


Inspiration
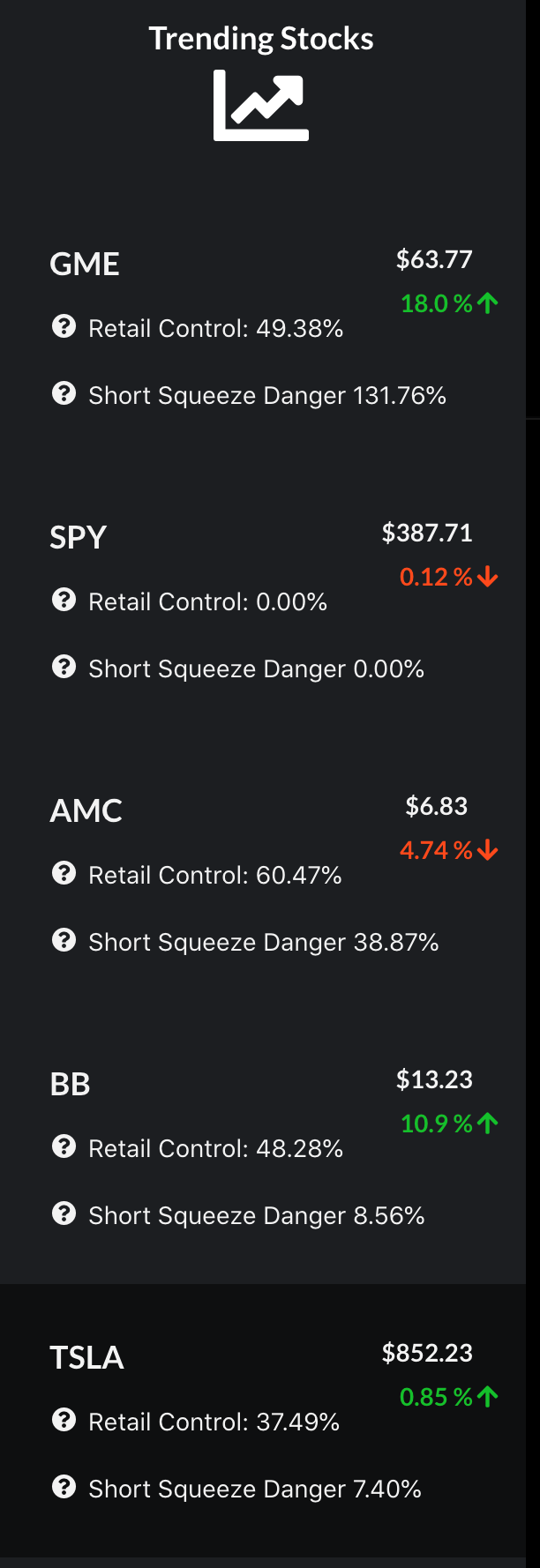
Leading by the post of several reputed Redditors, individual investors contribute to approximately fifty percent of the GameStop market and derive the price of its stocks. This creates a short squeeze cycle which forces hedge funds to sell their shares on GameStop and further increases the stock prices. Upon seeing some abnormal market trends this past week we decided to see if we could use NLP to better visualize and understand the peculiar relationship between social media and the stock market.
What it does
A realistic stock price chart and graph for Reddit predictions on each stock are presented side by side on the same coordinates. For time frames for both charts can be altered synchronically and data points on two charts at the same time are connected by dynamic popup windows. In this way, when users hover on a specific data point in either the stock price chart or the prediction chart, the corresponding data point, data point with the same date and hour, in the other chart will lighten up to allow accurate comparison between realistic stock price and the predictions.
A “bullish score” displays the confidence level in stock, in which a negative percentage represents proper timing to sell the stock and a positive percentage shows profitable opportunities for selling the stock. Furthermore, “bearish score” predicts the danger of upcoming short squeeze and warn hedge fund companies of risky stocks.
We scraped almost 10 MB of data from r/WallStreetBets and used VADER sentiment analysis to assign a bullish or bearish score to each Reddit post. Then using factors like upvotes, karma, and comments we assigned different weights to different posts and aggregated their scores, and graphed them against stock market data, with dynamic visualizations to make it easy to comprehend. The patterns are staggering!
How we built it
We used a homemade python crawler + PushShift API to scrape reddit, Scikit-learn and numy to build our model, and react to display our data. We also used the alphavantage api to grab realtime market data.
Challenges we ran into
Everything! To extract valid information on the nine stocks from the ocean of Reddit posts, our team faced three major challenges: extracting posts related to the nine stocks, transferring linguistic information into numeric indexes for each stock, and distinguishing and grant credits to more reliable posts.
Linguistic information on related stocks is then sentiment analyzed to yield a numeric sentiment score. Then, in order to filter out credible posts, karmas of posters and the number of comments under the posts as well as the sentiment score are the three input factors into a neural network deep learning model. In this way, accurate outcomes of the custom-trained deep learning model are the “bullish score” to predict the profitable movements (buying or selling) of the stocks.
The Reddit API also would not let us scrape and manual scraping got us blocked. We had to use a combination of APIs + clever rate-limiting to grab all the data we needed.
Accomplishments that we're proud of
Because the classic binary classifier NLP model is not enough to predict the stock trend, our team come across a multi-outputs regression model by Convolutional Neural Network (CNN). We learned to train and deploy this CNN model for continuous numeric “bullish score”. Dynamics visualization is also a major part of our accomplishments.
What we learned
React, neural networks, VADER sentiment analysis, chart js, web scraping.
What's next for Wolf of WallStreetBets
The current prediction model for Wolf of WallStreetBets is only limited to nine stocks. For the future, smaller and less well-known stocks will be analyzed and the resources will not be limited to Reddit only. Platforms such as Quora will also be scraped and imported into the system.
All of the codes
FE: https://github.com/yuktmitash21/WolfofWallStreetBets-Frontend BE: https://github.com/yuktmitash21/Crawler Sentiment Analysis: https://github.com/PeggyZhao2/WolfVaderSentimentAnalysis CNN: Not in a pushable state currently. Check back soon!
Built With
- colab
- crawler
- javascript
- jupyter
- python
- react




Log in or sign up for Devpost to join the conversation.