-
-
Sign Up Page
-
Login Page
-
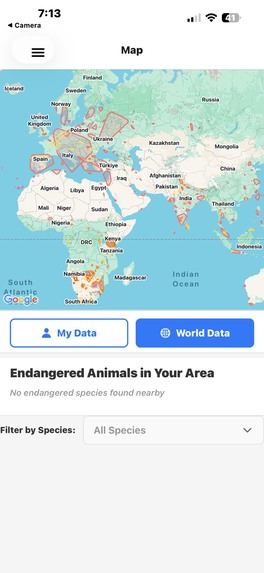
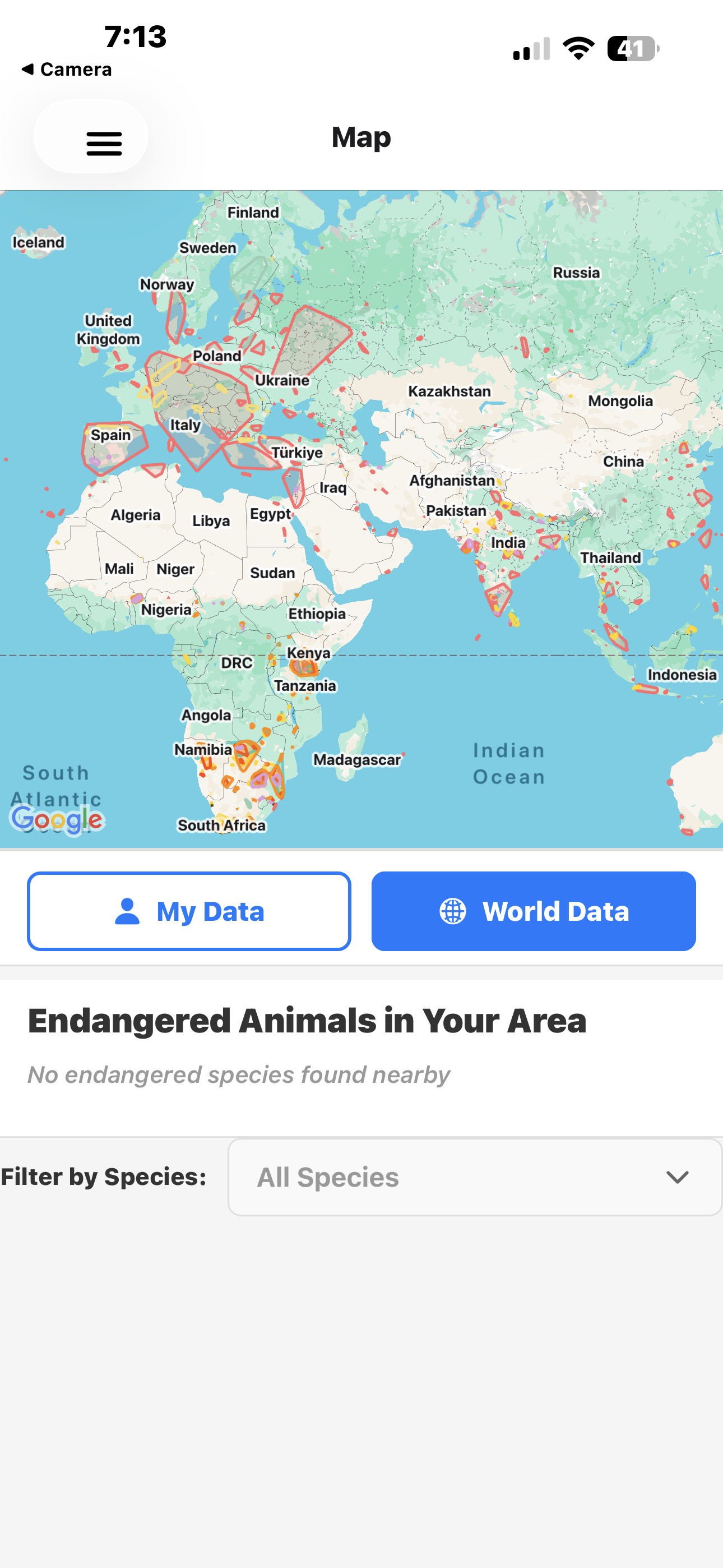
World Data Map For Public Users
-
