Inspiration
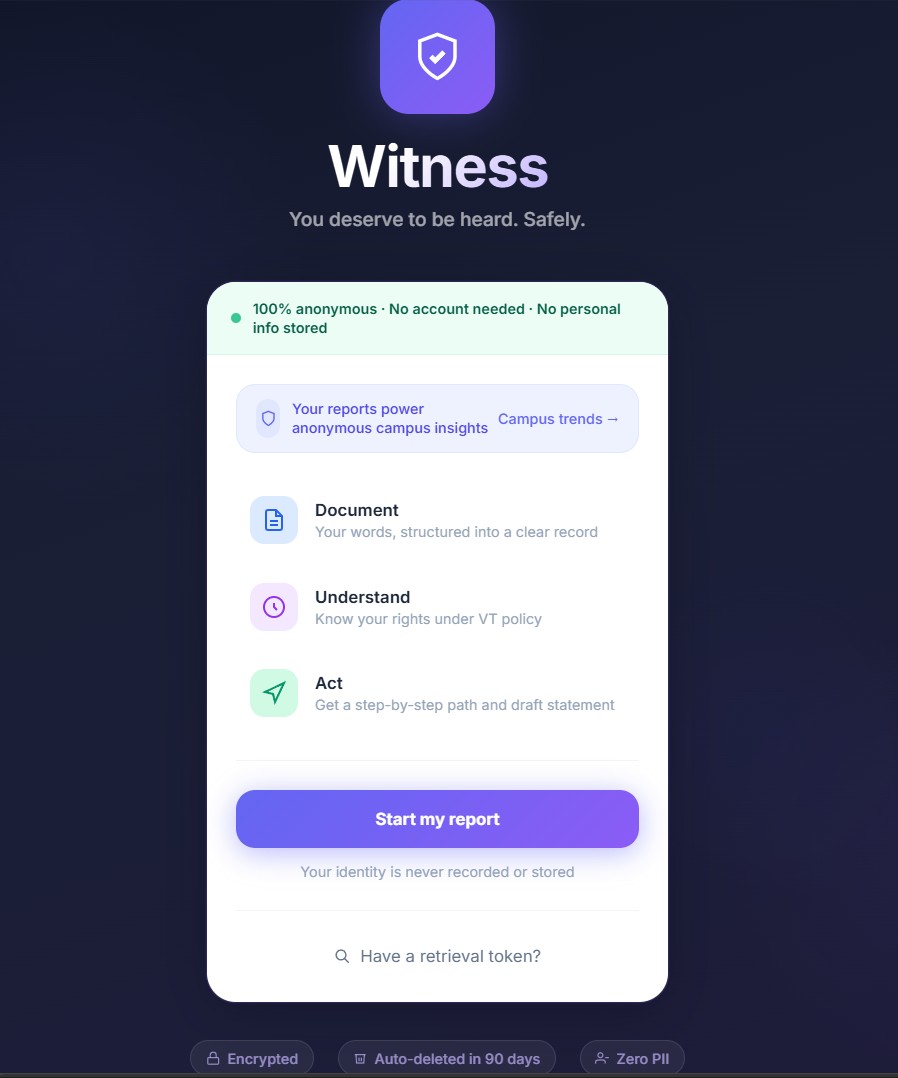
Walking across campus, we kept hearing the same thing from students around us — "Something happened to me, but I didn't know who to tell, or if it was even worth reporting."
The official reporting process at most universities is long, confusing, and intimidating. For students who are already vulnerable after experiencing bias or harassment, that friction is enough to make them stay silent. We wanted to remove every possible barrier between a student and their voice being heard.
That became our north star: what if reporting felt as easy as texting a friend?
What it does
We learned that trust is a technical problem.
Students won't use a reporting tool they don't trust. So we had to engineer trust — anonymous sessions, encrypted storage, auto-deletion, hard-coded routing rules so the AI never invents a phone number or sends someone to the wrong office.
We also learned where not to use AI. Severity scoring, policy routing, and contact URLs are all deterministic — handled by Python rules and static maps, never by the model. Because when a student's safety is on the line, hallucination is not acceptable.
How we built it
We built a three-agent AI pipeline on top of a fully serverless AWS infrastructure.
Frontend: React + Vite, deployed on Vercel as a Progressive Web App — works offline, installs on any phone, no App Store required.
Backend: Four AWS Lambda functions behind API Gateway:
| Lambda | Responsibility |
|---|---|
session |
Issues anonymous Cognito tokens |
process |
Runs all three AI agents |
save |
Encrypts and stores to DynamoDB |
retrieve |
Returns report via QR code |
AI Layer: Claude running on AWS Bedrock with exponential backoff retries. Each agent has a focused system prompt — Documenter, Advisor, Navigator — called in sequence inside the Process Lambda.
Privacy: Two-tier data model. Individual reports encrypt with KMS and auto-delete after 90 days via DynamoDB TTL. Anonymous aggregate counters persist in a separate table — just category, type, severity, location, and month — so campus trends stay visible without any student ever being identifiable.
Challenges we ran into
Challenges We Faced
1. Preventing hallucination where it matters most
The hardest design decision was figuring out which parts of the system the AI should never touch. We solved this by drawing a hard line — anything that produces a number, a URL, or a policy match is deterministic code, not Claude.
2. Anonymous authentication without sacrificing functionality
Getting Cognito Identity Pools to issue guest tokens that still had enough permissions to write to DynamoDB — without any login — took significant trial and error with IAM role scoping.
