-
-

Front Page
-
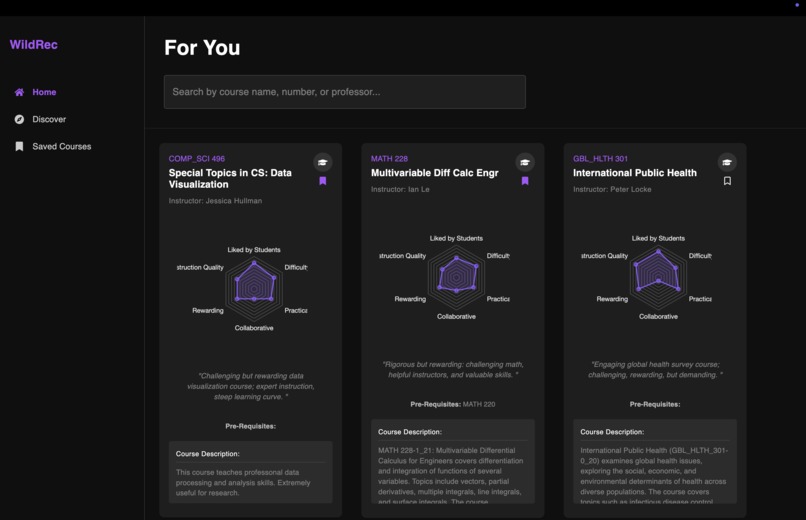
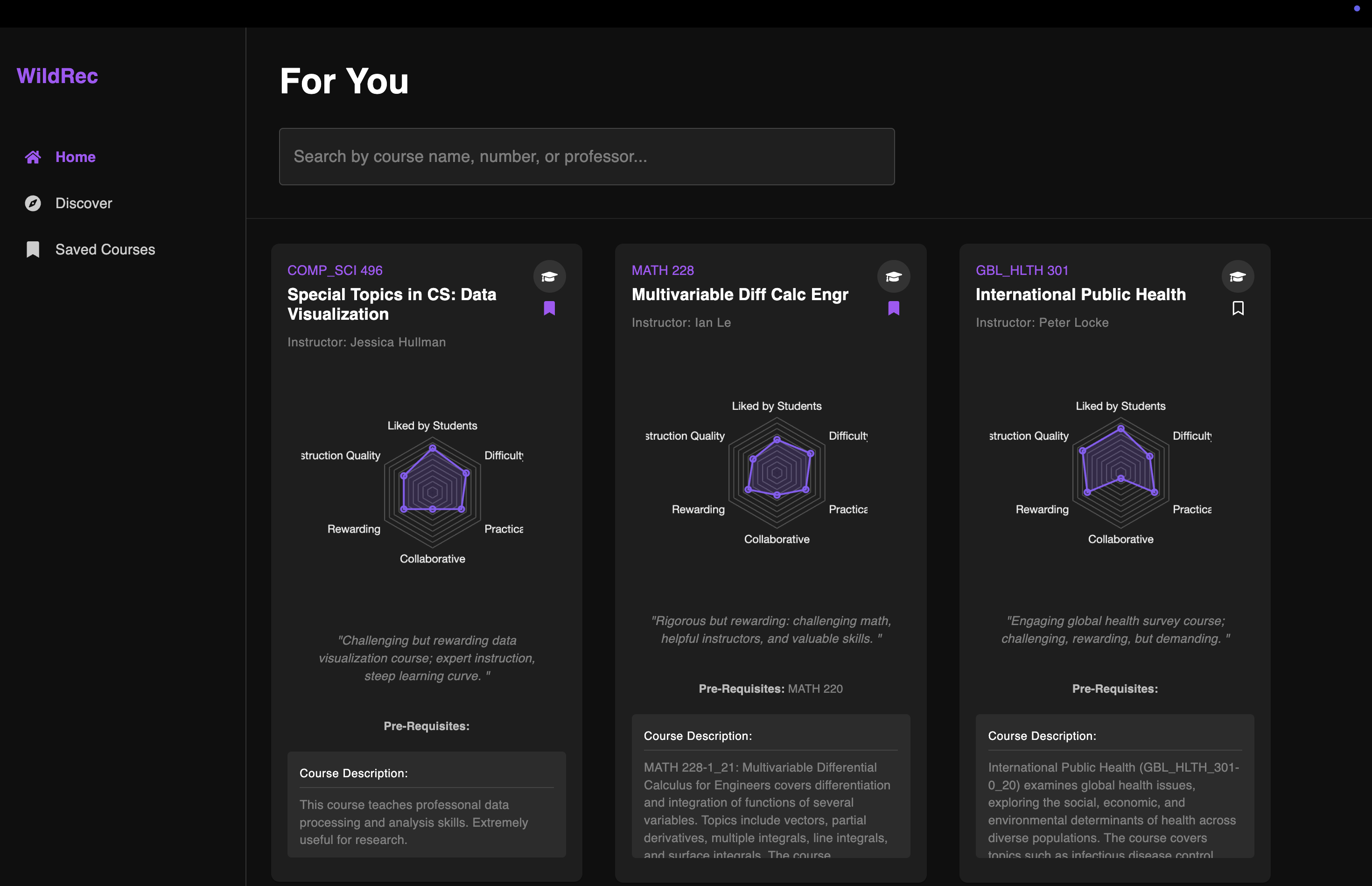