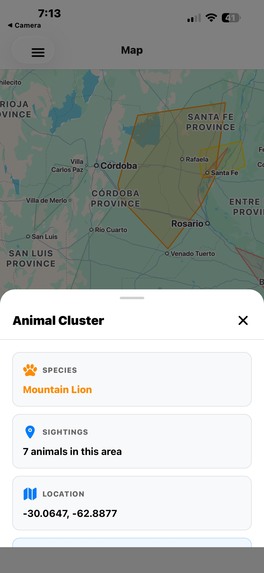
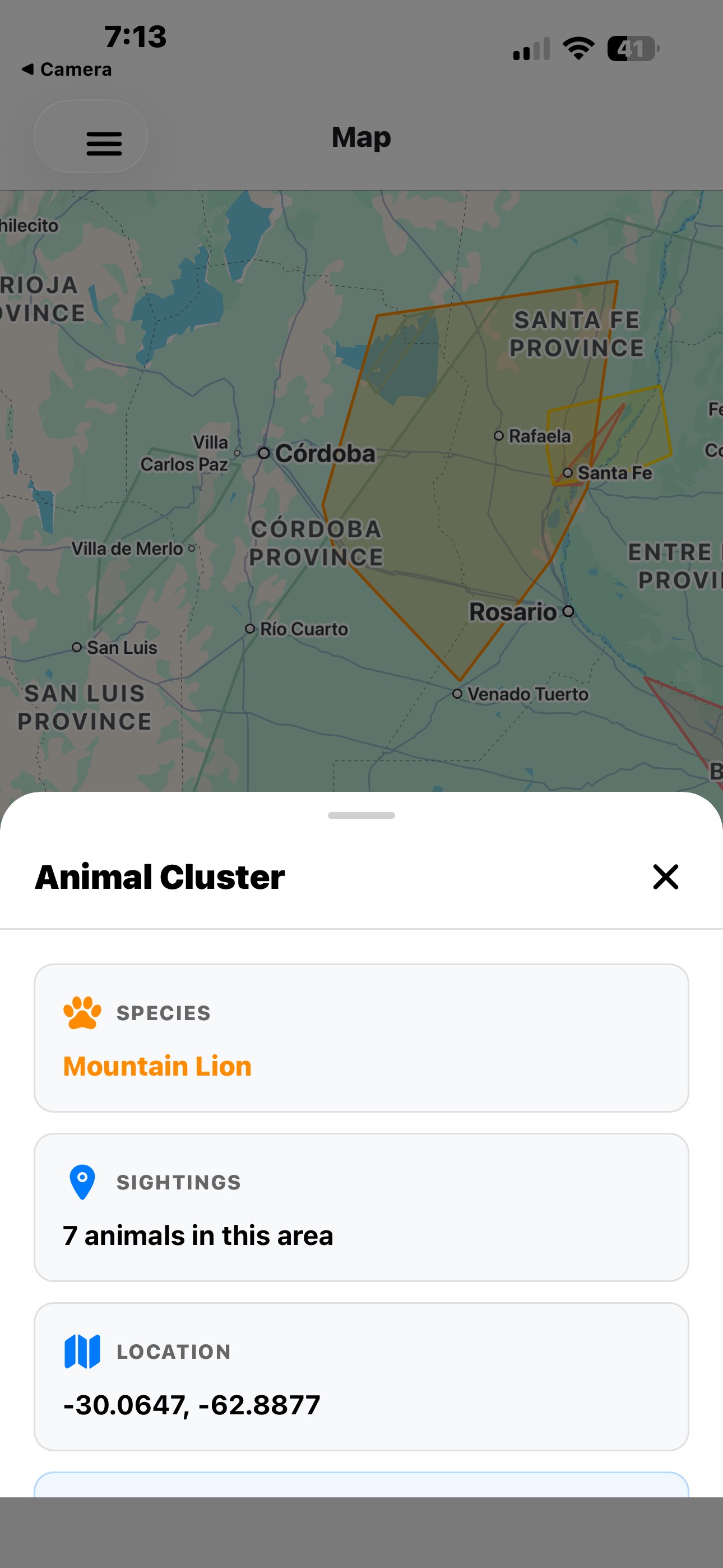
Zone Information Popup
-
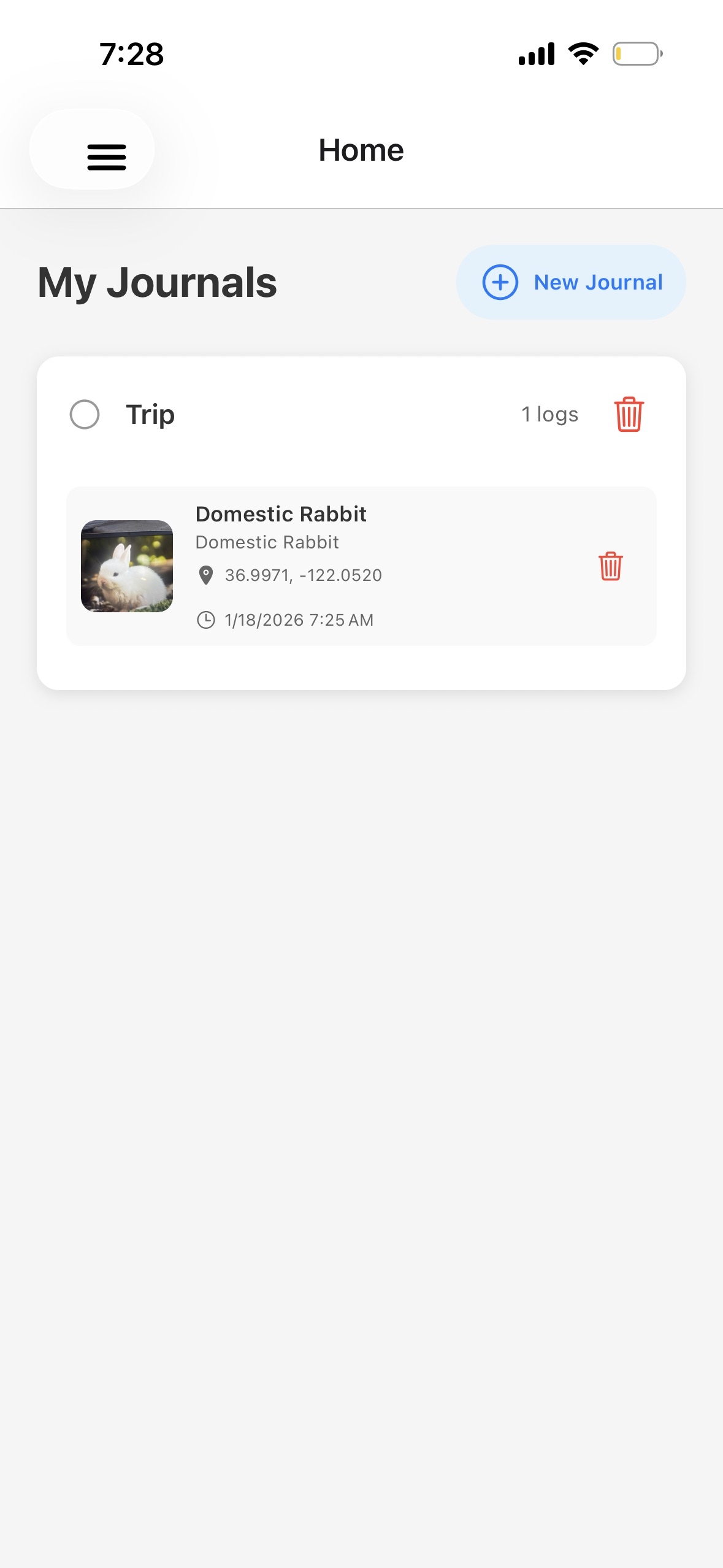
