-
Paste a project description into the form.
-
Our model will attempt to predict whether a project will win an award.
-
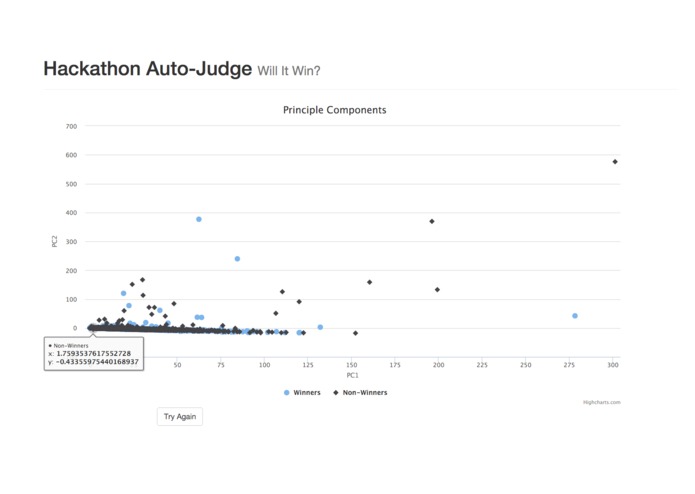
The hackathon Auto-Judge is still learning to distinguish winning projects from the rest.
Inspiration
We both wanted to sharpen our data science skills and make a super meta hackathon project at the same time.
What it does
Given only text from a devpost project description, our app predicts whether or not that project will win an award.
How we built it
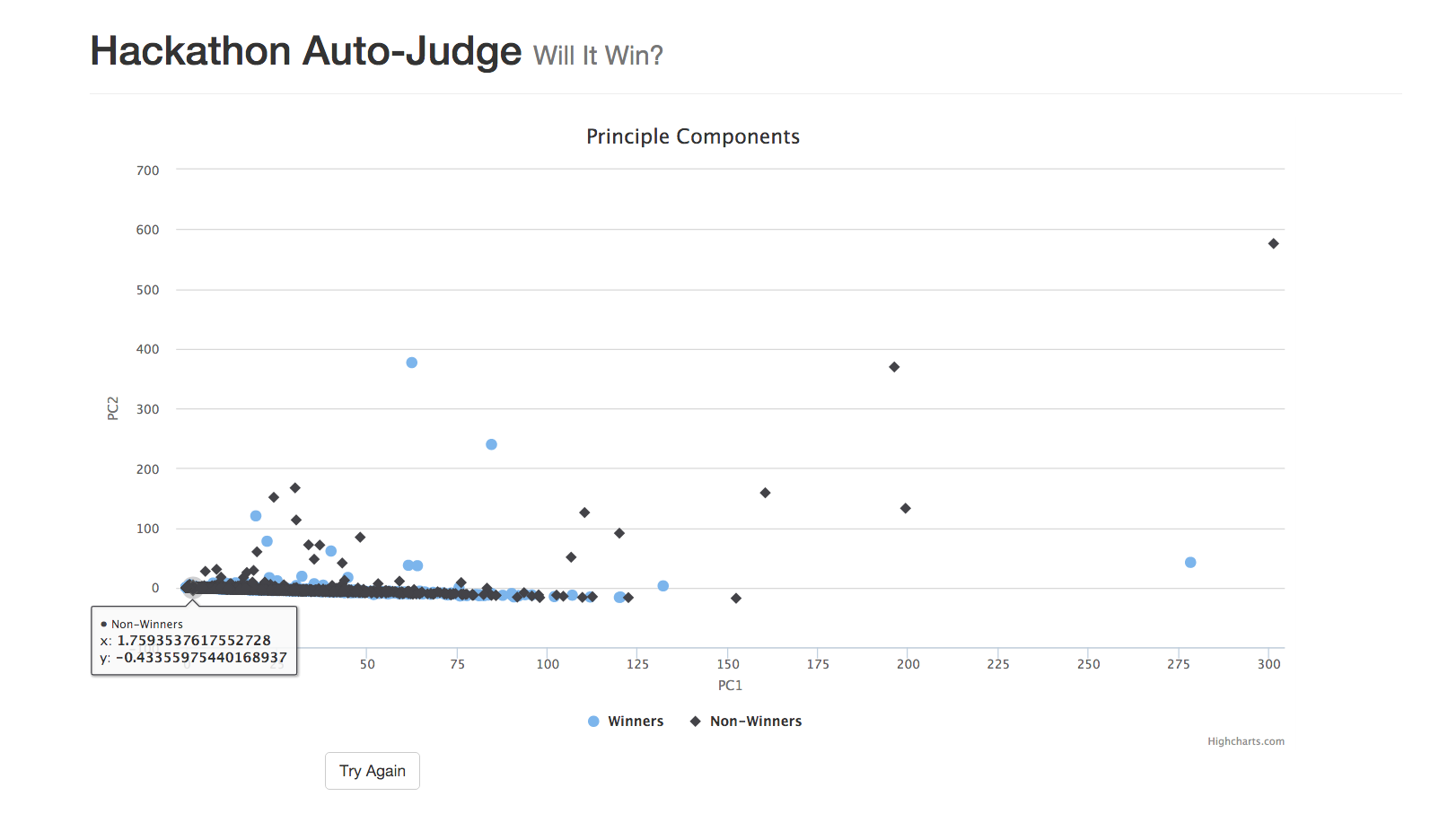
First, we scraped every single project on devpost. (Python, beautiful-soup) We then trained classifiers on "bag-of-words" representations of the projects. (scikit-learn: PCA, SVM) Finally, we deployed our model to the web to fulfill it's destiny as an automated hackathon judge.
Challenges we ran into
- Scraping devpost was a pain in the rear. Why do they not have an official API???
- Text data can be counterintuitive. We did a bunch of stuff we though should substantially improve model performance. Our test accuracy decreased. FML frownie-face.
- It turns out, our model only predicts losses. If 30 percent of all projects get some kind of prize, we can achieve 70 percent accuracy by classifying all projects as non-winners. We have failed to show that word counts can distinguish winning hackathon projects from the rest.
Accomplishments that we're proud of
- We scraped almost 50 MB of project descriptions from devpost
- We learned some tough lessons about what can go wrong when building a classifier.
- We made it to the final round in the cup stacking competition.
What we learned
- How to build a classifier and put it on the web.
- "Better than a coin-toss" doesn't mean your model isn't worthless.
What's next for Will It Win?
Deep Learning and hackathon project creation using "Deep Dream." trippy...






Log in or sign up for Devpost to join the conversation.