-
-
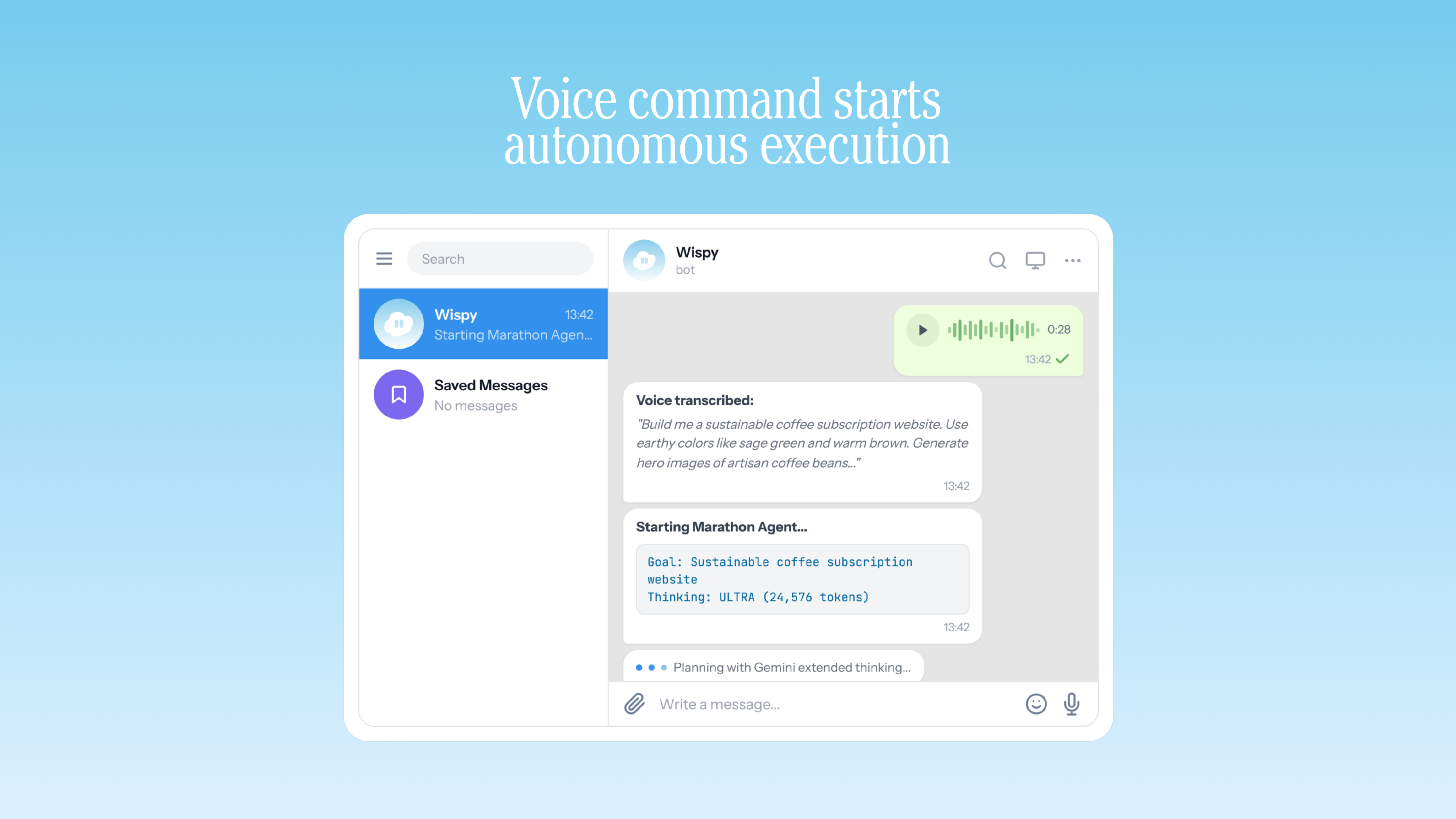
Voice command starts autonomous execution
-
Gemini extended thinking plans 8 milestones
-
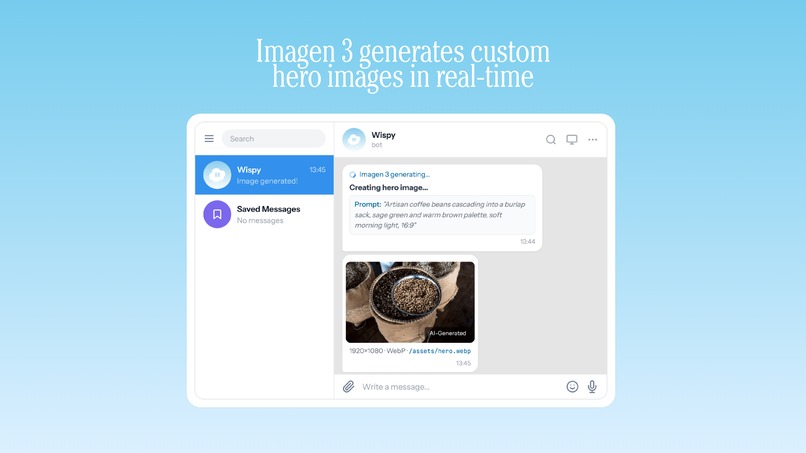
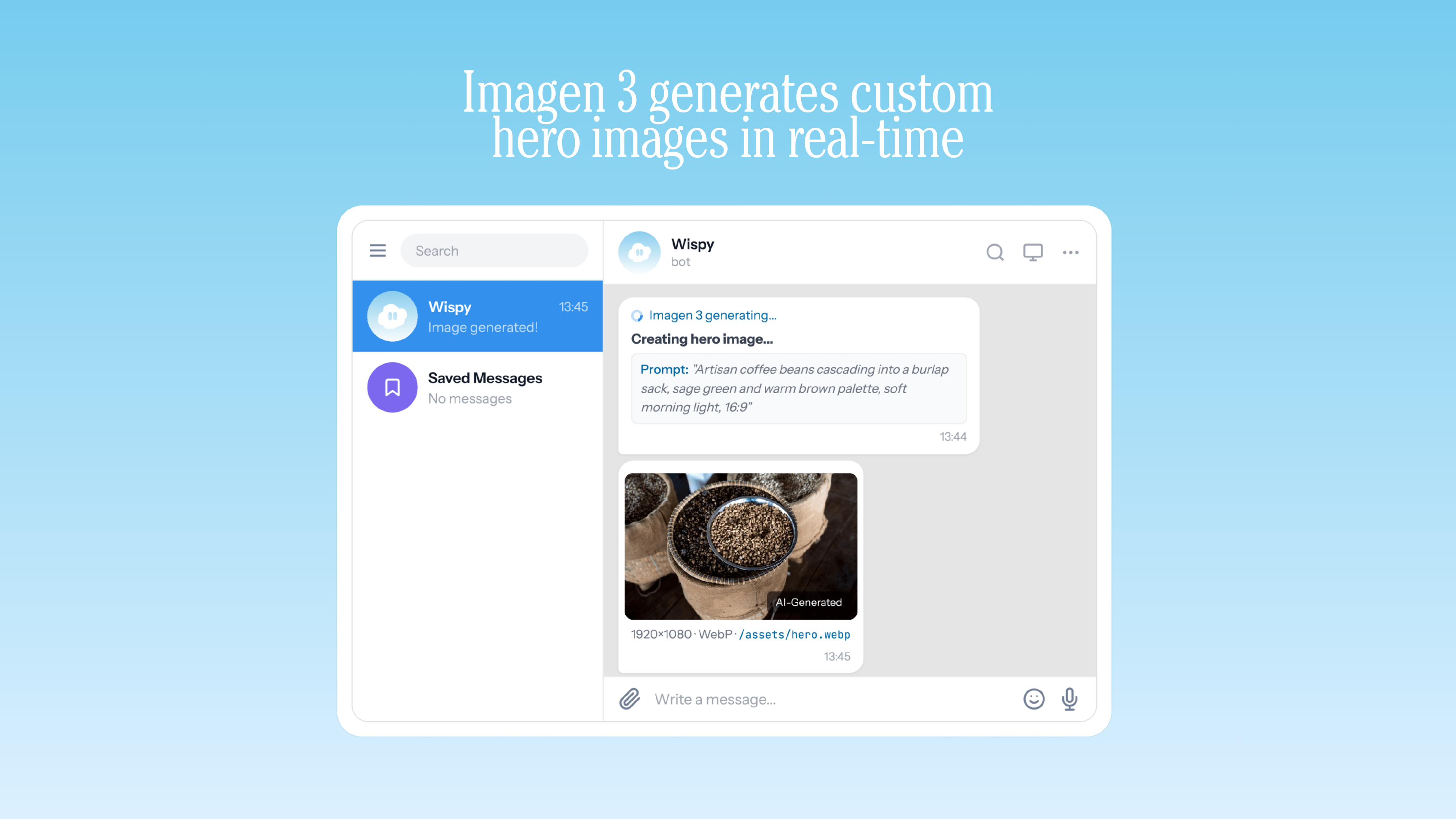
Imagen 3 generates custom hero images in real-time
-
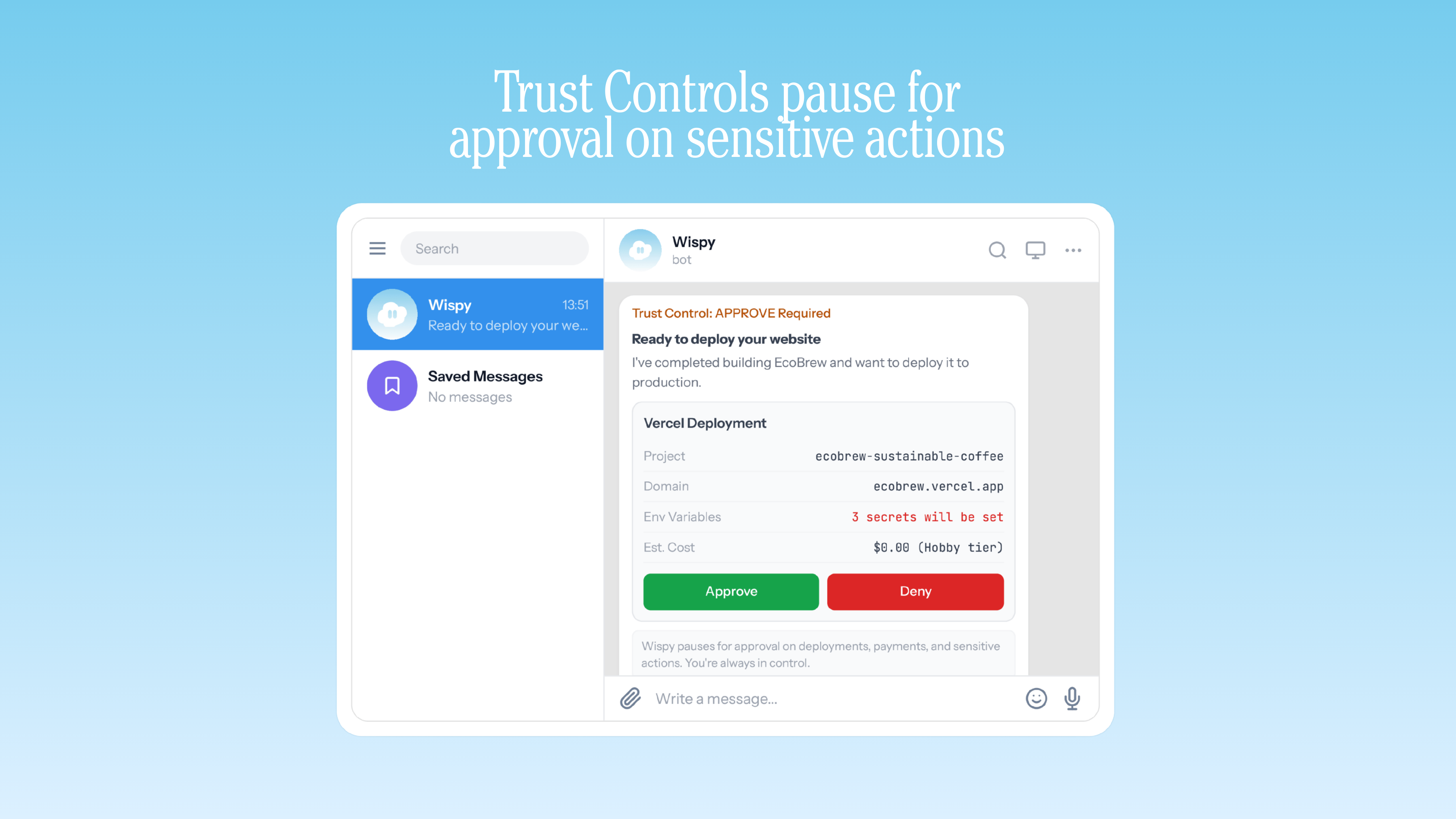
Trust Controls pause for approval on sensitive actions
-
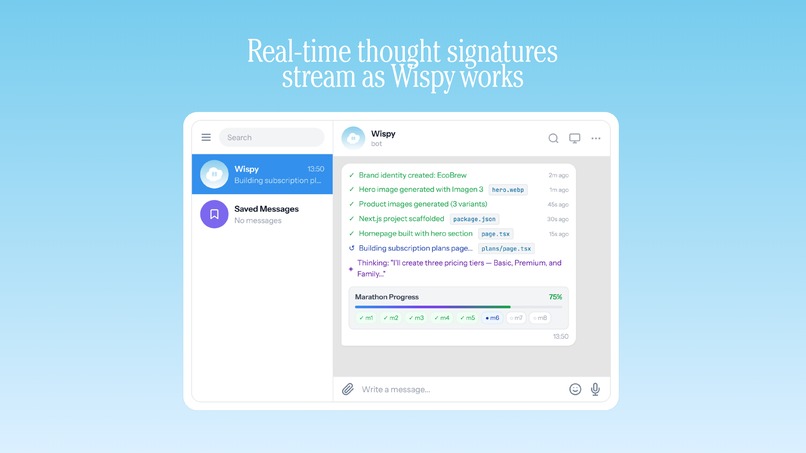
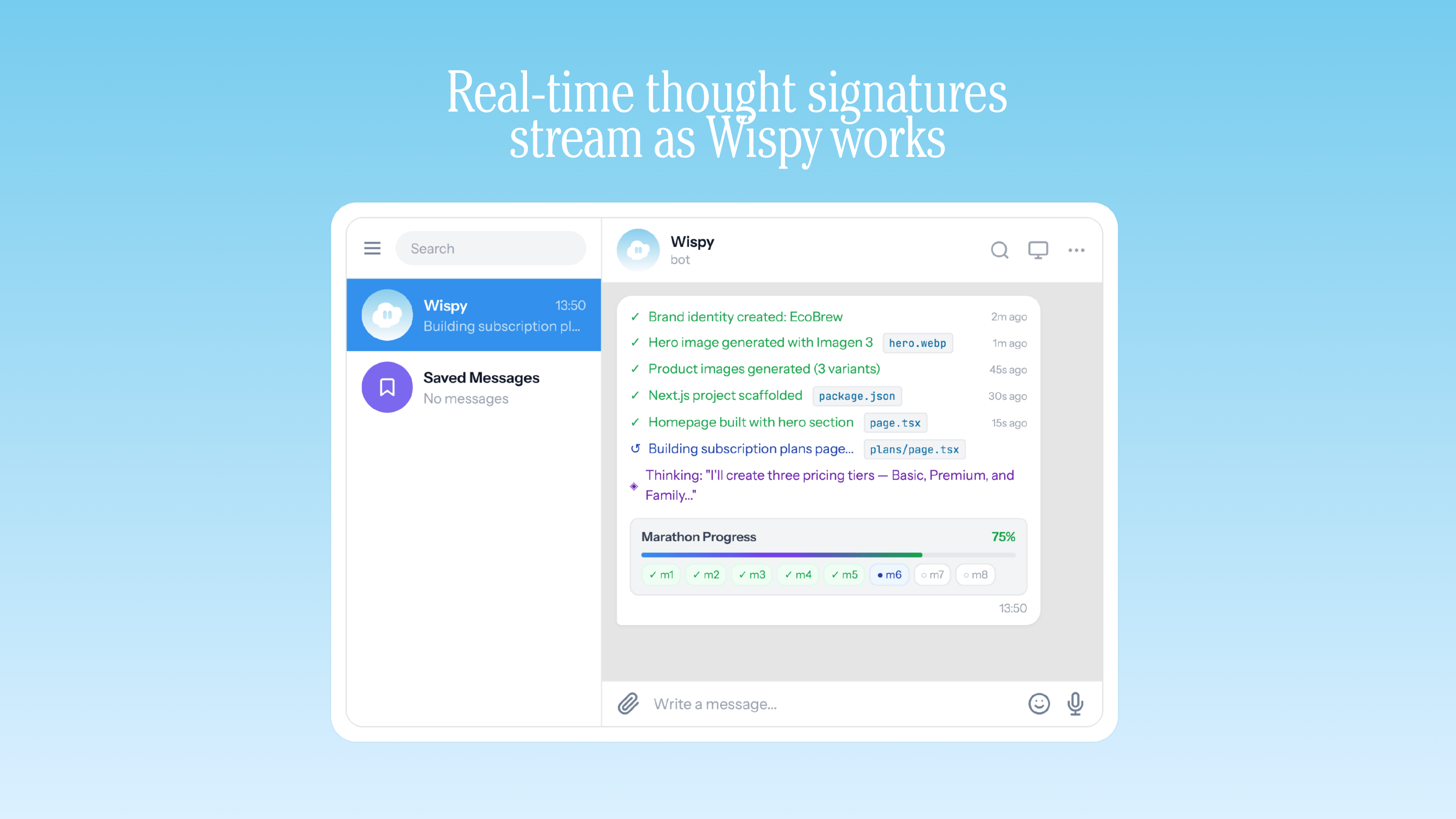
Real-time thought signatures stream as Wispy works
-
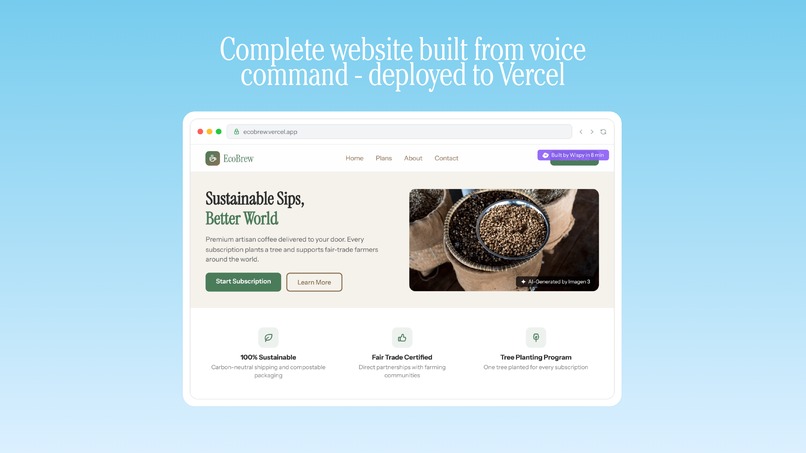
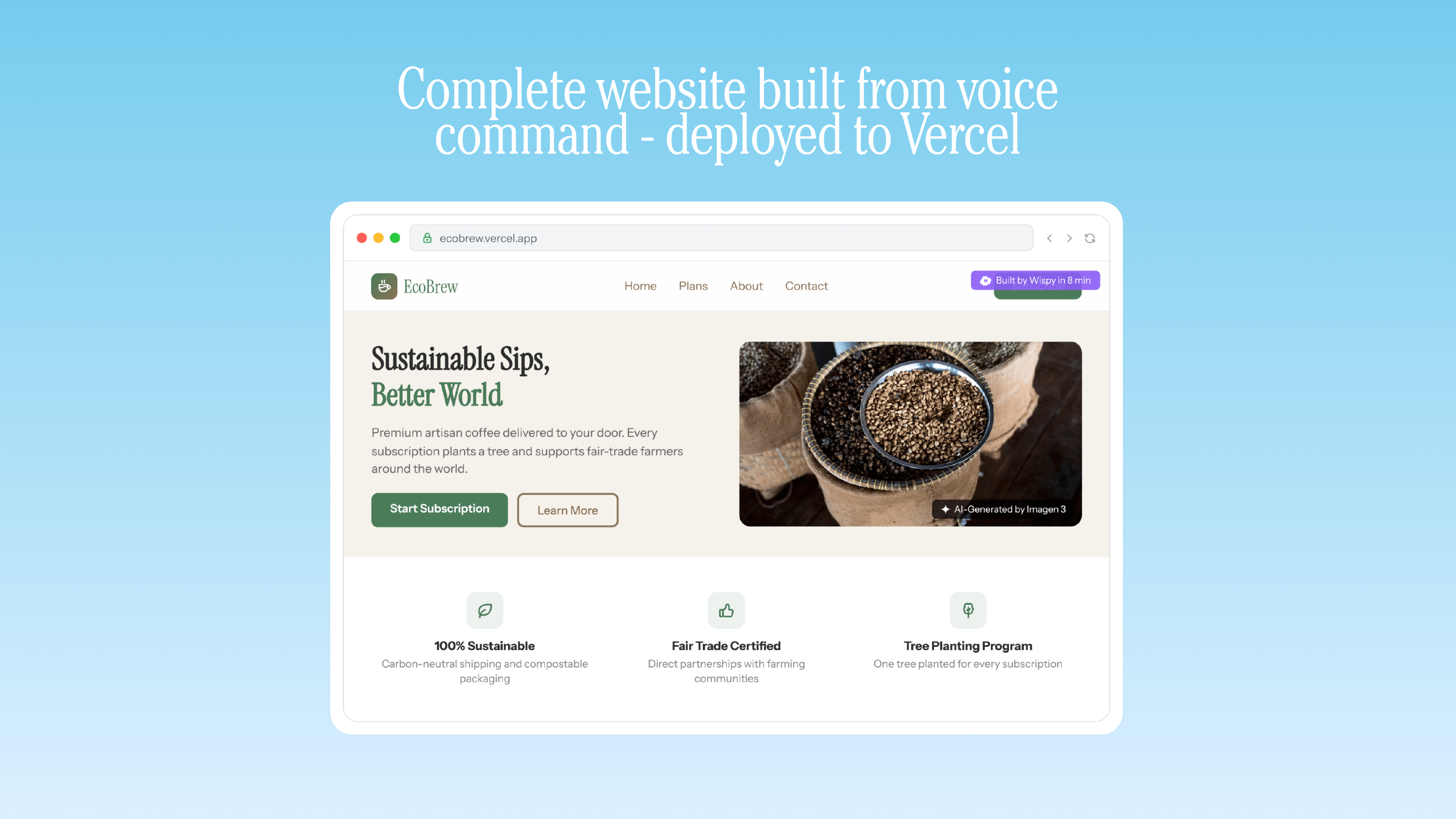
Complete website built from voice command - deployed to Vercel
-

