-
-

Planning Phase
-
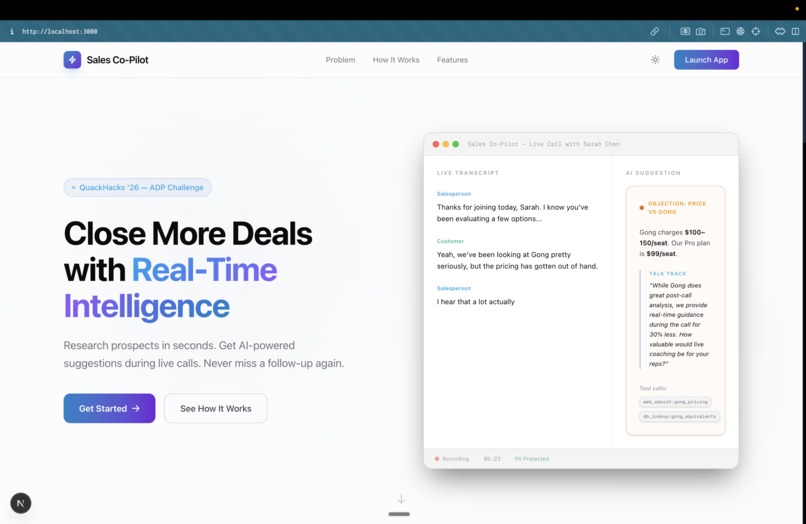
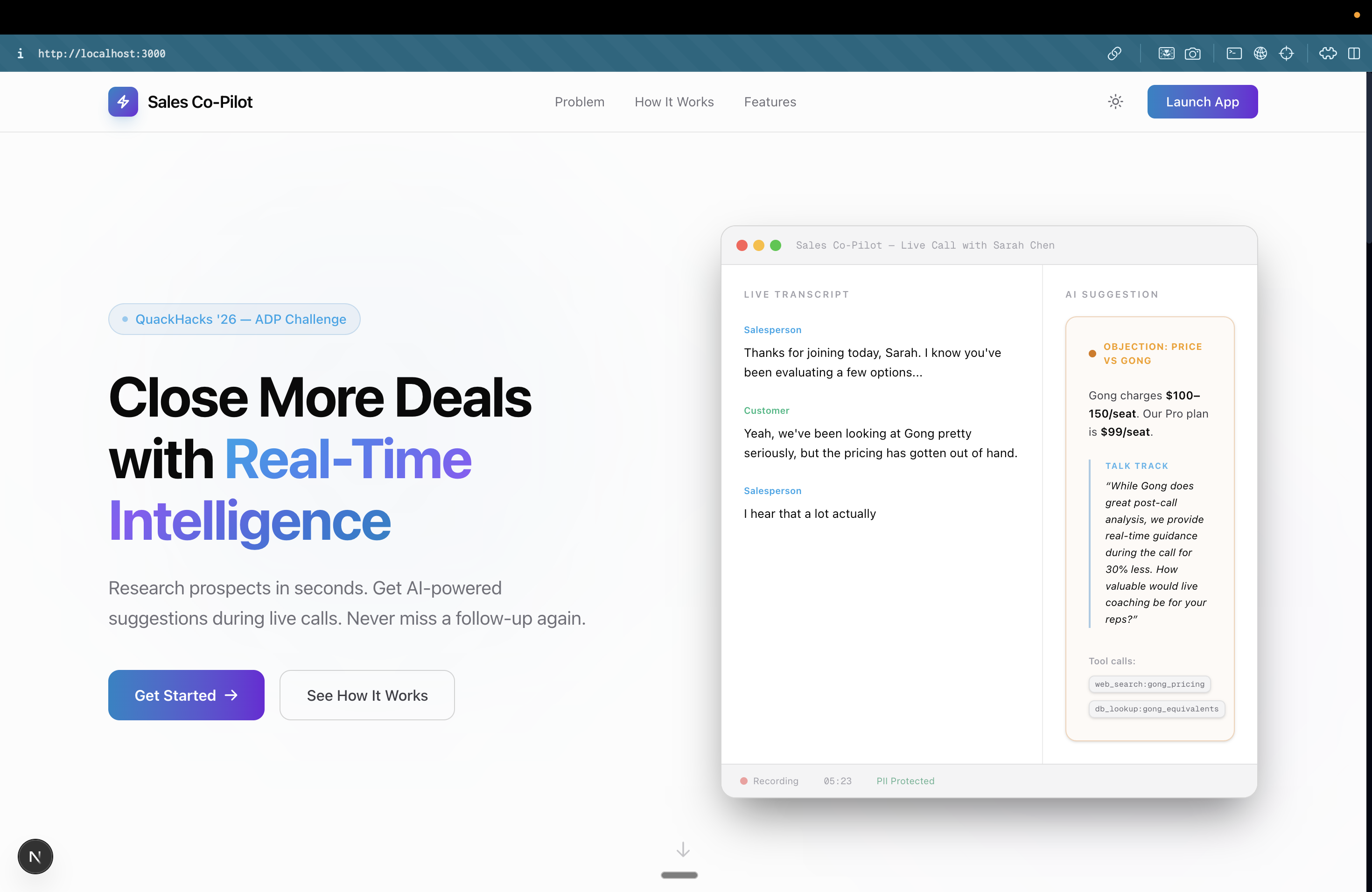
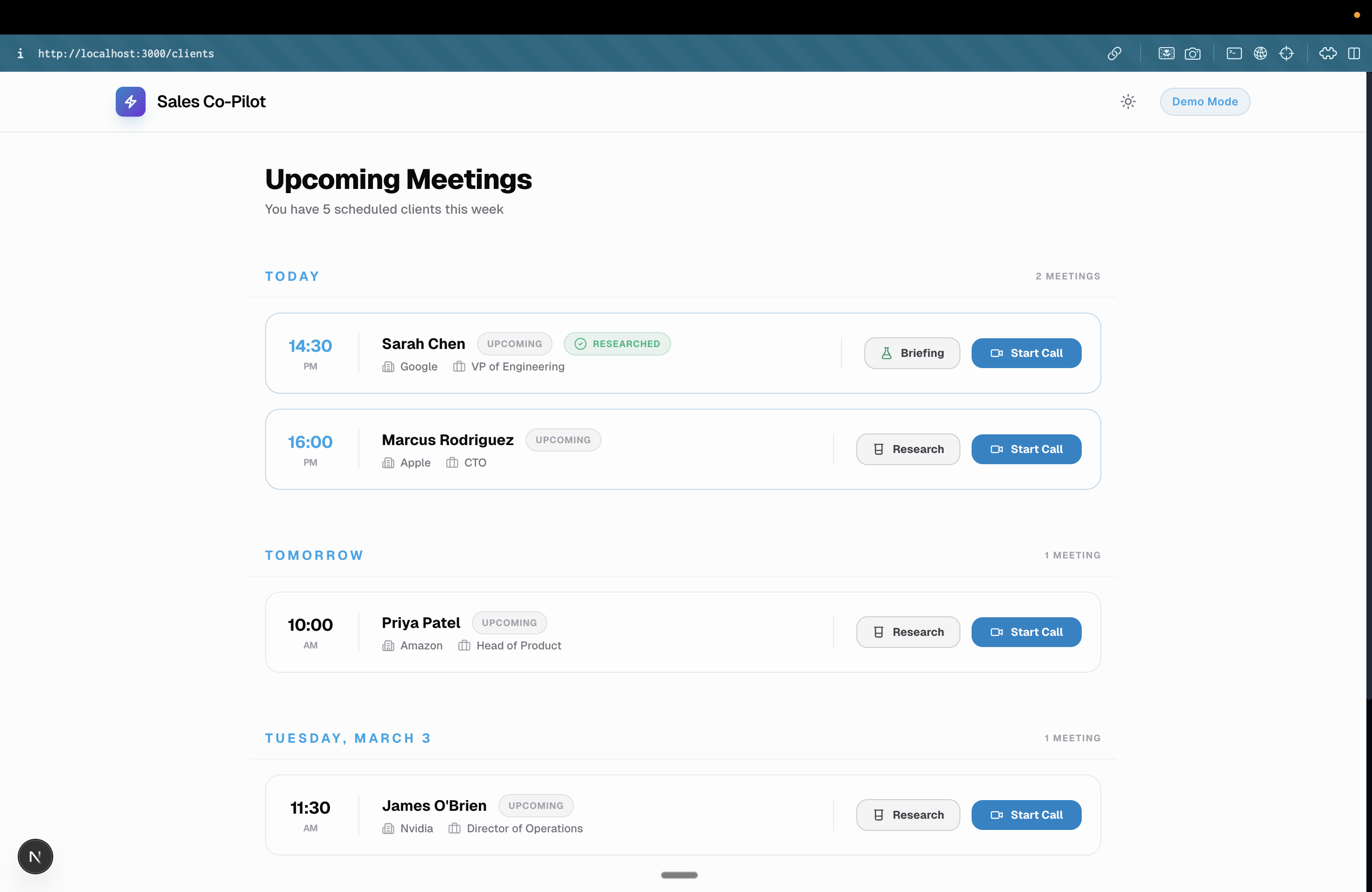
Landing Page
-
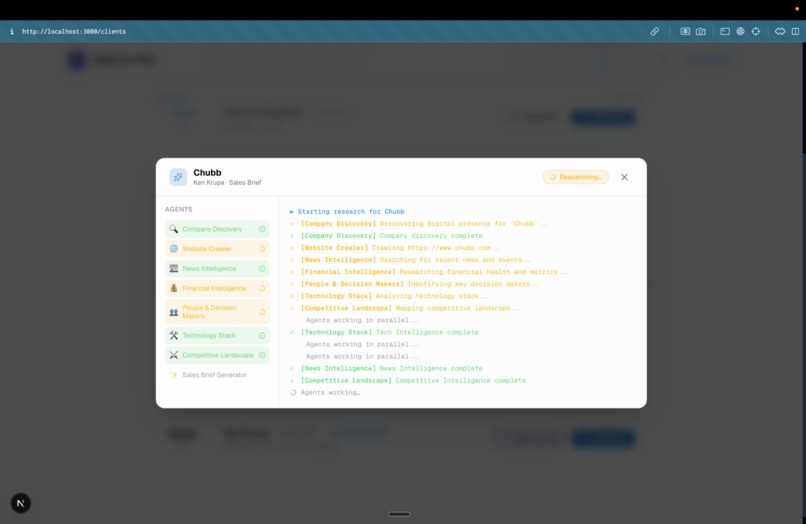
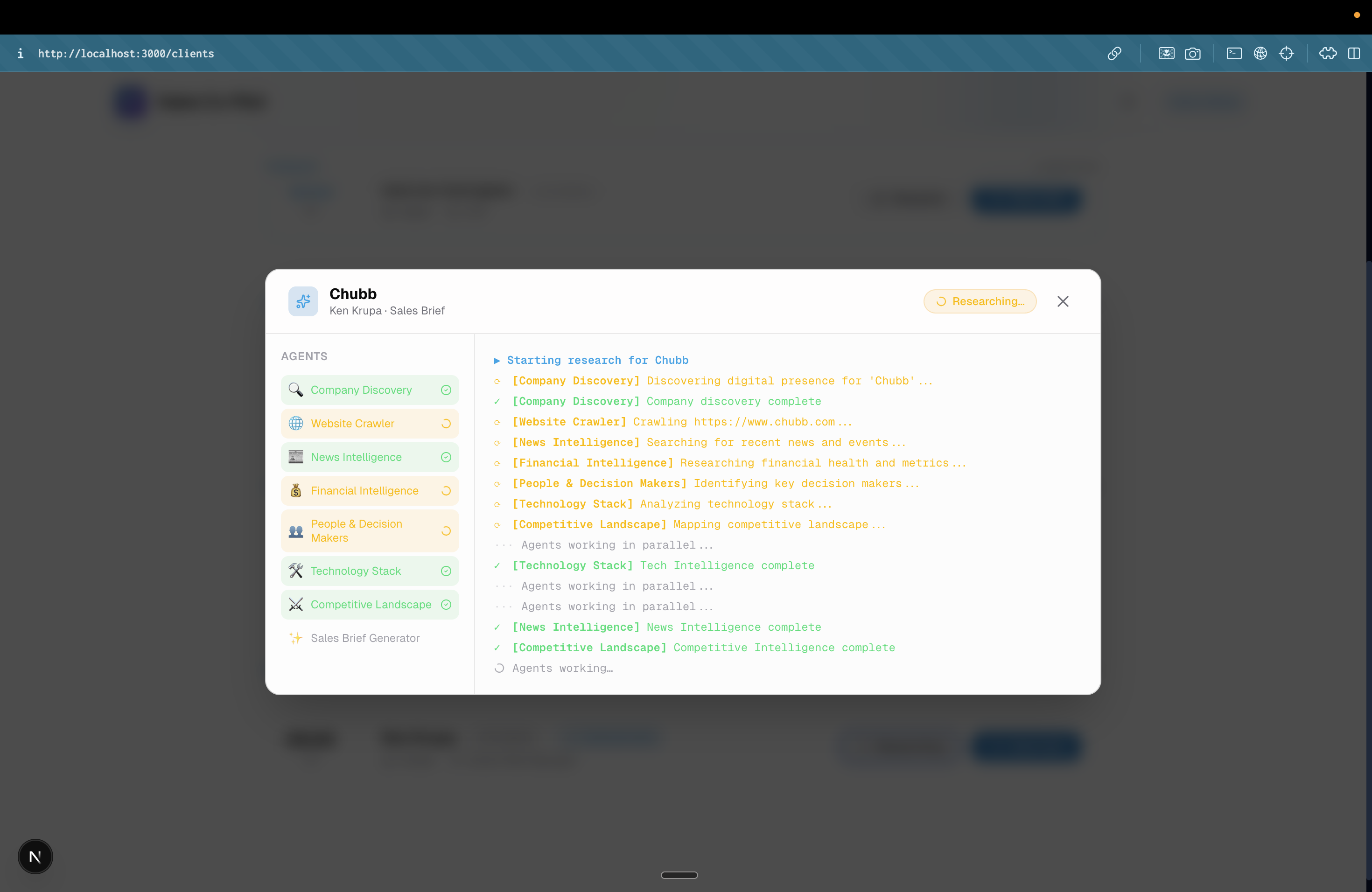
Research Agents working in parallel to fetch prospect information
-
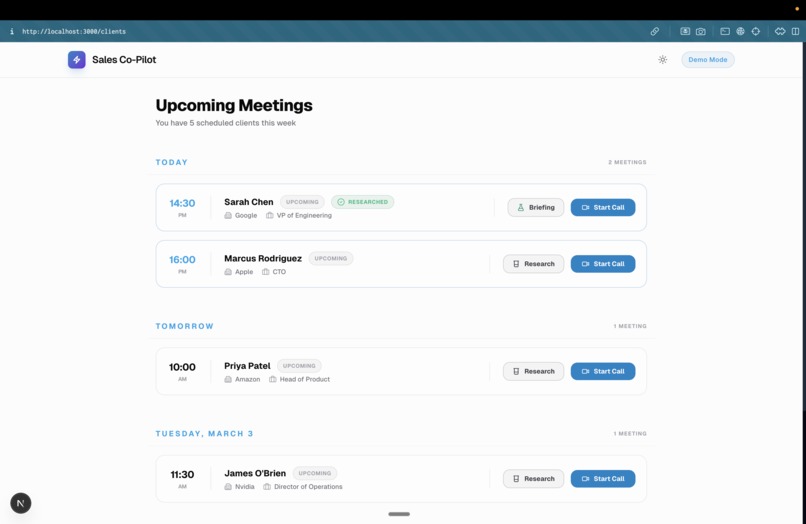
Sales professional's To-do (Automatically populated via a voice AI as a future scope)
-
Dark mode (Cause it looked cool)
-
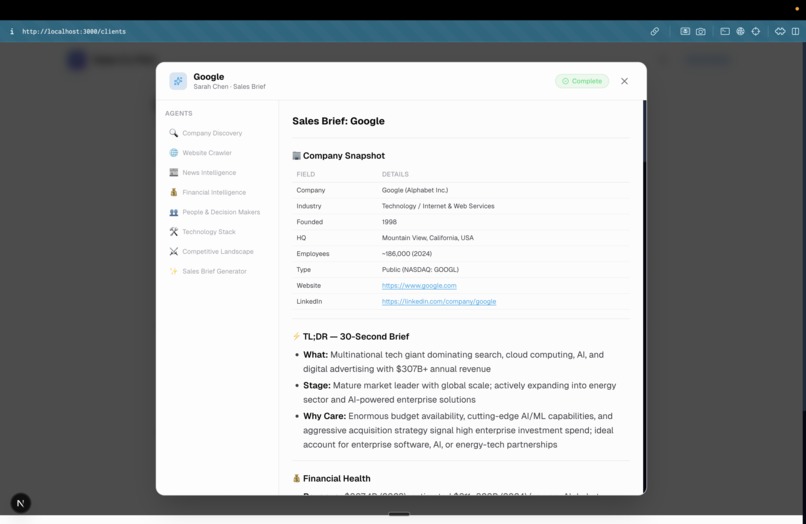
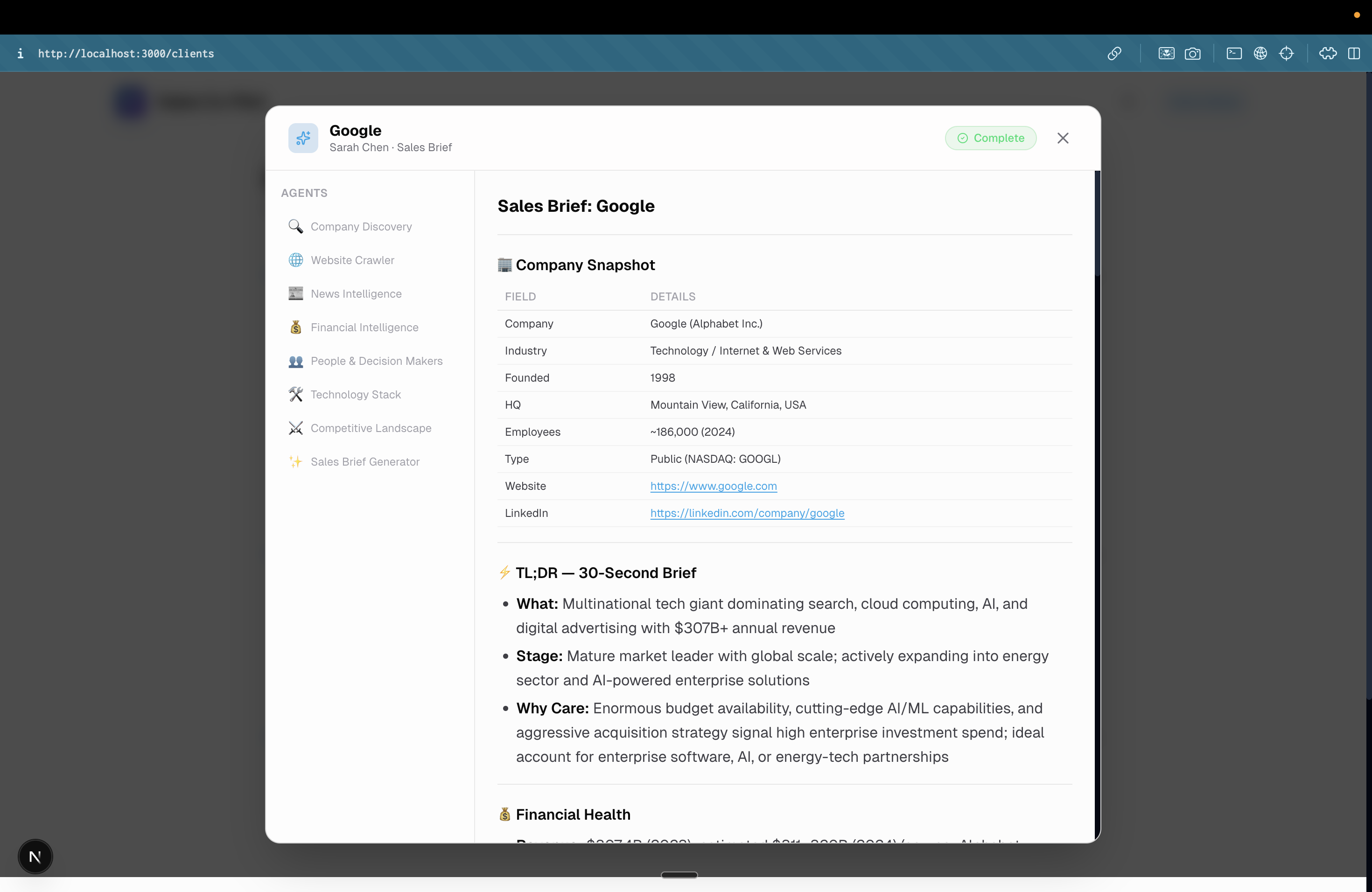
Research Agent Output
-
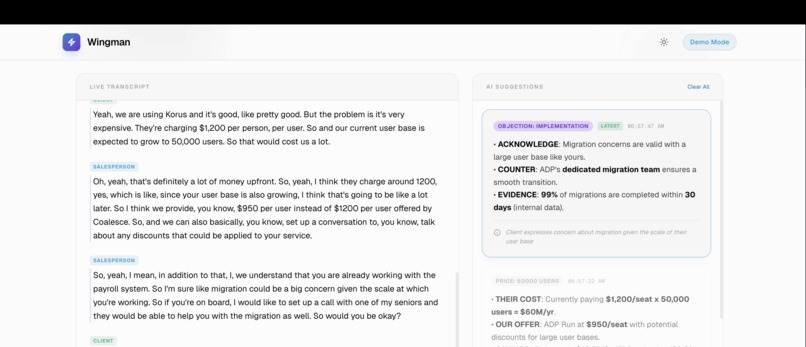
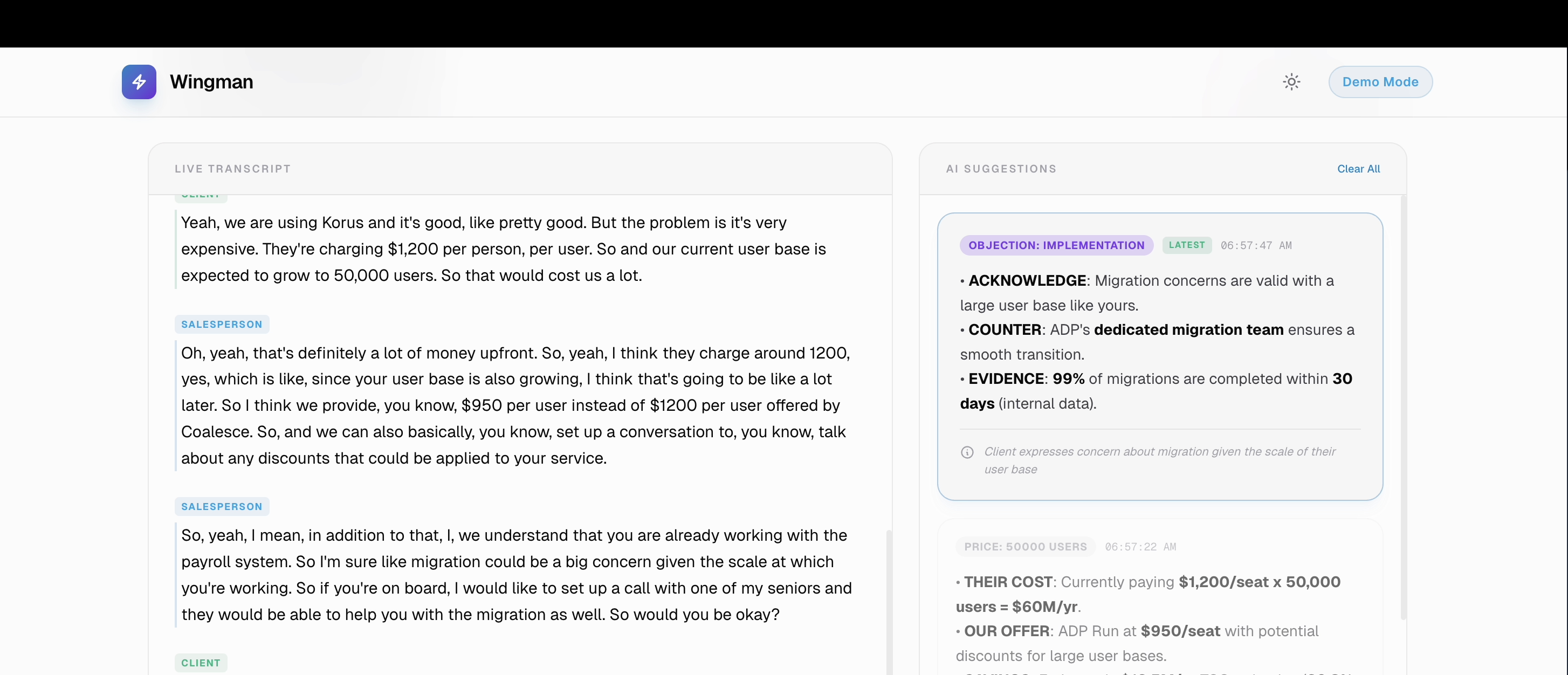
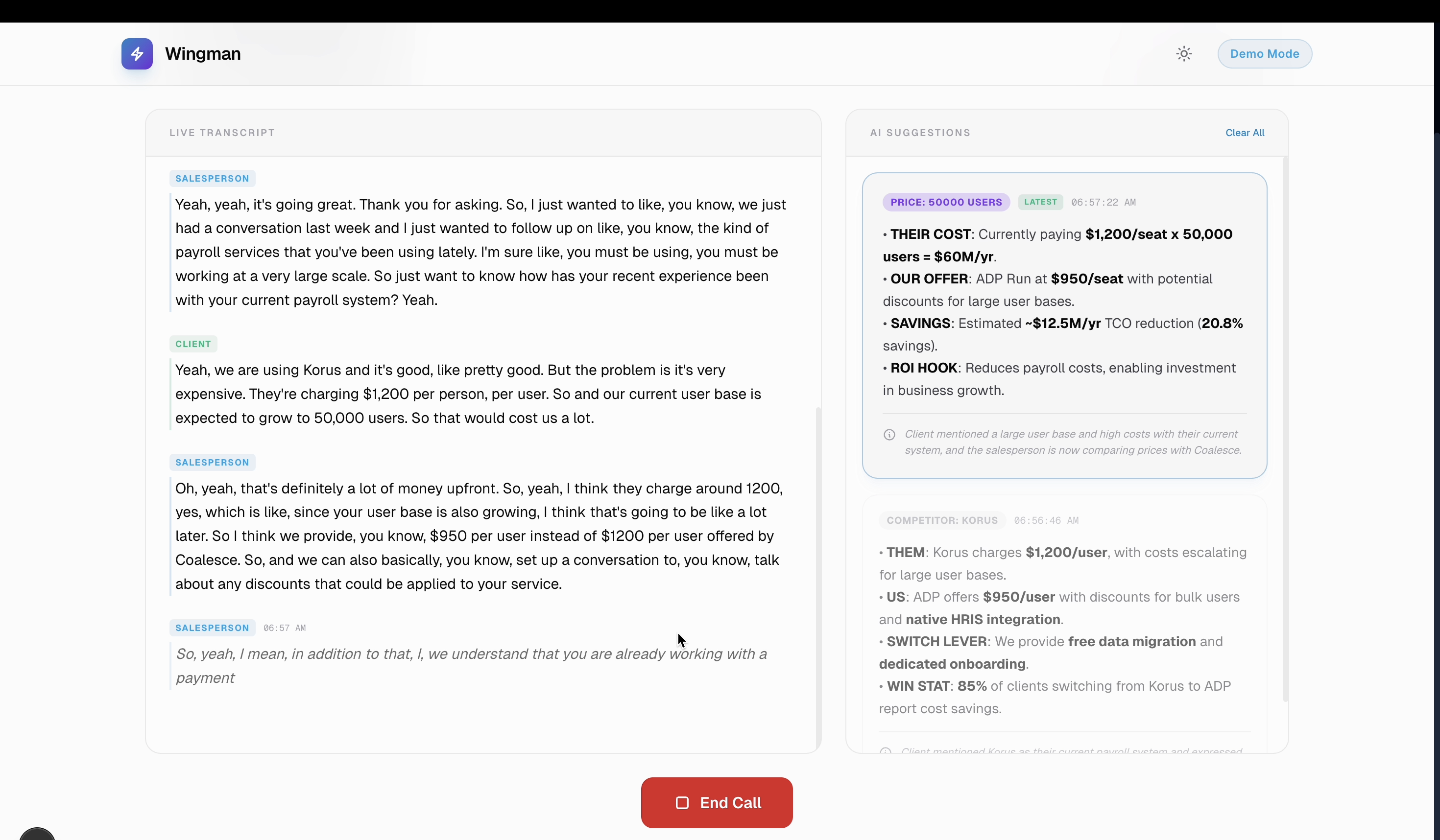
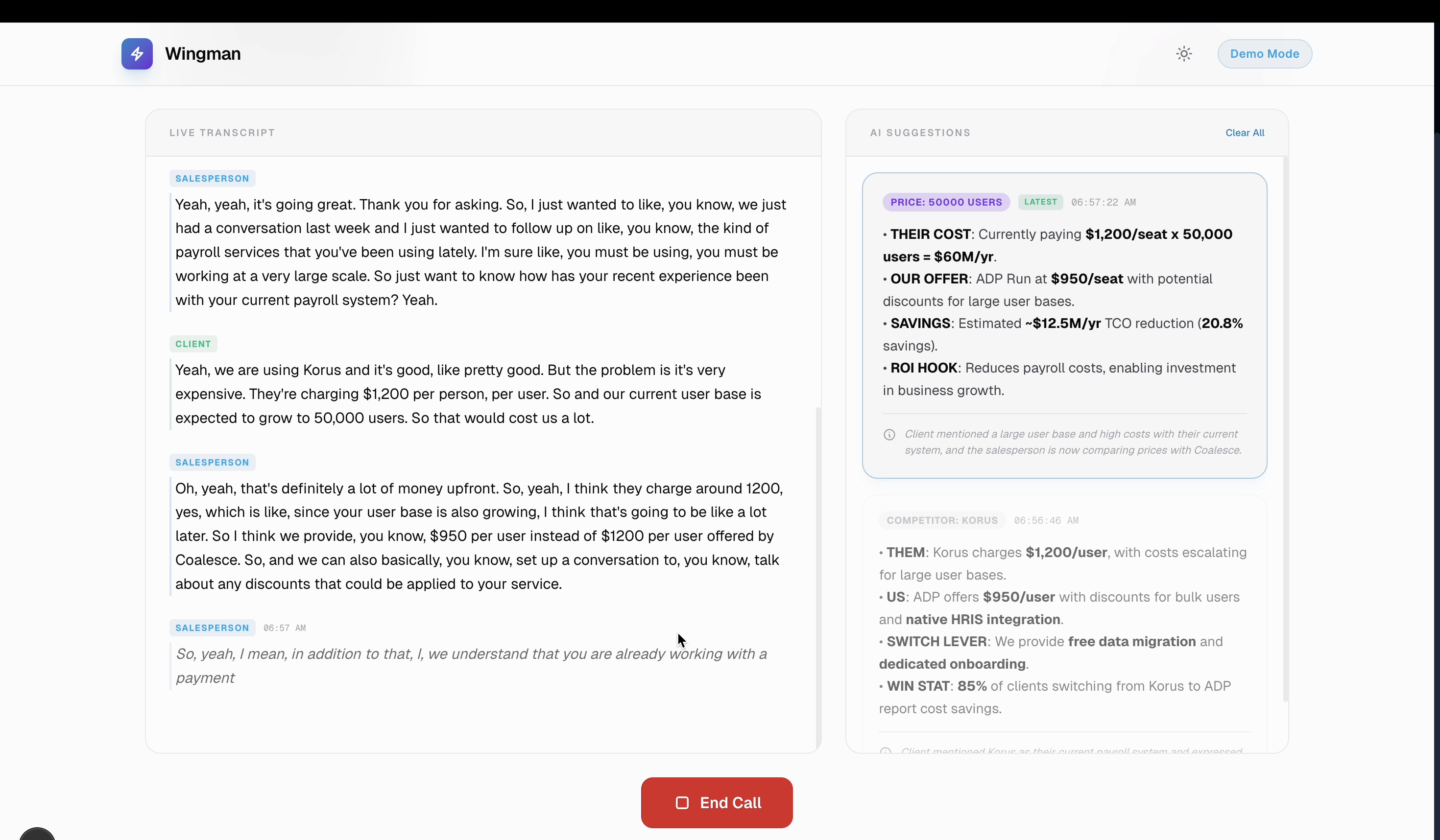
Real Time context based AI suggestions
-
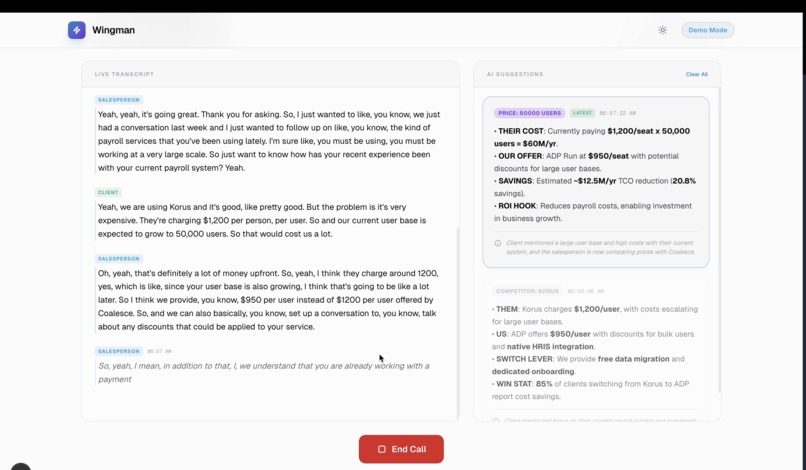