Home Page
-
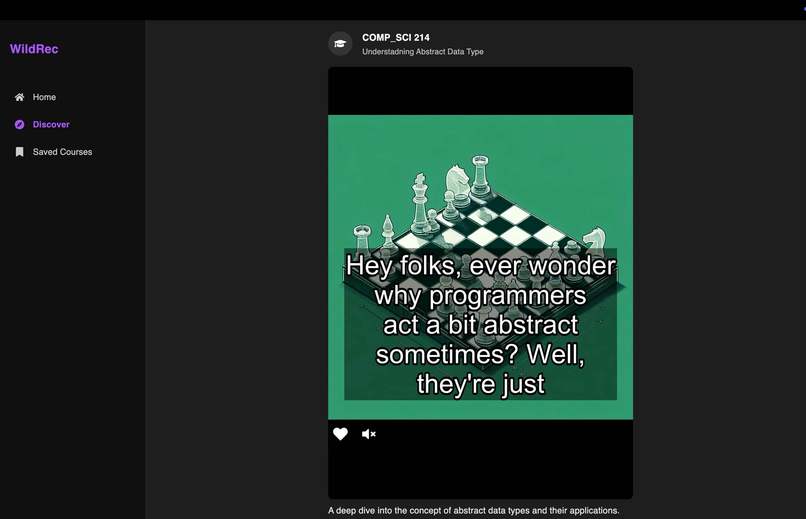
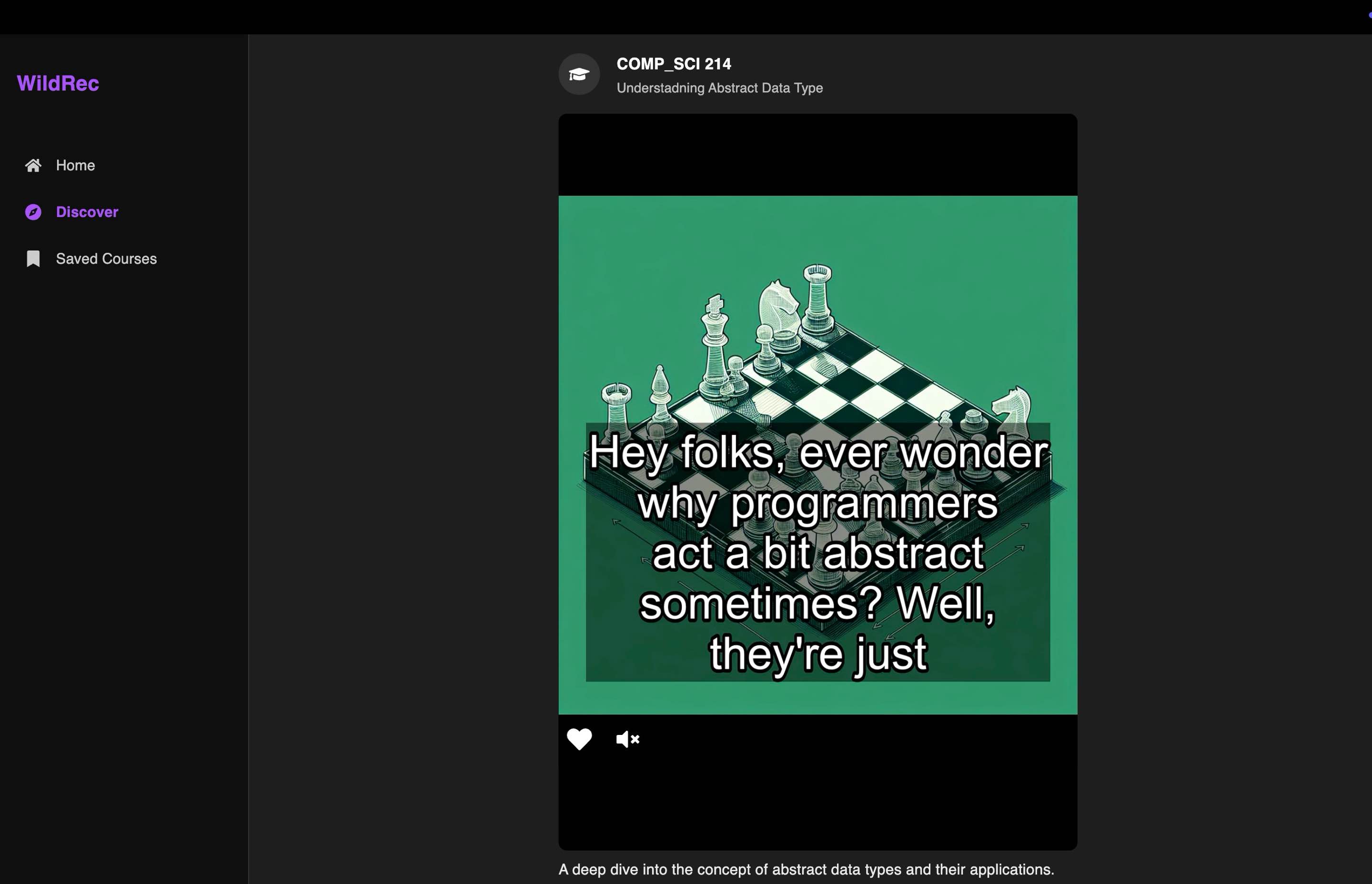