CLI showing Gemini integration, 27+ tools, and Marathon Mode



Wispy - Autonomous AI Agent Platform
Inspiration
We kept hitting the same wall. Every time we needed an AI to do something real, not just answer a question, but actually build something, research something, execute a multi-step task, we had to babysit it the entire time. Copy-paste outputs. Re-prompt when it lost context. Start over when it failed halfway through.
We thought: what if an AI agent could take a goal like "build a REST API with auth and tests" and just go do it? Plan the steps, execute them one by one, recover when something fails, and keep going for hours or days until it's done. No hand-holding.
That's what we built with Wispy.
What it does
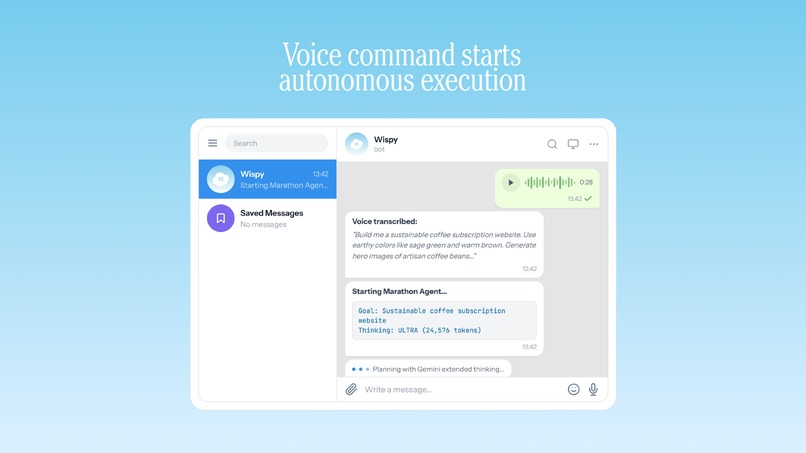
Wispy is an autonomous AI agent platform built entirely on the Gemini API. You give it a task, it plans the whole thing into milestones, then executes each milestone autonomously using 90+ built-in tools. We call this Marathon Mode, because the agent doesn't stop until the job is done.
Here's what actually happens when you run a marathon:
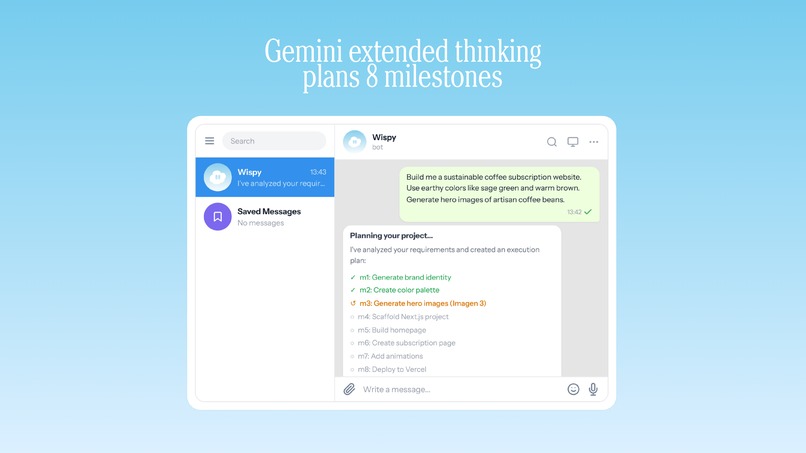
- Gemini 2.5 Pro receives the goal and uses extended thinking (up to 24,576 tokens of reasoning budget) to decompose it into a detailed milestone plan
- The agent executes each milestone by chaining tool calls via Gemini native function calling: file creation, shell commands, web requests, browser automation, image generation via Imagen 3, whatever the task needs
- After each milestone, Gemini verifies its own work against the requirements and decides if the milestone is actually complete
- If something fails, the agent analyzes the error using Gemini's reasoning and retries with a different approach, up to 3 recovery attempts per milestone
- Progress is checkpointed to disk, so you can pause and resume at any point
- Real-time updates are pushed to Telegram or WhatsApp so you can monitor from your phone
It's not a chatbot. It's an agent that does the work.