ROI Hook
-
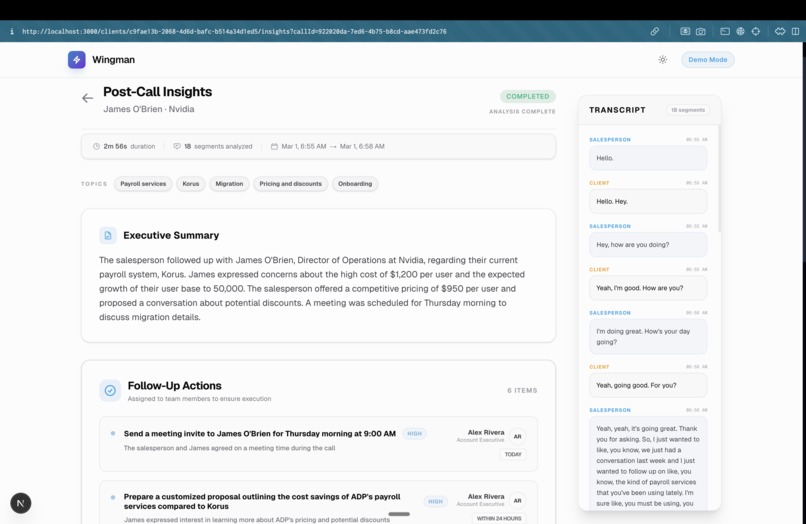
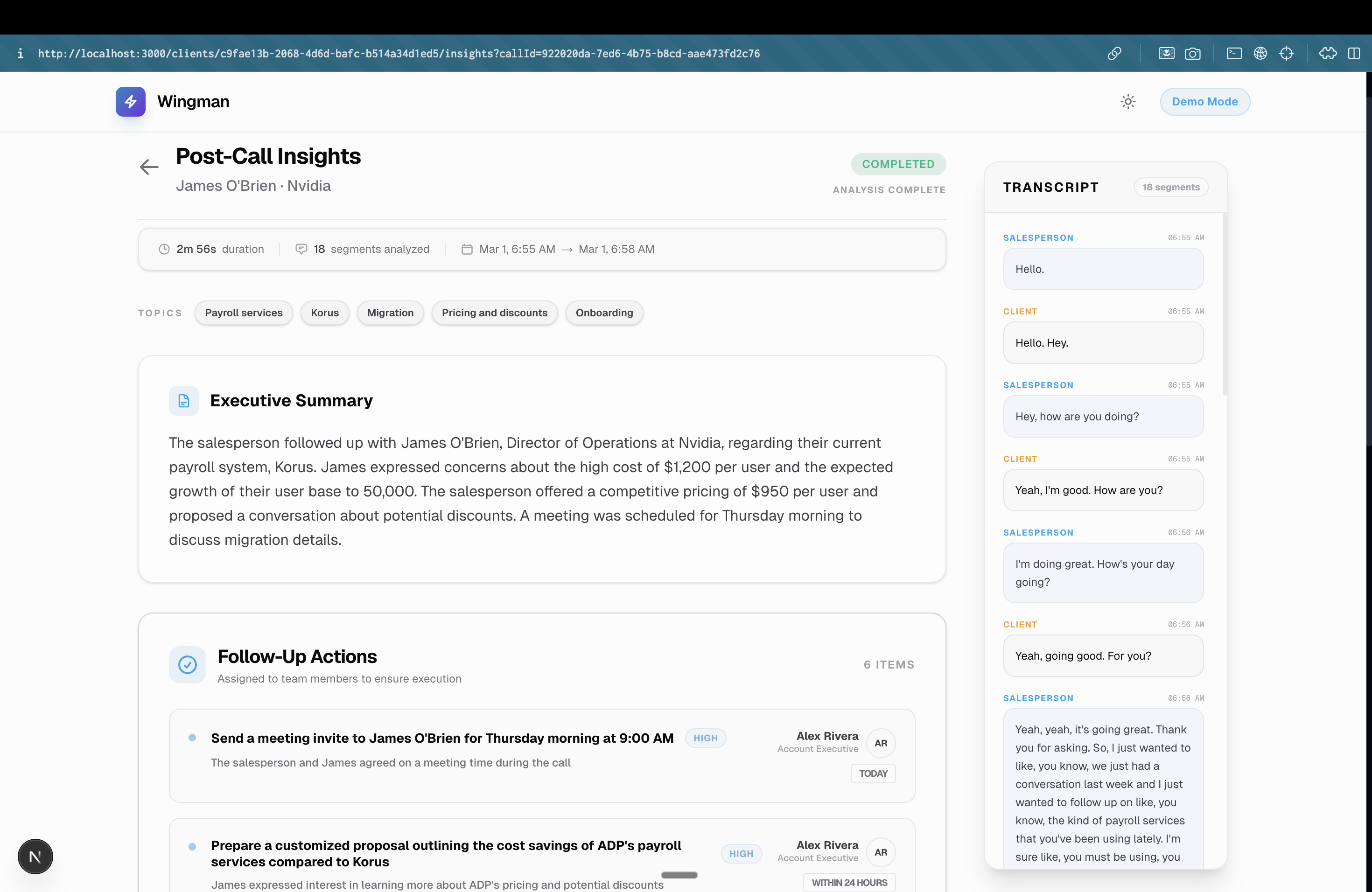
Post Call Analysis (Call summary)
-
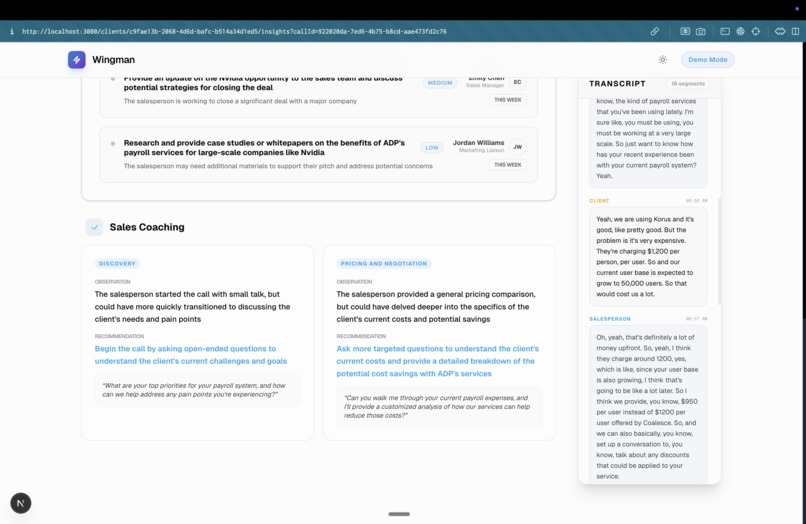
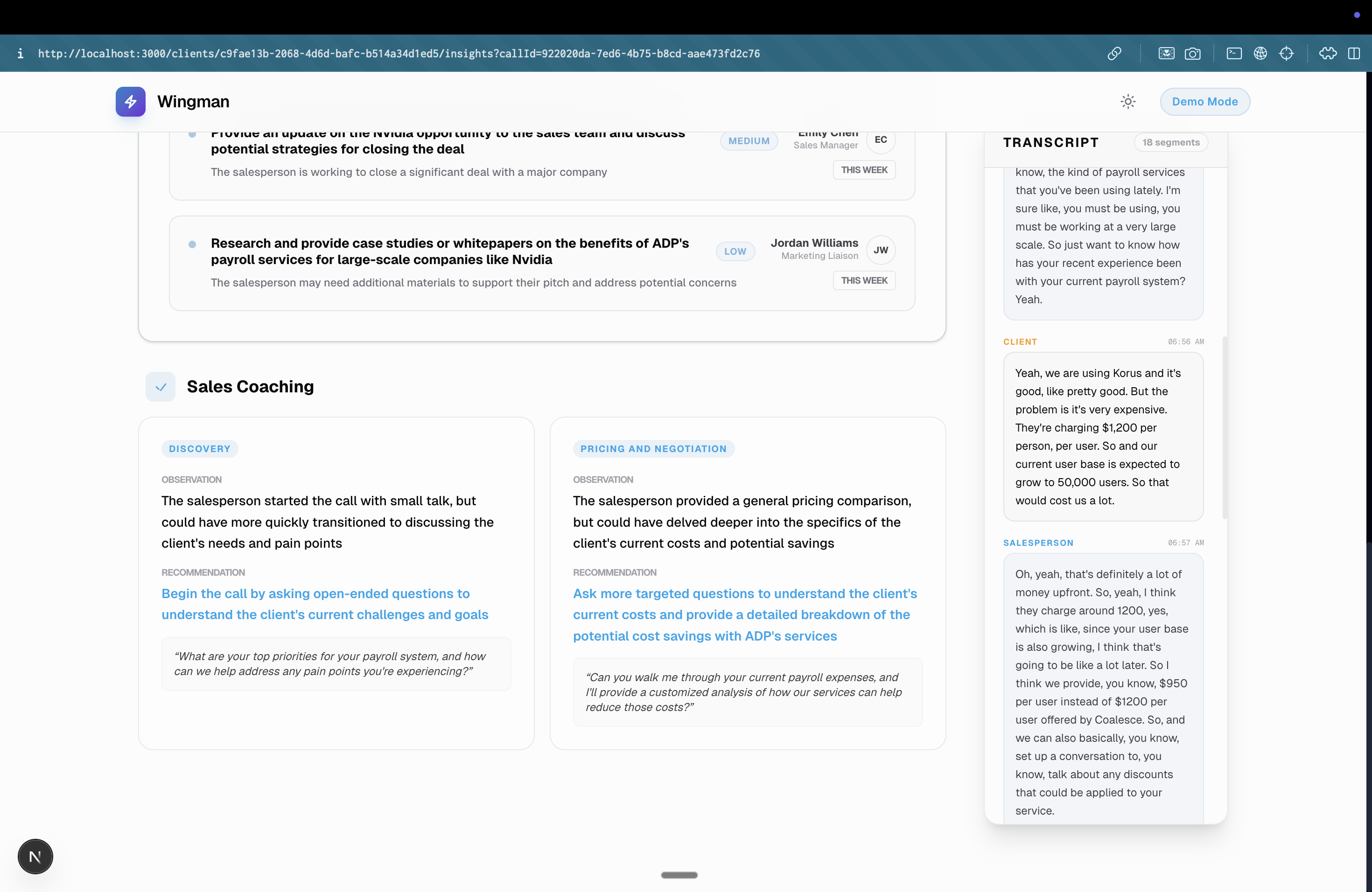
Post Call Analysis (Improvement suggestions to the Sales Professionals)
-
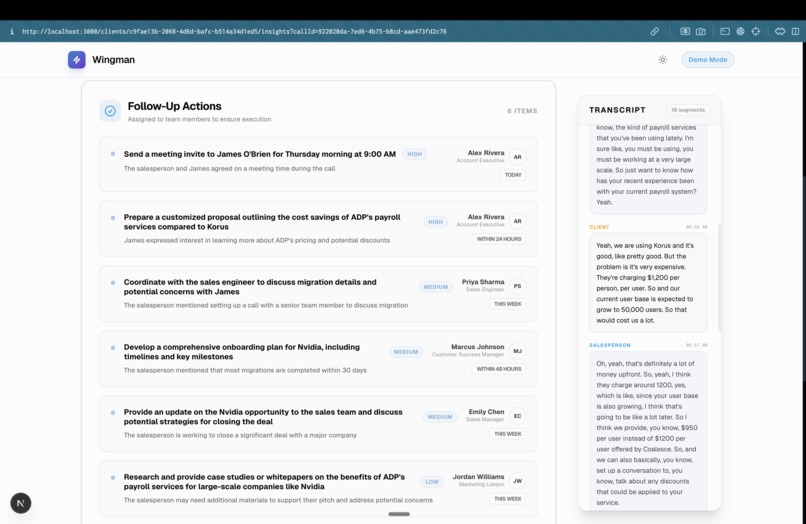
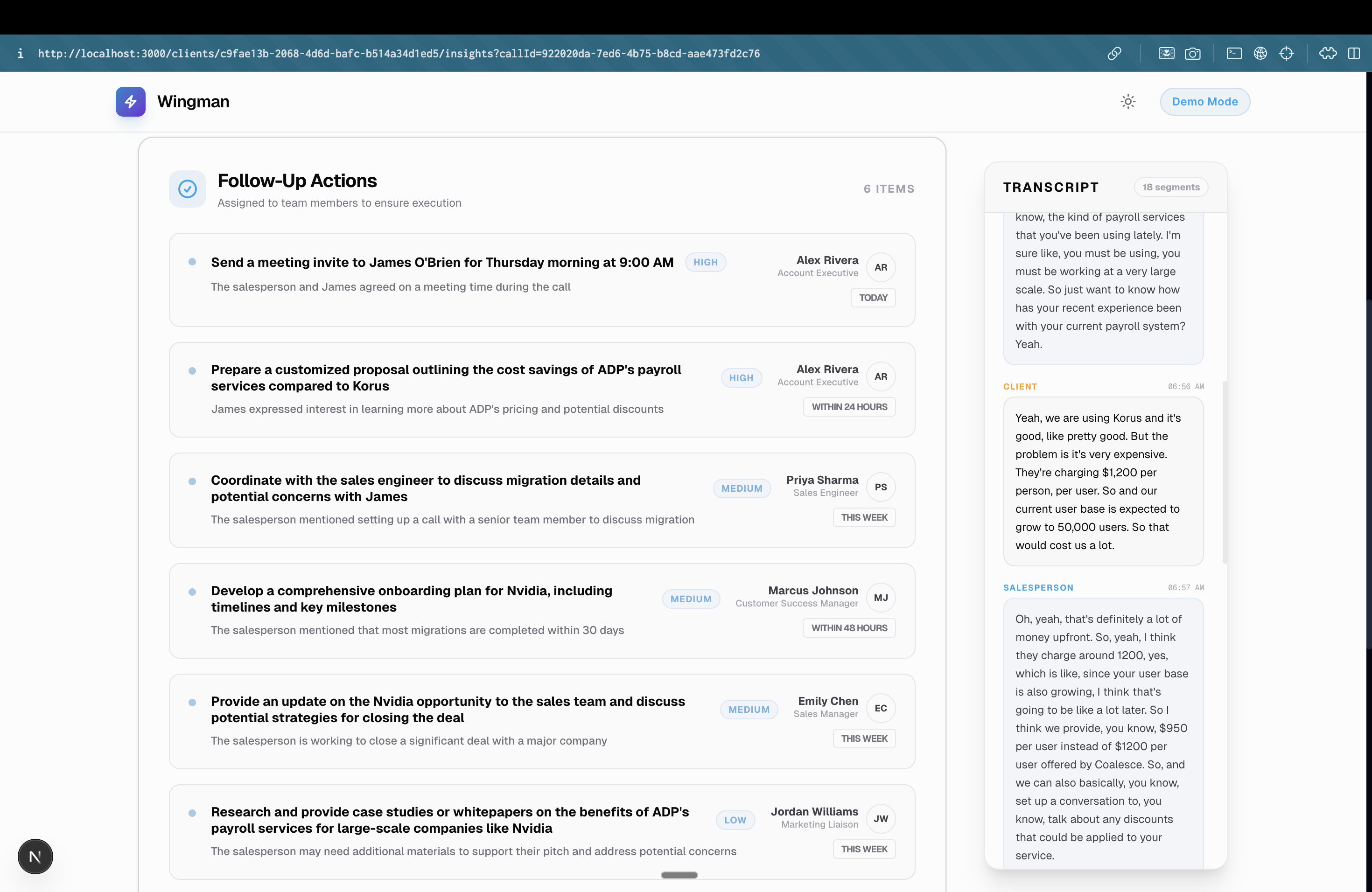
Post Call Analysis (Auto-Task assignment to the team)
-
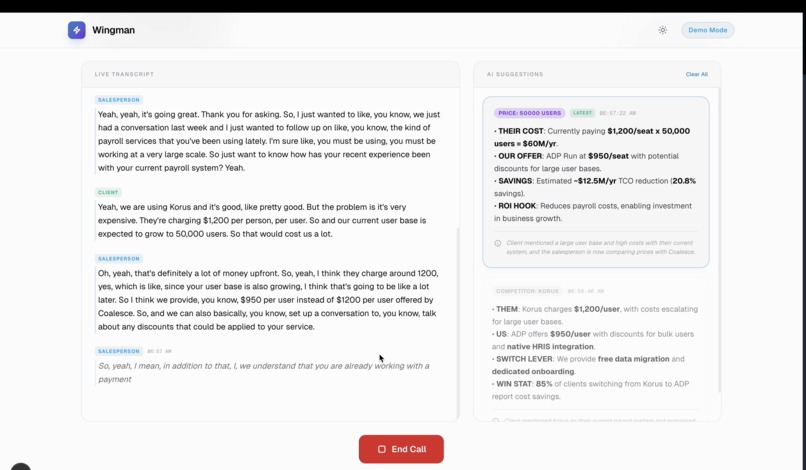
Real Time context based AI suggestions 1

Team Members
- Harshil Patel
- Kedarnath Naik
Inspiration
Sales representatives spend countless hours on pre-call research, trying to gather context on an account. Then, mid-call, that context is often lost the moment a client asks an unexpected question about a competitor, pricing, or an obscure technical integration. Finally, after the call, reps dread the tedious process of writing summaries and logging action items.