home page
-
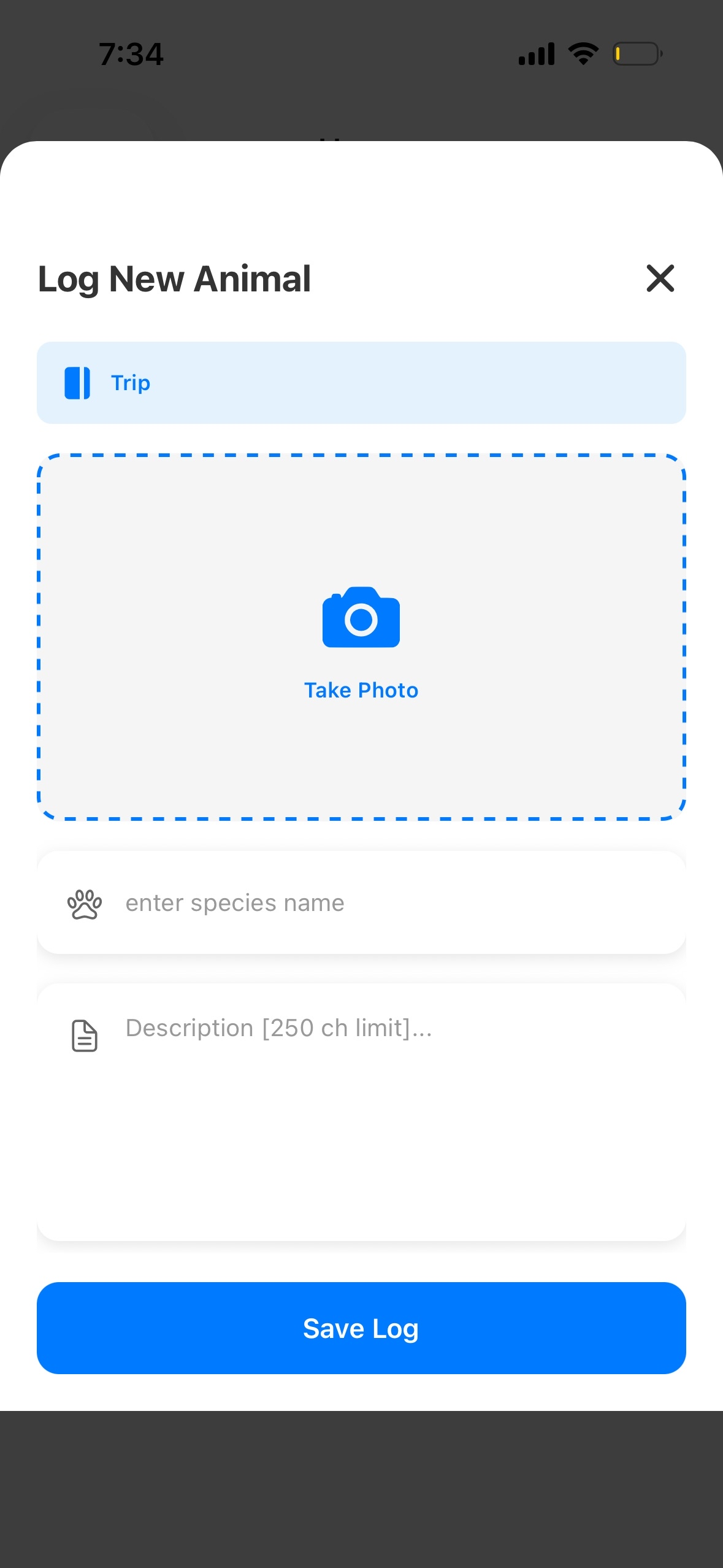
Log creation page
-
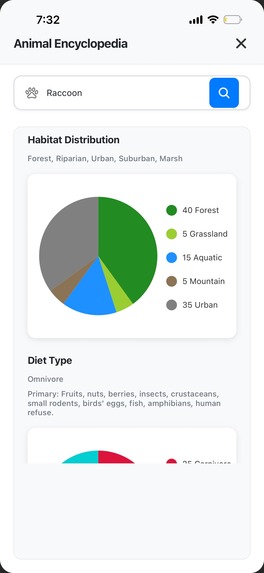
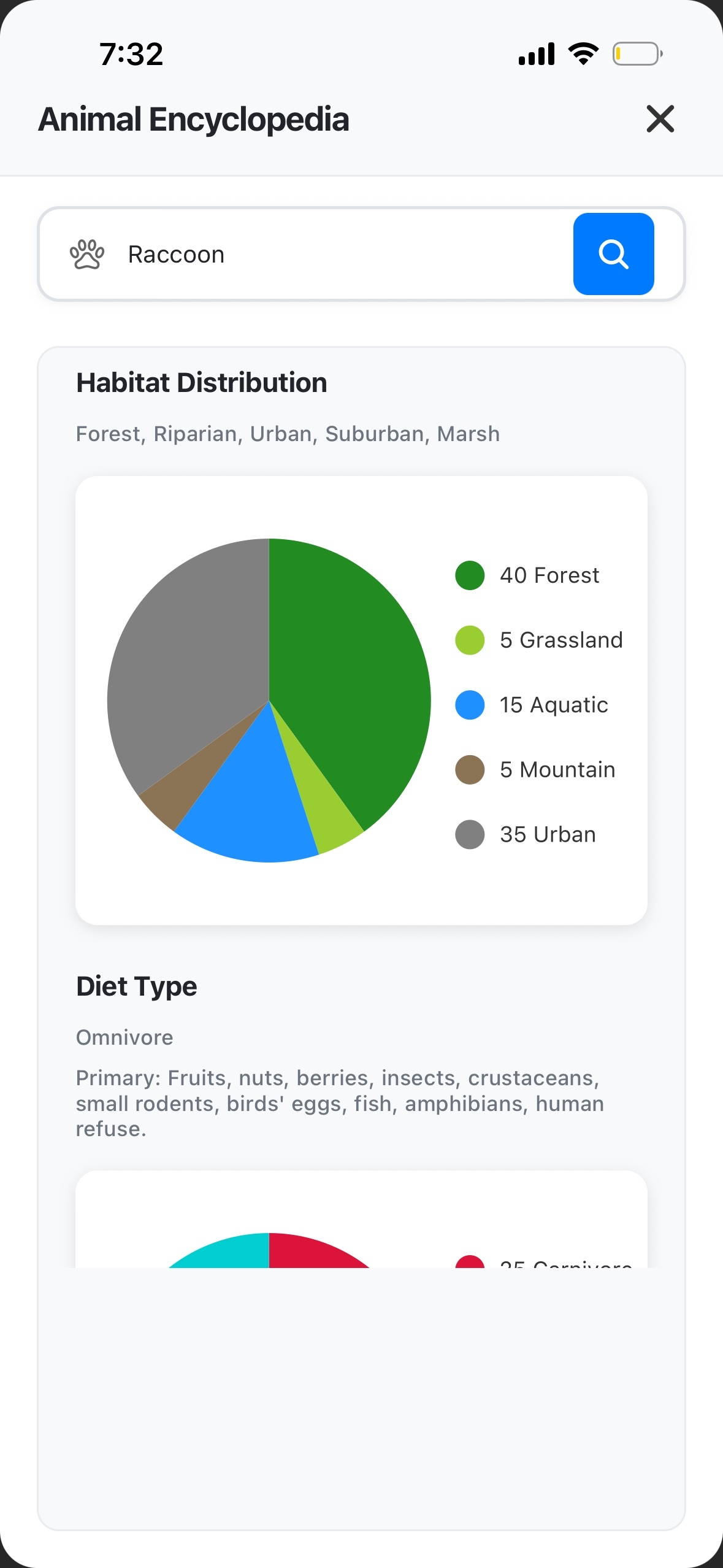