Architecture
Wispy is a full platform, not a script. Here's how it's structured:
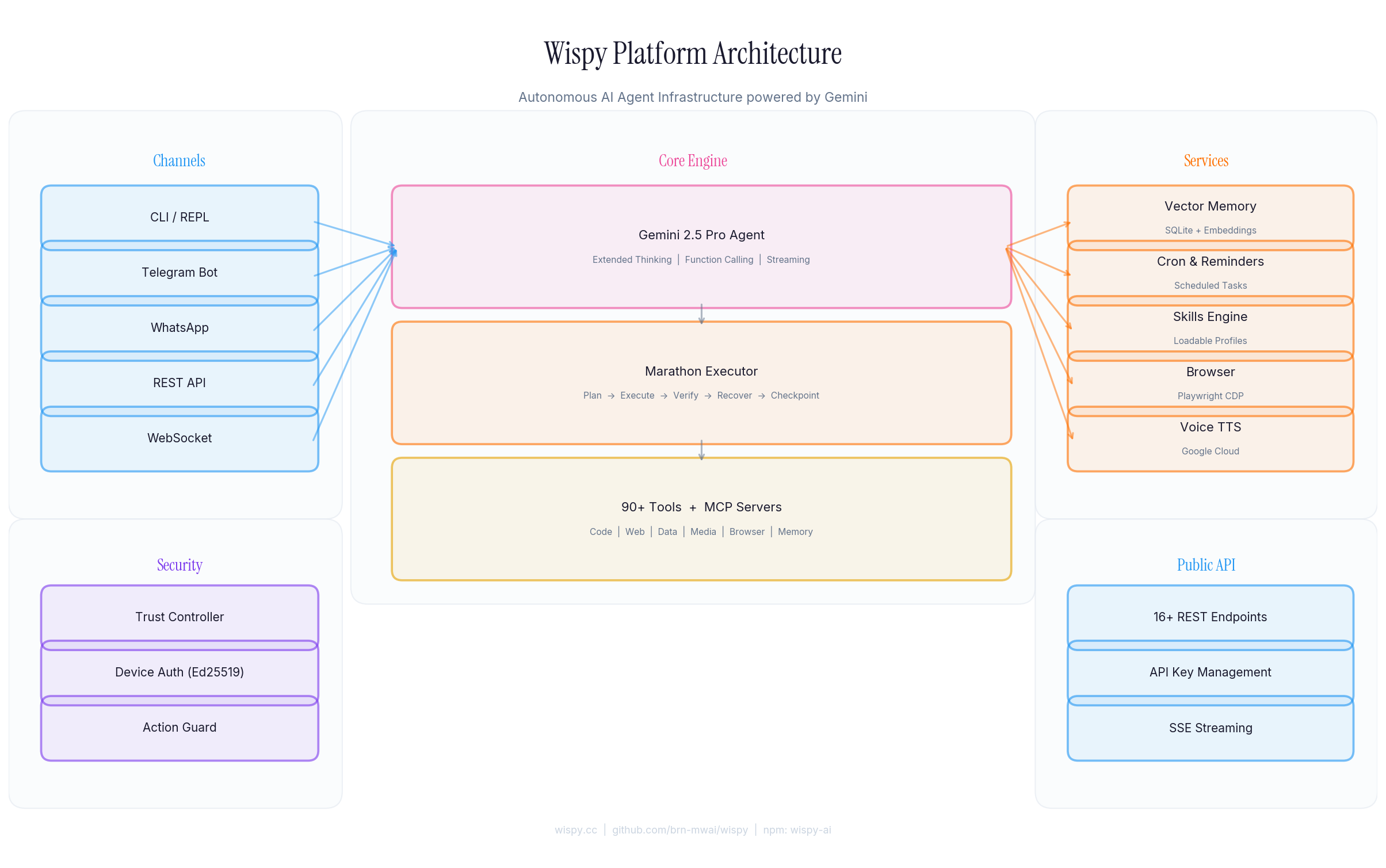
Channels (left) handle user interaction: CLI, Telegram, WhatsApp, REST API, and WebSocket all feed into the same core engine. The Core Engine (center) is where Gemini lives: the agent loop, Marathon executor, and all 90+ tools. Services (right) provide the supporting infrastructure: vector memory, scheduled tasks, browser automation, voice TTS, and the skills engine.
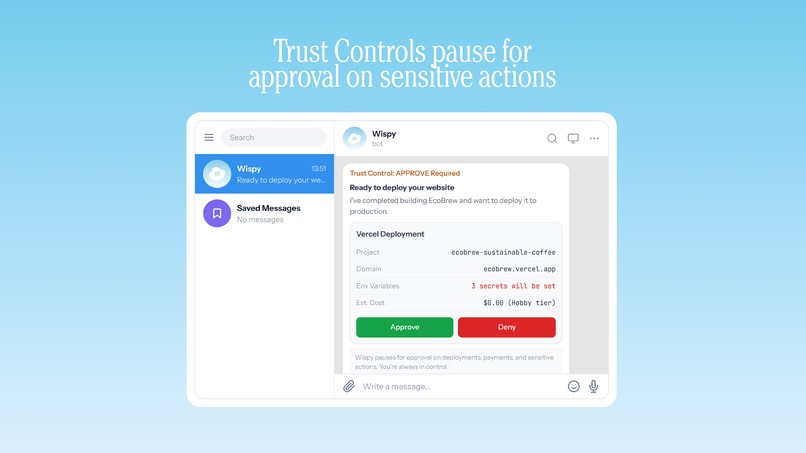
Security runs through every layer. Device authentication uses Ed25519 key pairs. The Action Guard enforces permission levels before any destructive tool executes. The Trust Controller manages session isolation so multi-user environments stay clean.
The public REST API exposes 16+ endpoints with API key management, rate limiting, and SSE streaming, so you can integrate Wispy into any application.