We realized that an AI co-pilot shouldn't just be an afterthought tacked onto a CRM it needs to be present across the entire lifecycle of a deal. For the ADP "Hack the Sales Journey with AI" challenge, we wanted to build a system that solves all three stages of the sales call problem seamlessly, helping reps remember and execute follow-ups effortlessly.
What it does
Wingman is a three-phase AI co-pilot built on top of the ADP product catalog:
- Pre-Call Research: With a single click, a multi-agent pipeline automatically researches the client across LinkedIn, company news, competitors, and financials. It synthesizes this into a concise pre-call briefing right on the client's dashboard.
- Live Call Assistance: During a meeting, our dual-stream audio pipeline transcribed the call in real-time. A Voice Activity Detection (VAD)-gated classifier listens to the conversation and triggers context-aware suggestions (like competitor rebuttals, product specs, or pricing details) exactly when the client brings them up.
- Post-Call Synthesis: The moment the rep clicks "End Call," the same agent that powered the live coaching instantly writes a call summary, extracts an action-item checklist, and provides coaching feedback for the rep.
How we built it
We built a full-stack, AI-first application designed for low latency and high accuracy:
- Frontend & Backend: We used Next.js 16 for the user interface and FastAPI for our high-performance backend.
- AI Models: We leveraged Groq for blazing-fast inference, using