Animal Encyclopedia page
-
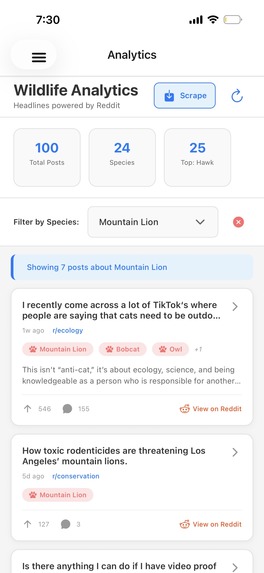
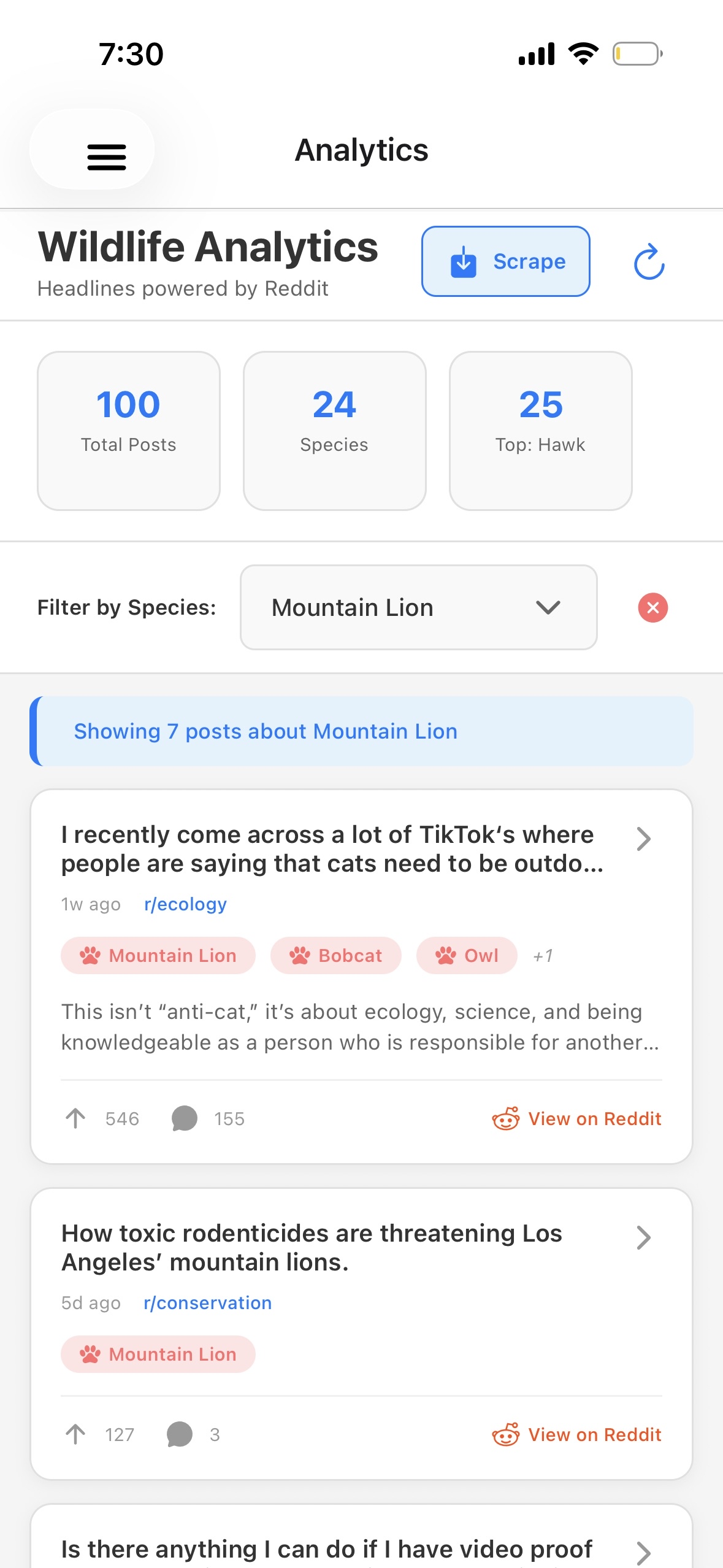
Analytics page
-