How Gemini Powers Everything
This is not a project that uses Gemini as a wrapper. Every part of the system is built directly on the Gemini API through the @google/genai SDK. Here is exactly how each Gemini capability is used:
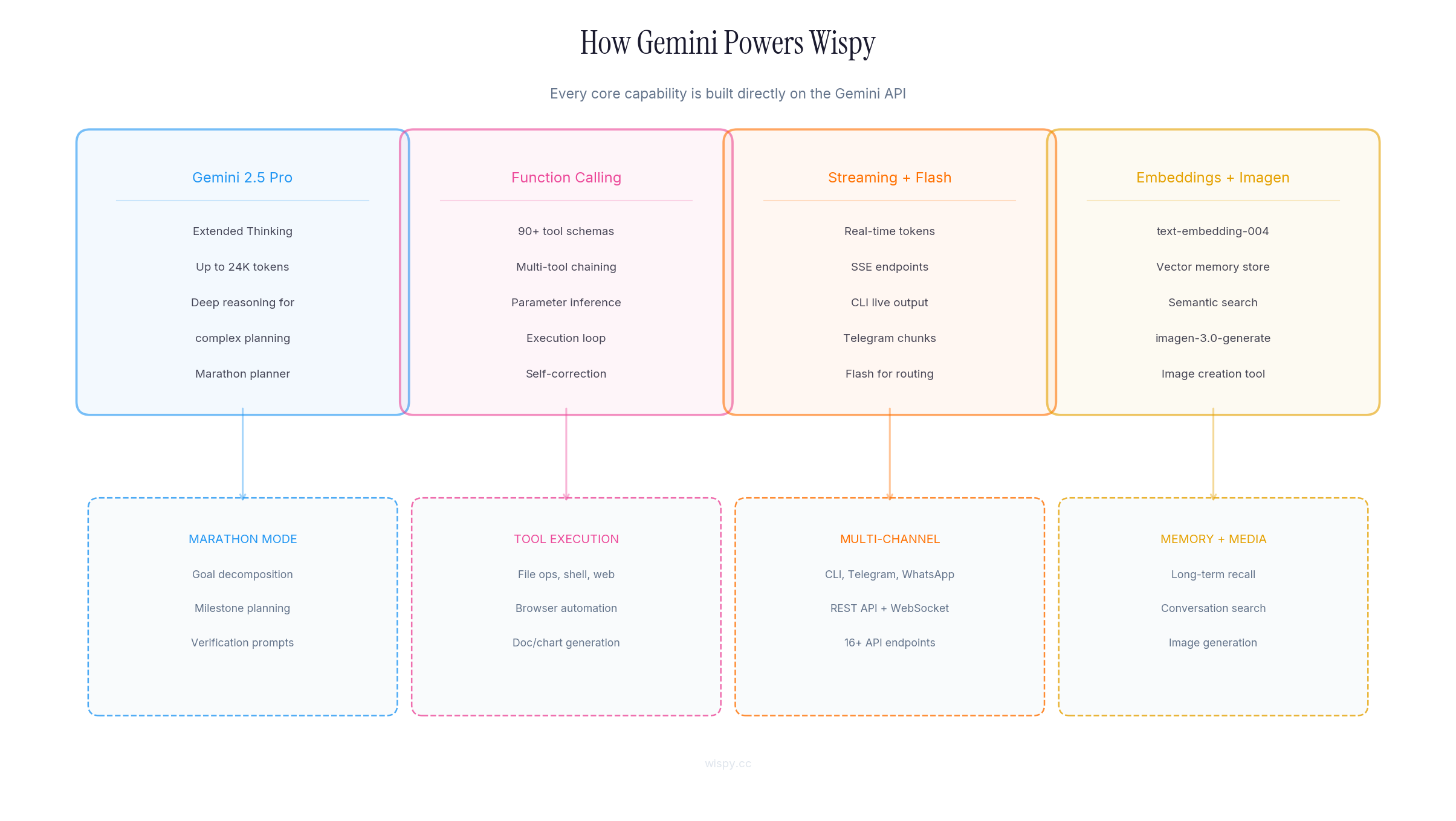
| Gemini API Feature | How Wispy Uses It |
|---|---|
| Gemini 2.5 Pro | The primary model powering all agent reasoning, planning, and execution. Every conversation and marathon task runs through Gemini 2.5 Pro. |
| Extended Thinking (Thinking Budgets) | Marathon planning uses configurable thinking budgets: low (128 tokens), medium (1,024), high (8,192), and ultra (24,576). The agent reasons deeply before acting on complex goals. |
| Native Function Calling | 90+ tools registered as Gemini function declarations with full JSON schemas. The model decides which tools to call, in what order, with what parameters. Multi-tool chaining per turn. This is the core execution loop. |
| Streaming (generateContentStream) | Real-time token streaming for interactive chat across CLI, Telegram, WhatsApp, and SSE endpoints. Users see the agent thinking and responding in real-time. |
| text-embedding-004 | Vector memory system. Every conversation turn is embedded using text-embedding-004 and stored in SQLite for semantic search and long-term recall across sessions. |
| Imagen 3 (imagen-3.0-generate-002) | Image generation as a native tool. The agent can create images as part of any task: diagrams, mockups, visual assets, all generated through the Gemini API. |
| Gemini 2.5 Flash | Fast model for lightweight operations: token estimation, routing decisions, content classification, and quick tasks where Pro would be overkill. Used for intelligent model routing. |
| Structured Output (JSON Mode) | Tool result parsing and structured data extraction use Gemini's JSON output mode to ensure clean, parseable responses for the agent loop. |
| System Instructions | Every agent session uses Gemini system instructions to define the agent's personality, capabilities, tool usage rules, and safety boundaries. The skills engine dynamically injects skill-specific system instructions. |
| Multi-turn Conversations | Full conversation history management with Gemini's multi-turn chat API. Context compaction summarizes older turns while preserving recent context for long-running marathons. |
| Safety Settings | Configurable Gemini safety settings per session. The agent respects content safety while still being able to execute code and system commands within the trust boundary. |
| Thought Signatures | Reasoning continuity across sessions. When the agent resumes a multi-day marathon, it picks up its chain of thought from where it left off. |
Every API call goes through the @google/genai SDK. We use GoogleGenAI for standard generation, generateContentStream for streaming, the embeddings API for memory, and the image generation API for Imagen 3. There is no middleware model. Gemini is the brain.
Marathon Mode - Deep Dive
This is the core innovation. Marathon Mode turns Gemini from a conversational model into an autonomous executor.