Discover Page
-
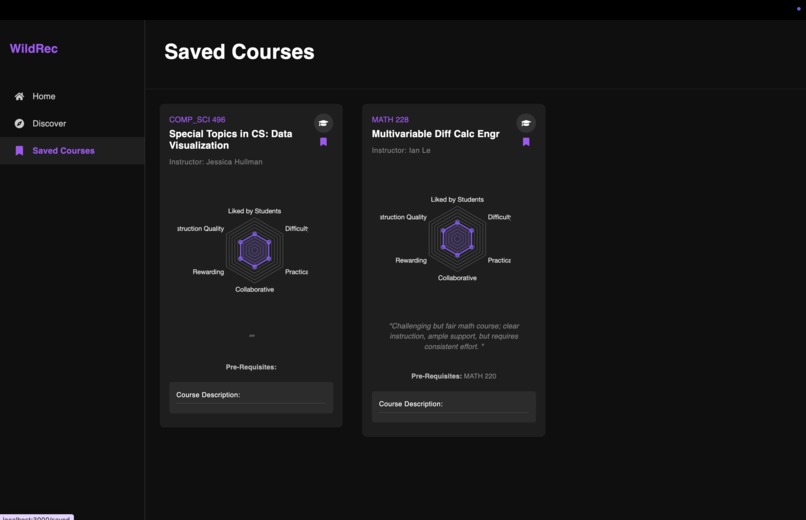