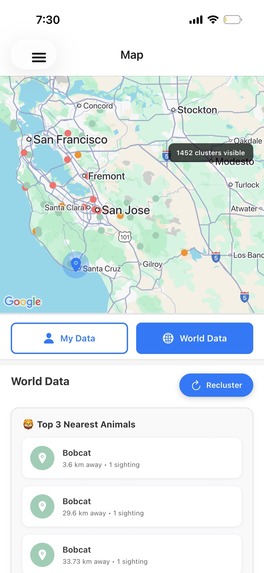
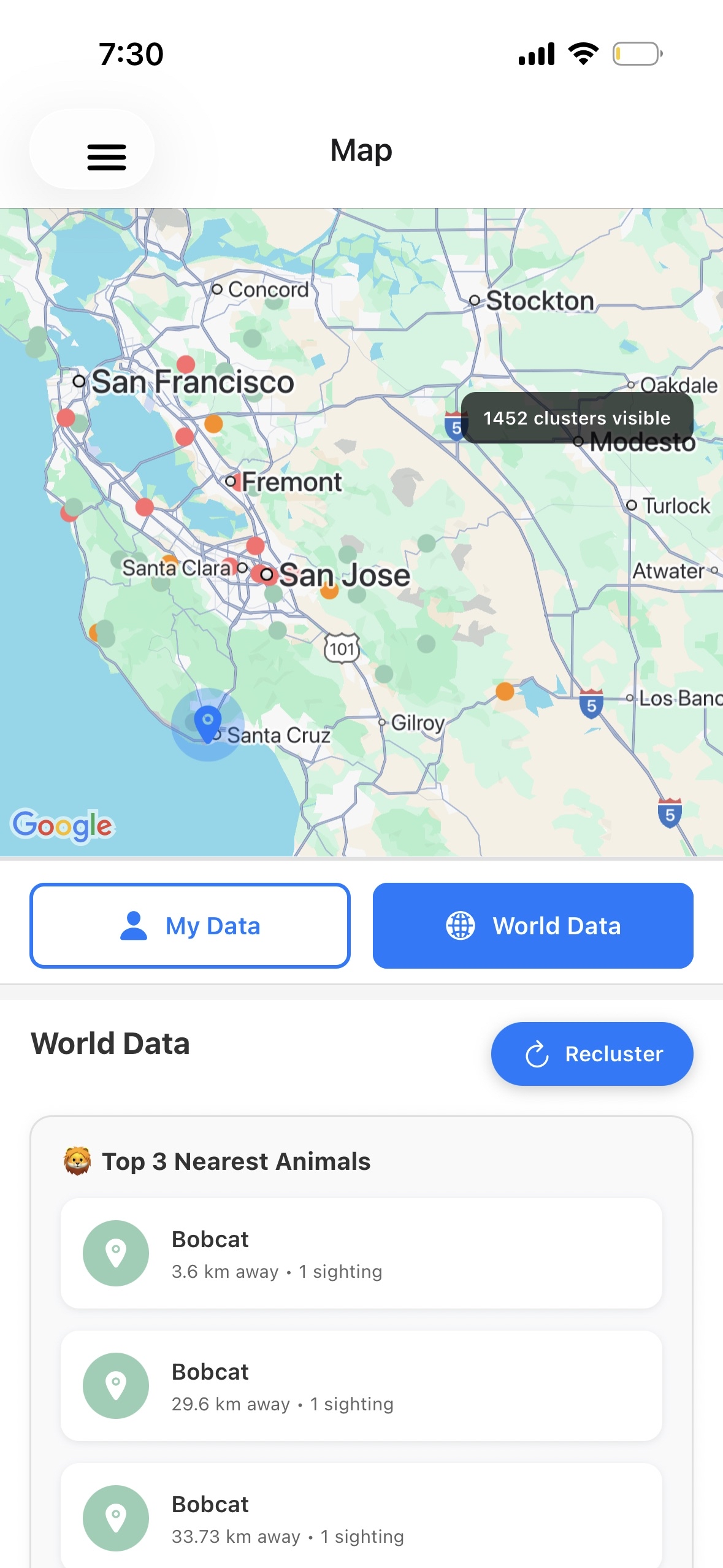
World data page with world map
-
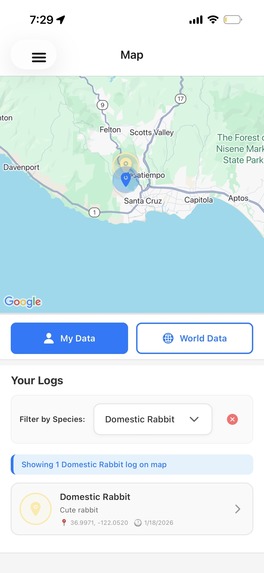