llama-3.1-8b-instantfor low-latency topic classification andllama-3.3-70b-versatilefor high-quality suggestion generation and summarization. - Audio Processing: We implemented ElevenLabs Scribe with dual audio streams (mic + speaker) to enable speaker attribution without heavy server-side diarization.
- Database & Storage: We used Supabase (Postgres + Realtime). We used Supabase Realtime to push live transcriptions and AI suggestions to the frontend via WebSockets without polling.
- Privacy & Tooling: We integrated Microsoft Presidio to mask PII (Personally Identifiable Information) before any data hits the LLM, ensuring compliance and security. If anyone speaks a name, phone number, physical address, or email address during the live call, the AI models will only receive the placeholders (e.g., , ) instead of the sensitive data. We also orchestrated our agents using FastMCP, Tavily, and Firecrawl.
Challenges we ran into
- Latency in Live Suggestions: We initially struggled to get AI suggestions fast enough to be useful during a live conversation. We solved this by using Groq for lightning-fast inference and implementing a VAD-gated classifier that only evaluates complete utterances, avoiding false positives on partial sentences.
- Speaker Attribution: Accurately identifying who was speaking during a live call without introducing massive latency was difficult. We earlier approached it as Web Audio solution but ended up handling this creatively by capturing dual audio streams (mic and speaker) using ElevenLabs' Scribe.