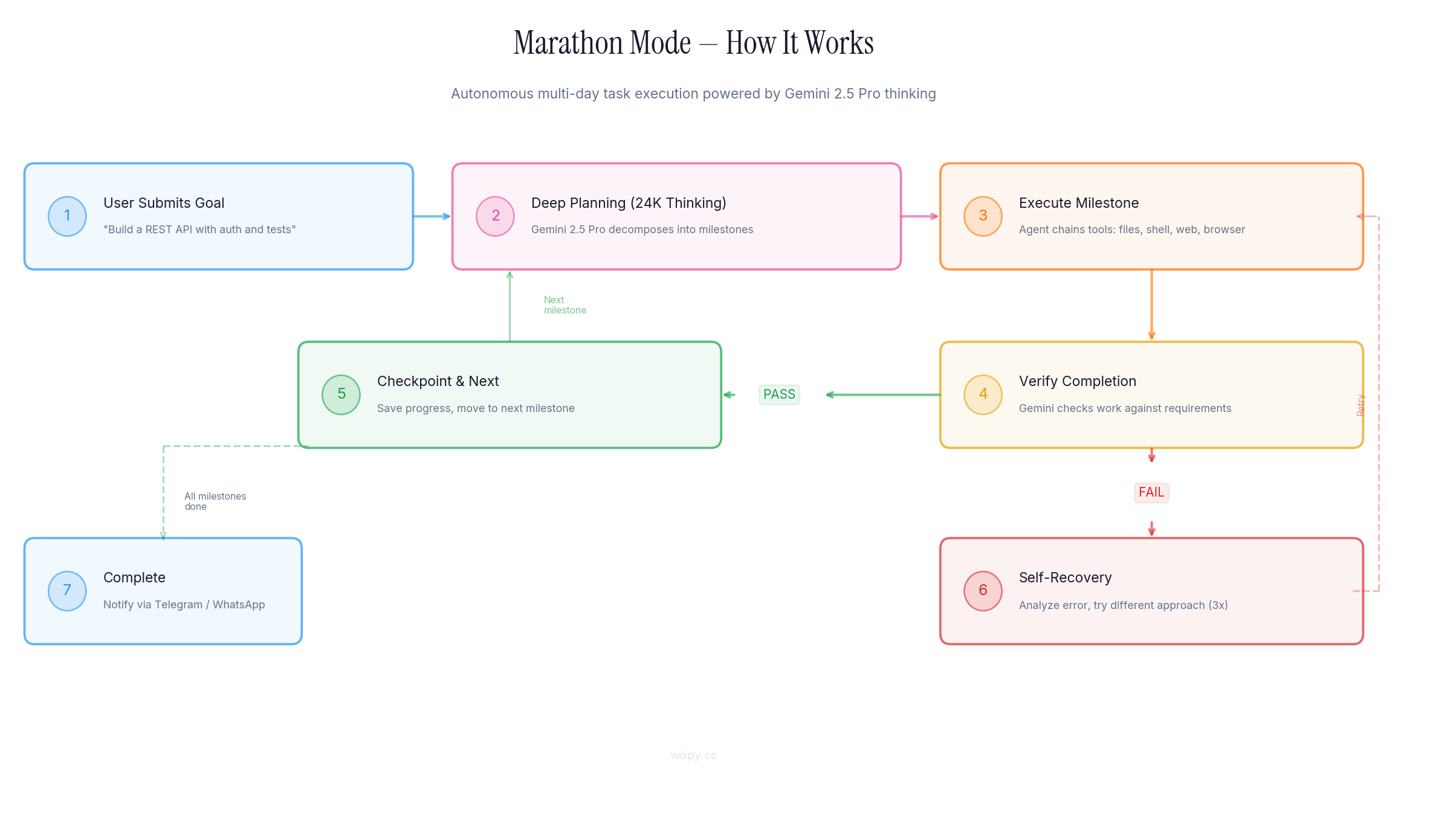
Step 1 - Goal Submission: The user provides a natural language goal. Could be simple ("set up a Node.js project") or complex ("build a full-stack dashboard with auth, database, API, and deploy to Vercel").
Step 2 - Deep Planning: This is where the thinking budget matters. Gemini 2.5 Pro receives the goal with an extended thinking budget of up to 24,576 tokens. It doesn't just list steps, it reasons through dependencies, potential failure points, and verification criteria for each milestone. The quality of this plan directly determines whether the marathon succeeds or fails.
Step 3 - Milestone Execution: The agent chains tool calls to complete each milestone. A single milestone might involve creating files, running shell commands, making HTTP requests, automating a browser, and generating images with Imagen 3, all in sequence, all decided by Gemini's function calling.
Step 4 - Self-Verification: After execution, Gemini evaluates its own work against the milestone requirements. This isn't a rubber stamp. The model is prompted to find gaps, missing edge cases, and incomplete implementations.
Step 5 - Pass or Recovery: If verification passes, the agent checkpoints and moves to the next milestone. If it fails, the agent enters self-recovery: it analyzes the error, reasons about alternative approaches, and retries up to 3 times with different strategies.
Step 6 - Checkpoint: Progress is saved to disk after every milestone. The marathon can be paused, resumed, or inspected at any point. If the process crashes, it picks up from the last checkpoint.
Step 7 - Completion: When all milestones are done, the agent notifies you via Telegram or WhatsApp with a summary of what was accomplished.
90+ Built-in Tools
Every tool is registered as a Gemini function declaration with a full JSON schema. The model sees all tools and decides which ones to use based on the task.
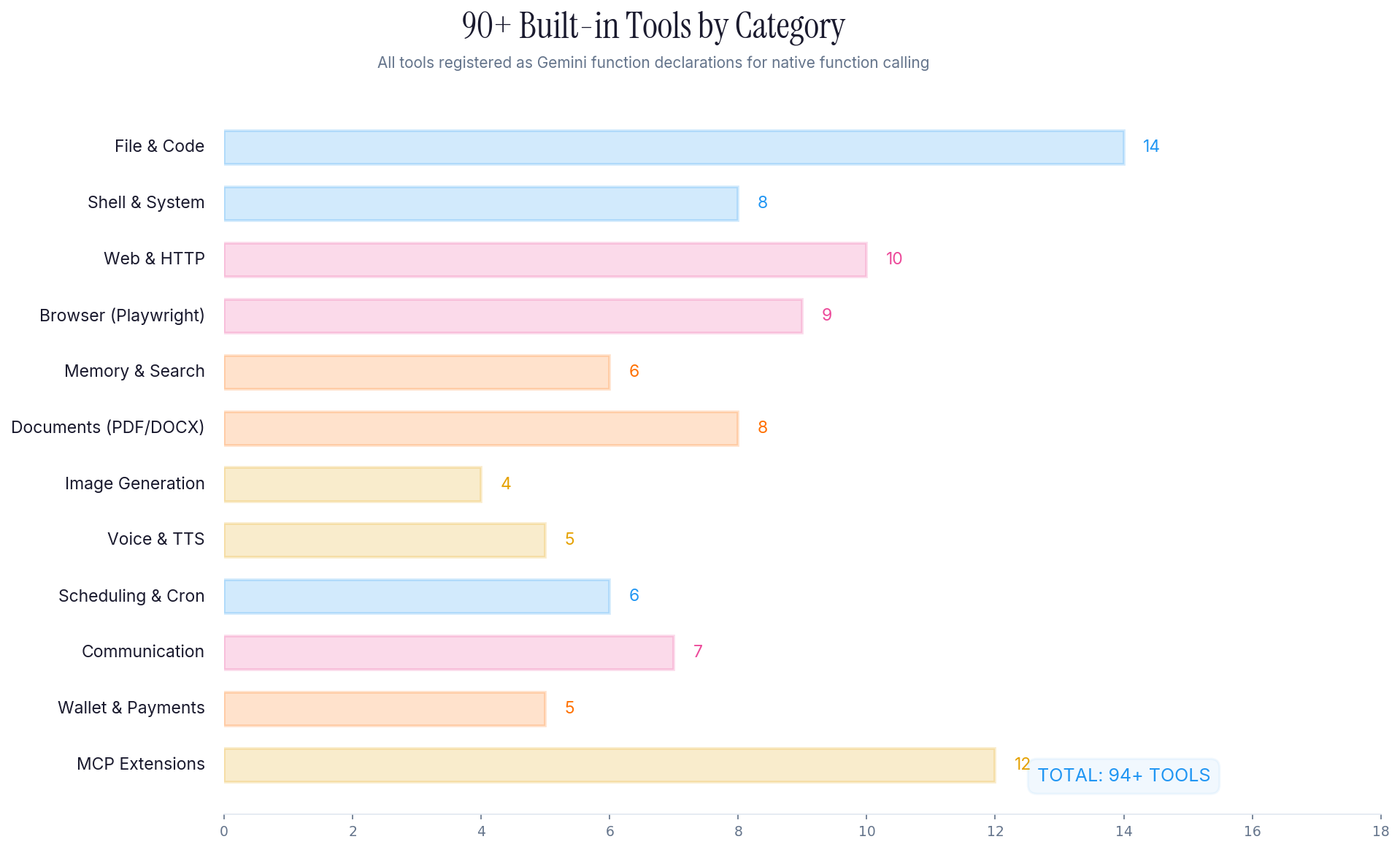
The tools span 12 categories:
- File & Code (14 tools): Read, write, edit, search, glob, create directories, manage projects
- Shell & System (8 tools): Execute commands, manage processes, environment variables, system info
- Web & HTTP (10 tools): Fetch URLs, parse HTML, make API calls, download files, web scraping
- Browser Automation (9 tools): Navigate, click, type, screenshot, extract data via Playwright CDP
- Memory & Search (6 tools): Store, recall, search conversations with semantic similarity via text-embedding-004
- Documents (8 tools): Generate PDFs, DOCX, parse documents, create charts and reports
- Image Generation (4 tools): Create images via Imagen 3, process and manipulate images
- Voice & TTS (5 tools): Text-to-speech via Google Cloud, voice transcription, audio processing
- Scheduling & Cron (6 tools): Set reminders, schedule recurring tasks, manage cron jobs
- Communication (7 tools): Send messages via Telegram, WhatsApp, manage notifications
- Wallet & Payments (5 tools): Blockchain interactions, wallet management
- MCP Extensions (12 tools): Model Context Protocol servers for extending capabilities
All 90+ tools support multi-tool chaining. Gemini can call multiple tools per turn, passing outputs between them. The tool executor handles parameter validation, error capture, and result formatting before sending back to Gemini.
