieDex is an intelligent event finder for Stony Brook University.
Students can ask natural questions such as:
- "Are there any chill coding meetups tonight?"
- "Anything Japanese-themed happening this week?"
- "Where can I get free food on campus?"
Instead of depending on exact phrase overlap, WolfieDex interprets the meaning behind the request and retrieves the most relevant events. It provides a direct response, highlights the strongest matches, and surfaces similar events that may still fit the student's intent.
The point is not to make event search feel conversational for its own sake. The point is to make it work the way students already think.
How We Built It
WolfieDex is a Retrieval-Augmented Generation application built around two separate pipelines: one for indexing events effectively, and one for answering student queries effectively.
Tech Stack
- Frontend: Next.js App Router, React, Tailwind CSS, deployed on Vercel
- Backend: Next.js serverless APIs and a Python scraper, deployed on DigitalOcean App Platform
- Database: MongoDB Atlas with Vector Search
- Text generation: Groq API with Llama 3
- Embeddings: Hugging Face Inference API using all-MiniLM-L6-v2
Ingestion and indexing
A background worker continuously pulls live event data from SB Engaged. One of the most important design decisions was to avoid embedding raw event descriptions directly.
Event pages are written for display, not retrieval. They contain noise, inconsistent formatting, and wording that weakens semantic search. Instead of treating the raw event description as the search document, we create a second representation of each event: a dense, search-oriented summary. That summary is embedded and stored as a vector, while the original event content remains intact for display.
That separation between display data and search data became one of the core ideas behind the project.
Query pipeline
At query time, WolfieDex uses HyDE: Hypothetical Document Embeddings.
Rather than embedding a short user query directly, the model first generates the kind of event description that would ideally satisfy the student's request. That hypothetical description is then embedded and used for vector retrieval. This helps bridge the gap between informal student phrasing and the more formal language used in event listings.
MongoDB Atlas then runs $vectorSearch to retrieve the nearest matches. The highest-ranked results are passed into the synthesis stage, where the final response is generated using retrieved event data rather than unsupported guesses.
The vector math
The retrieval step is based on cosine similarity between the query vector and the stored event vectors:
$$ \text{similarity} = \cos(\theta) = \frac{\mathbf{A} \cdot \mathbf{B}}{|\mathbf{A}| |\mathbf{B}|} $$
The math itself is straightforward. The harder problem was ensuring that the vectors represented the right form of the problem in the first place.
Challenges We Faced
The hardest challenge was retrieval quality.
Natural-language event search sounds simple until user phrasing starts drifting away from the source text. Students search by mood, benefit, timing, and context. Event listings are often written in a promotional or administrative style. That gap breaks keyword search quickly, and it also reveals the limits of embedding raw text without carefully designing how information is represented.
That challenge pushed two architectural decisions to the center of the system:
- Multi-representation indexing for cleaner retrieval
- HyDE for richer query understanding
Latency was the next major constraint. The request path involves multiple dependent steps:
$$ \text{HyDE} \rightarrow \text{Embedding} \rightarrow \text{Vector Search} \rightarrow \text{Synthesis} $$
Even when each individual component is fast, the total delay compounds quickly. We had to choose models and infrastructure that kept the system responsive without weakening retrieval quality.
We also ran into deployment constraints. The frontend and ingestion workloads had very different runtime profiles, so infrastructure could not be treated as an afterthought. Keeping the UI on Vercel while moving heavier backend processing to DigitalOcean gave the system the separation it needed.
Accomplishments That We’re Proud Of
WolfieDex addresses the real failure point in campus event discovery: not presentation, but retrieval.
The project now includes:
- A live event ingestion pipeline connected to SB Engaged
- A semantic search layer built on vector embeddings
- A HyDE-based retrieval strategy for vague natural-language queries
- A grounded answer synthesis step tied to actual retrieved events
- A deployed architecture split according to workload instead of convenience
We are also proud that the product feels distinct. The retro interface gives it identity, but the real value comes from designing the system around the retrieval problem first.
What We Learned
The clearest lesson was that useful AI systems depend on good representations.
We learned that:
- the best format for display is often not the best format for search
- retrieval quality depends heavily on preprocessing and indexing decisions
- vague human queries need structure before they can be matched effectively
- generation becomes far more reliable when it is forced to stay grounded in retrieved evidence
- deployment decisions are part of the product, not just implementation details
More than anything, we learned that making a system sound intelligent is easy. Making it retrieve the right thing under messy real-world conditions is much harder, and much more useful.
What’s Next for WolfieDex
The next step is personalization.
Right now, WolfieDex is focused on understanding the query. The next version should also understand the student. That means adding user accounts, learning preferences over time, ranking results with more context, and proactively surfacing relevant events through channels like SMS or email.
The broader direction is clear: move from a tool that answers event questions well to a system that helps students discover the right opportunities before those opportunities are missed.
Built With
- claude
- digitalocean
- groq
- mongodb
- next.js
- vercel

Log in or sign up for Devpost to join the conversation.