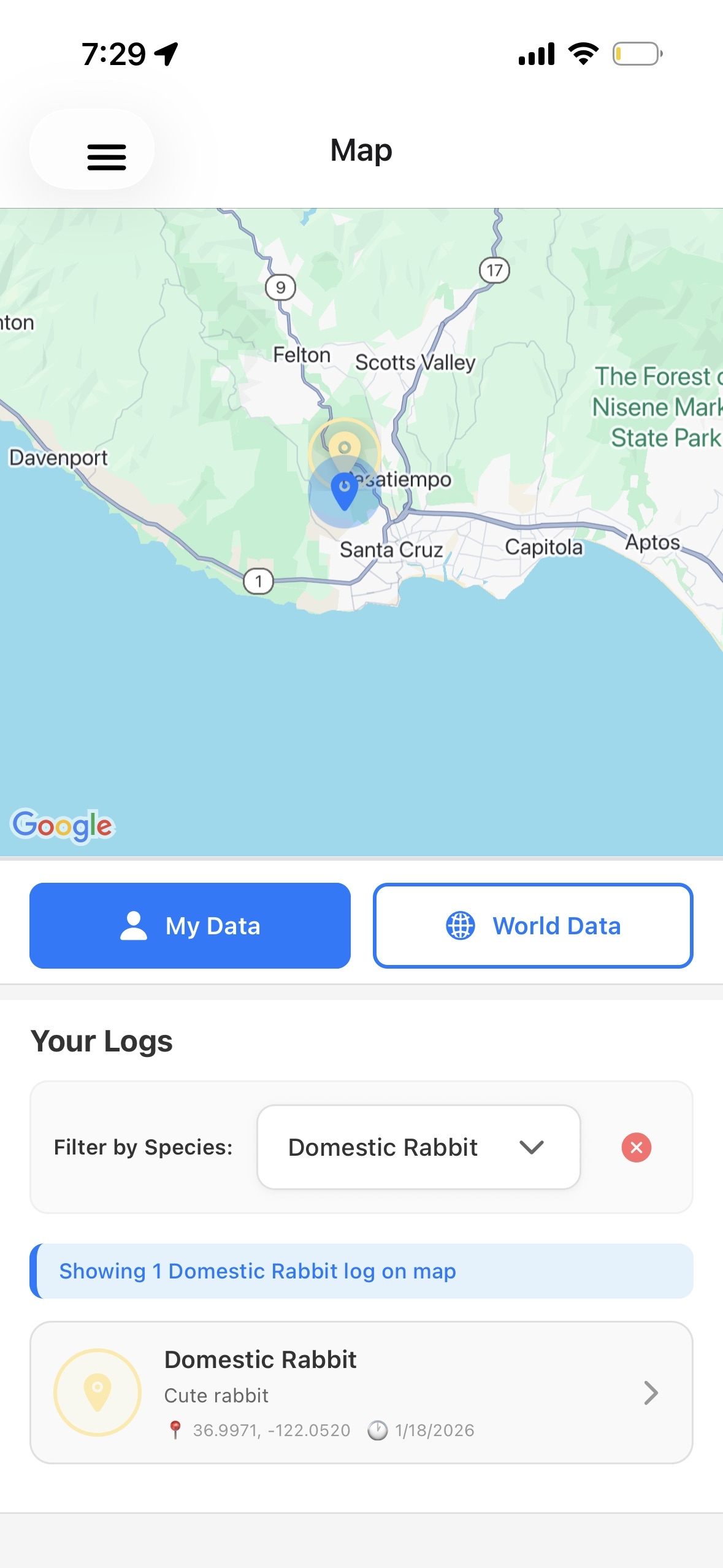
user data page with map
WildTrack: AI-Powered Wildlife Conservation Platform for Enthusiasts and Professionals.