3. The two-tier privacy model
Writing to two separate DynamoDB tables atomically — one with full report data, one with only anonymous counters — while ensuring the second write could never leak any identifying information from the first, required careful schema design.
4. Emergency detection
Defining what counts as "immediate danger" in free text is harder than it sounds. We built a keyword and pattern matching layer that runs before the AI agents, so crisis resources surface instantly without waiting for the full pipeline.
Accomplishments that we're proud of
We are proud that we built something that actually works --- end to end, in a hackathon, under pressure.
But beyond the technical achievement, we are proud of the decisions we \textit{didn't} make. We didn't let the AI touch severity scores. We didn't store anything we didn't need. We didn't ask for a single piece of identifying information. In a world where most apps collect as much data as possible, we built one that actively tries to know as little as possible.
We are proud that a student could open Witness at 2am, shaking, not knowing what to do --- and walk away five minutes later with a formal statement drafted, their rights explained, and the right office identified. No account. No judgment. No friction.
We are also proud of the two-tier privacy model. The insight that individual privacy and institutional accountability are \textit{not} in conflict --- that you can protect a student completely while still giving a university real data to act on --- felt like a genuine design breakthrough.
What we learned
\subsection{Trust is a technical problem} Students won't use a tool they don't trust. Trust isn't built with a privacy policy nobody reads --- it's built with anonymous authentication, encrypted storage, auto-deletion, and routing rules that can be audited line by line. We learned to treat trust as an engineering requirement, not a marketing claim.
\subsection{Know where not to use AI} The most important AI decision we made was deciding where AI should \textit{not} be used. Severity scores, policy routing, and contact URLs are all deterministic code. We learned that responsible AI development isn't just about what the model can do --- it's about drawing hard lines around what it should never be allowed to do.
\subsection{Serverless forces good architecture} Because each Lambda function can only do one job, we were forced to think clearly about separation of concerns from the very beginning. The Session, Process, Save, and Retrieve Lambdas each have a single responsibility. That constraint made the system easier to debug, easier to secure, and easier to explain.
\subsection{Emergency detection is harder than it looks} Writing a layer that reliably identifies immediate danger in free, unstructured student text --- without false positives that overwhelm students with crisis alerts --- taught us how difficult edge-case design is when the stakes are real.
\subsection{Simplicity is the hardest thing to build} The student-facing experience is just a text box. Getting to that simplicity required the most complex work --- three AI agents, four Lambda functions, two database tables, KMS encryption, and anonymous authentication --- all invisible to the person who needs it most.
What's next for Witness
\subsection{Trust is a technical problem} Students won't use a tool they don't trust. Trust isn't built with a privacy policy nobody reads --- it's built with anonymous authentication, encrypted storage, auto-deletion, and routing rules that can be audited line by line. We learned to treat trust as an engineering requirement, not a marketing claim.
\subsection{Know where not to use AI} The most important AI decision we made was deciding where AI should \textit{not} be used. Severity scores, policy routing, and contact URLs are all deterministic code. We learned that responsible AI development isn't just about what the model can do --- it's about drawing hard lines around what it should never be allowed to do.
\subsection{Serverless forces good architecture} Because each Lambda function can only do one job, we were forced to think clearly about separation of concerns from the very beginning. The Session, Process, Save, and Retrieve Lambdas each have a single responsibility. That constraint made the system easier to debug, easier to secure, and easier to explain.
\subsection{Emergency detection is harder than it looks} Writing a layer that reliably identifies immediate danger in free, unstructured student text --- without false positives that overwhelm students with crisis alerts --- taught us how difficult edge-case design is when the stakes are real.
\subsection{Simplicity is the hardest thing to build} The student-facing experience is just a text box. Getting to that simplicity required the most complex work --- three AI agents, four Lambda functions, two database tables, KMS encryption, and anonymous authentication --- all invisible to the person who needs it most.
% ───────────────────────────────────────── \section{What's Next for Witness}
\subsection{Multi-Campus Expansion} Witness was built for Virginia Tech, but the architecture is institution-agnostic. The policy routing table, office contacts, and support resources are the only things that change between campuses. We want to make Witness deployable at any university in under a day.
\subsection{Counselor Dashboard} Right now, the analytics show trends. The next step is giving bias response teams a secure, real-time dashboard --- still fully anonymized --- where they can see incident clusters by location, spikes by category, and response time gaps. Actionable data, not just charts.
\subsection{Follow-Up Threading} Once a student files a report, they currently have no way to add information or track what happened. We want to build an anonymous follow-up thread --- same QR code, same token --- so students can add details, receive status updates, and feel heard beyond the initial submission.
\subsection{Multilingual Support} Bias doesn't only happen to students who are comfortable in English. Adding multilingual support --- starting with Spanish, Mandarin, and Arabic --- would make Witness accessible to the international students who are often most vulnerable and least likely to report.
\subsection{Formal Research Partnership} The aggregate data Witness collects is, over time, a real dataset on campus bias trends. We want to partner with university researchers to turn that data into published findings --- helping institutions understand not just what is being reported, but what the patterns reveal about campus climate.
\vspace{0.5cm}
Witness started as a hackathon project. But the problem it solves is permanent. As long as students experience bias and don't know where to turn, there is work to do.
[ \text{Better reporting} \Rightarrow \text{Better data} \Rightarrow \text{Better campuses} ]
Built With
- amazon-web-services
- bedrock
- javascript
- kiro
- python

Log in or sign up for Devpost to join the conversation.