How we built it
Development environment: We used Google Antigravity as our primary AI-assisted coding environment for building and iterating on the platform. Antigravity's tight integration with Gemini made it natural to develop an agent that runs on Gemini. We also prototyped and tested our Gemini API calls directly in Google AI Studio before integrating them into the codebase.
TypeScript end to end. The entire platform is ~15,000 lines of TypeScript with ES modules, running on Node.js 20+.
The core agent loop:
- Gemini receives a message + 90+ tool declarations as function schemas
- The model responds with text or tool calls (via native function calling)
- If tool calls: execute, capture results, send back to Gemini
- Loop until the model decides it's done
- For Marathon Mode: this loop runs per-milestone, with verification and recovery wrapping each cycle
Key technical decisions:
@google/genaiSDK for all Gemini API calls: chat, streaming, function calling, embeddings, image generation- Google AI Studio for API key management, prompt prototyping, and testing Gemini configurations before deploying to production
- SQLite + text-embedding-004 for the memory system: every conversation turn is embedded and stored for semantic recall
- Grammy for Telegram: full inline keyboards, marathon controls, voice transcription
- Baileys for WhatsApp: QR code auth, message handling, progress notifications
- Express for the public REST API: 16+ endpoints with API key auth, rate limiting, SSE streaming
- Playwright for browser automation: CDP connection, full page interaction
- Commander.js for the CLI: 19 commands, interactive REPL with live markdown rendering
Context window management was our hardest engineering problem. Long-running marathons generate massive amounts of tool output. We built a compaction system that summarizes older turns (using Gemini 2.5 Flash for fast summarization) while preserving recent context, so the agent doesn't lose track of what it's doing mid-marathon.
Schema cleaning was another challenge. Gemini's function calling is strict about JSON schemas. We built a cleaning layer that strips unsupported fields (like additionalProperties, nested $ref) and normalizes all 90+ tool declarations so Gemini processes them correctly every time.
Challenges we ran into
Self-verification honesty. Getting the agent to honestly assess whether a milestone is complete, rather than just saying "done" and moving on, took significant iteration. We use Gemini's system instructions to prompt the model specifically to check output against requirements, surface gaps, and flag incomplete work. The verification prompt is as important as the execution prompt.
Rate limit recovery. Gemini API rate limits hit hard during marathon execution when the agent is making rapid tool calls. We implemented exponential backoff with jitter that retries transparently, so the agent doesn't lose progress when throttled.
Multi-channel session isolation. The same agent instance serves CLI, Telegram, WhatsApp, and API users simultaneously. Session isolation ensures one user's context doesn't leak into another's, while the underlying memory and tool infrastructure is shared.
Token estimation accuracy. Predicting token usage before sending requests to Gemini is critical for staying within context limits. We use Gemini 2.5 Flash for fast token estimation, but the gap between estimated and actual tokens required calibration.
Accomplishments we're proud of
- Marathon Mode actually works. Not as a demo. It completes real multi-step projects autonomously. We've run marathons that span 20+ milestones over hours of execution.
- 90+ tools with native function calling. Every tool is a first-class Gemini function declaration. The model understands them and chains them correctly.
- Multi-channel from day one. The same agent works identically across CLI, Telegram, WhatsApp, and REST API. You can start a marathon from Telegram and check progress from the CLI.
- Published and installable.
npm install -g wispy-aiworks right now. Setup takes under 2 minutes with a free Gemini API key from Google AI Studio.
What we learned
The biggest insight: the thinking budget matters more than the model size. Giving Gemini 2.5 Pro a 24K token thinking budget for planning produces dramatically better milestone decompositions than a small budget. The quality of the plan directly determines whether the marathon succeeds or fails.
We also learned that verification is more important than execution. An agent that executes fast but doesn't check its work produces garbage. An agent that verifies every step, even if slower, actually finishes the job.
And: function calling schemas need to be clean. Gemini is strict about what it accepts. One malformed schema in 90 tools breaks the entire tool set. Our schema cleaning layer was unglamorous but essential.
What's next for Wispy
- Parallel milestone execution for independent task branches
- Team collaboration so multiple users can monitor and steer the same marathon
- Cost analytics dashboard to track token usage and API costs per marathon
- Plugin system for custom tool sets beyond the built-in 90+
- Agent-to-Agent (A2A) protocol for Wispy agents delegating tasks to each other
- Gemini context caching to reduce costs on long-running marathons with repeated tool schemas
Built With
Google Gemini 2.5 Pro, Google Gemini 2.5 Flash, Imagen 3, text-embedding-004, @google/genai SDK, Google AI Studio, Google Antigravity, TypeScript, Node.js, Express, SQLite, Grammy, Baileys, Playwright, Commander.js, WebSocket, SSE, Ed25519, MCP
Try it out
- Website: wispy.cc
- GitHub: github.com/brn-mwai/wispy
- npm: npmjs.com/package/wispy-ai
- Google AI Studio: aistudio.google.com (get a free API key to try Wispy)
- Install:
npm install -g wispy-ai && wispy setup
Built With
- baileys
- commander.js
- ed25519
- express.js
- google-gemini-2.5-flash
- google-gemini-2.5-pro
- google/genai-sdk
- grammy
- imagen-3
- mcp-(model-context-protocol)
- node.js
- npm
- playwright
- sqlite
- sse
- text-embedding-004
- typescript
- websocket



Log in or sign up for Devpost to join the conversation.