Inspiration
Wildlife poaching and habitat destruction remain critical threats to endangered species worldwide. Traditional conservation efforts often rely on fragmented data and delayed reporting, making it difficult to protect animals in real-time. We were inspired by the idea of empowering both citizen scientists and field researchers with a unified platform that turns everyday wildlife sightings into actionable conservation intelligence while ensuring sensitive location data doesn't fall into the wrong hands.
What it does
WildTrack is a full-stack mobile and web platform that enables users to report wildlife sightings, which are then processed using machine learning to create intelligent geofence zones around animal habitats. The system aggregates data from multiple sources—citizen scientists, field researchers, and social media—to build a comprehensive wildlife intelligence network.
Key Features:
- Role-Based Data Access: Field researchers see exact GPS coordinates and individual sightings, while public users only see general habitat boundaries—preventing poachers from exploiting precise location data
- DBSCAN Clustering: Automatically groups 69,507+ GPS observations into meaningful habitat zones for 119+ endangered species using scikit-learn's DBSCAN algorithm with Haversine distance calculations
- Real-Time Data Ingestion: Collects observations from citizen scientists via React Native mobile app with GPS tracking and photo uploads
- Interactive Maps: Visualize species distributions, habitat boundaries, and cluster centers using react-native-maps with custom markers and polygons
- AI Image Detection: Auto-detects animal species from uploaded photos using Gemini
- Animal Encyclopedia: Searches for animal information online and displays nice charts with a detailed descriptions using Gemini
- Reddit Data Aggregation: Scrapes wildlife subreddits (r/wildlife, r/animalid, r/conservation, etc.) using Reddit's public JSON API to extract endangered species sightings and location data
- Analytics Dashboard: Real-time charts showing species distribution, sighting trends, and top endangered animals in user's area using react-native-chart-kit
- Spatial Grid Clustering: Optimized clustering algorithm using spatial grid partitioning (0.1° ≈ 11km cells) for O(n) performance instead of O(n²)
- In-Memory Caching: 5-minute TTL cache for observation data to reduce database load and improve API response times
How we built it
Backend Architecture
Framework & API:
- FastAPI with async/await for high-performance REST API
- Uvicorn ASGI server with automatic API documentation at
/docs - Pydantic models for request/response validation
- SlowAPI for rate limiting (configurable per endpoint)
- CORS middleware for cross-origin requests
Database:
- Supabase (PostgreSQL) with PostGIS extension for geospatial queries
- Row-Level Security (RLS) policies for role-based access control
- 14 SQL migration scripts managing schema evolution:
observationstable: Stores GPS coordinates, species, timestampszonestable: Pre-computed habitat boundaries with convex hull polygonsreddit_sightingstable: Scraped social media data with metadataendangered_speciestable: Reference data for 119+ speciesjournalsandlogstables: User-generated observation recordsprofilestable: User roles (field_researcher vs public)
Machine Learning Pipeline:
- DBSCAN Clustering: scikit-learn implementation with custom distance metrics
- Epsilon: 0.01 degrees (≈1km) for habitat zone detection
- Min samples: 3 points per cluster
- Processes 2,000-4,000 points per clustering run (sampled from 69k+ total)
- Convex Hull Generation: SciPy for habitat boundary polygon creation
- Spatial Grid Optimization: Custom grid-based clustering (0.1° cells) reducing complexity from O(n²) to O(n)
- Haversine Distance: NumPy-optimized calculations for accurate geospatial measurements
Data Processing:
- Background task processing for Reddit scraping (FastAPI BackgroundTasks)
- Batch processing with pagination (100 records/page) for large datasets
- In-memory caching with 5-minute TTL to minimize database queries
- Point sampling algorithms to limit processing to 4,000 points for performance
External Integrations:
- Reddit JSON API scraping (no authentication required, public endpoints)
- Geopy/Nominatim for reverse geocoding location names
- Hugging Face transformers for AI image classification
- PyTorch for deep learning inference
Frontend Architecture
Mobile App:
- React Native 0.81.5 with Expo SDK 54
- Expo Router for file-based navigation
- TypeScript for type safety
- React Native Maps for interactive map visualization
- Expo Location for GPS tracking with continuous updates
- Expo Image Picker for camera integration
- AsyncStorage for local token persistence
State Management:
- React Hooks (useState, useEffect, useMemo, useCallback)
- Custom API service layer with error handling
- Optimistic UI updates for better UX
UI Components:
- Custom modals with ScrollView for log details
- Species-specific icon mapping with color coding
- Cluster visualization with pulse animations
- Real-time location tracking with user position markers