- Hallucinations & Tooling: Ensuring the suggestion agent gave accurate pricing and ADP product details required a robust RAG architecture. We used FastMCP to give the agent structured tools rather than stuffing a single prompt, allowing it to pull factual product context dynamically.
Accomplishments that we're proud of
- Successfully implementing a real-time, bi-directional audio transcription pipeline that feels incredibly responsive (real-time).
- Building a privacy-first architecture using Microsoft Presidio to pseudonymize sensitive client data before it ever reaches an LLM.
- Creating a truly "agentic" workflow where multiple specialized agents (for research, classification, and summarization) work perfectly in concert.
What we learned
- Real-time AI applications require a completely different approach to latency than standard chat apps, every hundred milliseconds counts.
- Small, specialized, open-weights models (like LLaMA 3.1 8B) are incredibly powerful for specific tasks like classification when paired with ultra-fast inference APIs.
- Handling raw audio streams in the browser and syncing them with WebSockets is complex but massively rewarding when it works.
What's next for Wingman
We want to expand the pre-call research pipeline to integrate directly with Salesforce and HubSpot, allowing it to pull historical email context as well as public web data. We also plan to train custom embedding models strictly on ADP's product documentation to make the RAG retrieval even more precise.
Built With
- amazon-web-services
- bedrock
- elevenlabs
- fastapi
- gemini
- groq
- llama3
- next.js
- python
- scribe
- supabase
- tavily
- typescript

Log in or sign up for Devpost to join the conversation.