- Chart visualizations (PieChart, BarChart) for analytics
Authentication:
- Supabase Auth with JWT tokens
- AsyncStorage for session persistence
- Automatic token refresh handling
- Role-based UI rendering (researcher vs public views)
Data Scraping
Reddit Integration:
- Public JSON API endpoints (no OAuth required)
- Scrapes 9 wildlife-focused subreddits
- Species detection via keyword matching against 119+ endangered species
- Location extraction using geopy/Nominatim from post text
- Background processing with FastAPI BackgroundTasks
- Duplicate detection via reddit_id to prevent re-scraping
- Metadata extraction: upvotes, comments, timestamps, author info
Data Flow:
- Scraper queries subreddits via JSON API
- Filters posts mentioning endangered species
- Extracts location data (if available)
- Saves to
reddit_sightingstable - Frontend queries via
/api/v1/reddit-sightingsendpoint
API Endpoints
/api/v1/auth/*- Authentication (signup, login, profile sync)/api/v1/journals- CRUD operations for user journals/api/v1/logs- Wildlife observation logging/api/v1/zones/*- Habitat zone queries (clusters, boundaries, nearby species)/api/v1/reddit-sightings- Social media data aggregation/api/v1/image-verification- AI image authenticity detection/api/v1/animal-search- Species encyclopedia and search
Challenges we ran into
- Balancing Accessibility vs Security: Designing a system that's useful for public conservation awareness while protecting animals from poachers required careful role-based access control implementation
- Performance at Scale: Processing 69,507 observations required optimizing DBSCAN from O(n²) to O(n) using spatial grid partitioning
- Git Merge Conflicts: Managing multiple feature branches with different directory structures and conflicting dependencies
- Reddit API Limitations: Reddit's free API tier restrictions led us to use public JSON endpoints, requiring custom scraping logic
- Real-Time Location Tracking: Implementing continuous GPS updates without draining battery required careful optimization of location polling intervals
- Type Safety: TypeScript type errors with backend API responses required extensive type definition work
Accomplishments that we're proud of
- Successfully clustered 69,507 GPS observations across 119 species into 1,000+ meaningful habitat zones using DBSCAN
- Implemented role-based data access that protects exact animal locations from potential misuse while maintaining public awareness
- Built a complete full-stack application with React Native mobile app, FastAPI REST API, Supabase database, and ML pipeline
- Created test endpoints that allow rapid development without full auth setup
- Processed real-world wildlife data from multiple sources into actionable conservation insights
- Optimized clustering performance from O(n²) to O(n) using spatial grid algorithms, enabling real-time cluster updates
- Integrated multiple data sources: citizen reports, field researcher data, and Reddit social media scraping
- Built AI-powered features: automatic species detection from photos and image verification
What we learned
- Security-First Design: The importance of considering data sensitivity in conservation tech—protecting animals requires protecting their location data
- Full-Stack Integration: Connecting React Native frontend → FastAPI backend → Supabase database → ML models requires careful API design and error handling
- Geospatial Algorithms: Implementing efficient clustering for large-scale GPS data requires understanding spatial indexing and distance metrics
- Performance Optimization: Caching, sampling, and algorithmic optimization are critical when processing 70k+ data points
- API Design: RESTful endpoints with proper error handling, rate limiting, and documentation improve developer experience
What's next for WildTrack
- Integration with Conservation Organizations: Partner with wildlife reserves and NGOs to integrate their existing data systems
- Real-Time Alerts: Notify rangers when sightings occur outside expected habitat zones (potential poaching indicator)
- Temporal Analysis: Track migration patterns and seasonal movements using time-series analysis
- Mobile Push Notifications: Alert users about nearby endangered species sightings
- Advanced ML Models: Fine-tune species detection models on domain-specific wildlife datasets
- Web Dashboard: Expand beyond mobile to web-based analytics platform for researchers
- Data Export: Allow researchers to export zone boundaries and observation data for GIS software
- Community Features: Enable users to comment on sightings and share conservation tips
Tech Stack Summary
Backend:
- Python 3.13, FastAPI, Uvicorn
- Supabase (PostgreSQL + PostGIS)
- scikit-learn, NumPy, SciPy
- Hugging Face Transformers, PyTorch
- Geopy, Requests
Frontend:
- React Native 0.81.5, Expo SDK 54
- TypeScript
- React Native Maps, Expo Location
- React Native Chart Kit
- Supabase JS Client
Infrastructure:
- Supabase (Database + Auth + Storage)
- Git/GitHub for version control
- SQL migrations for schema management
Built With
- gemini
- python
- react
- react-native
- supabase

Log in or sign up for Devpost to join the conversation.