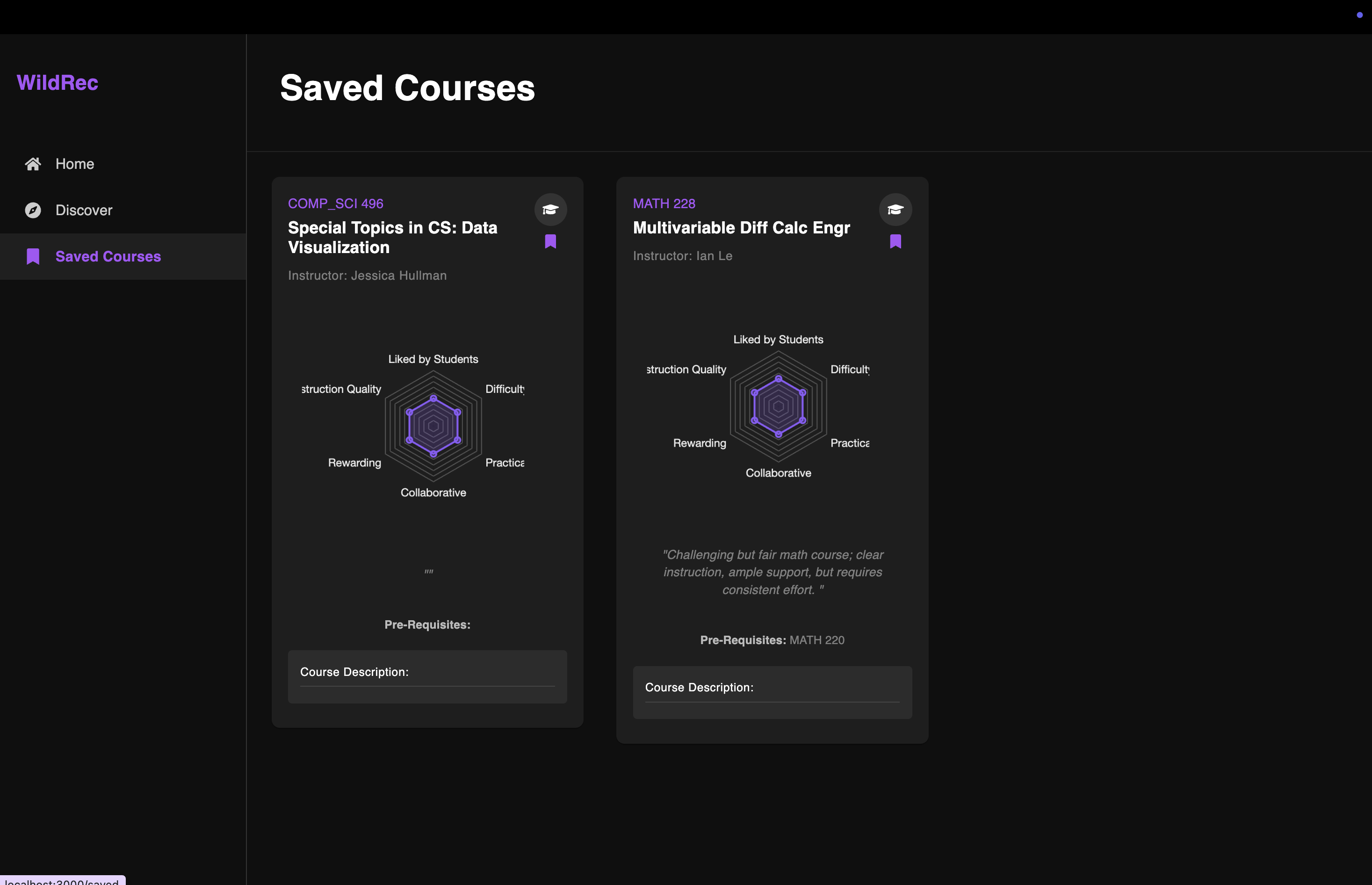
Saved Courses
-
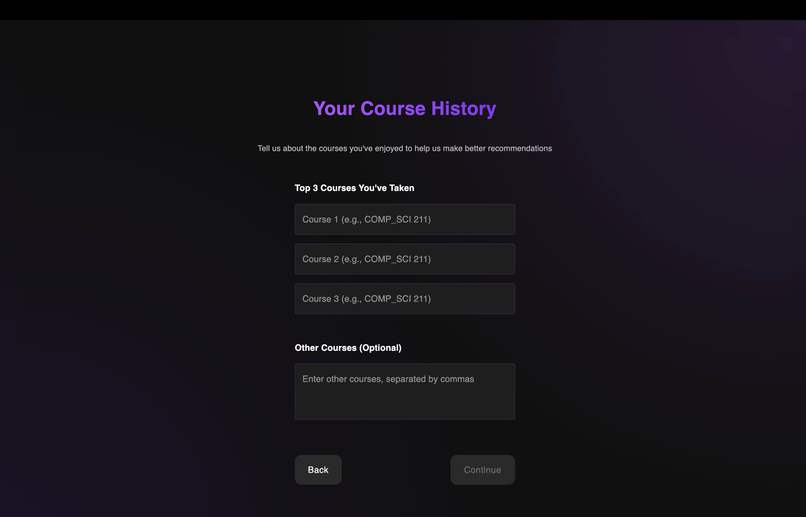
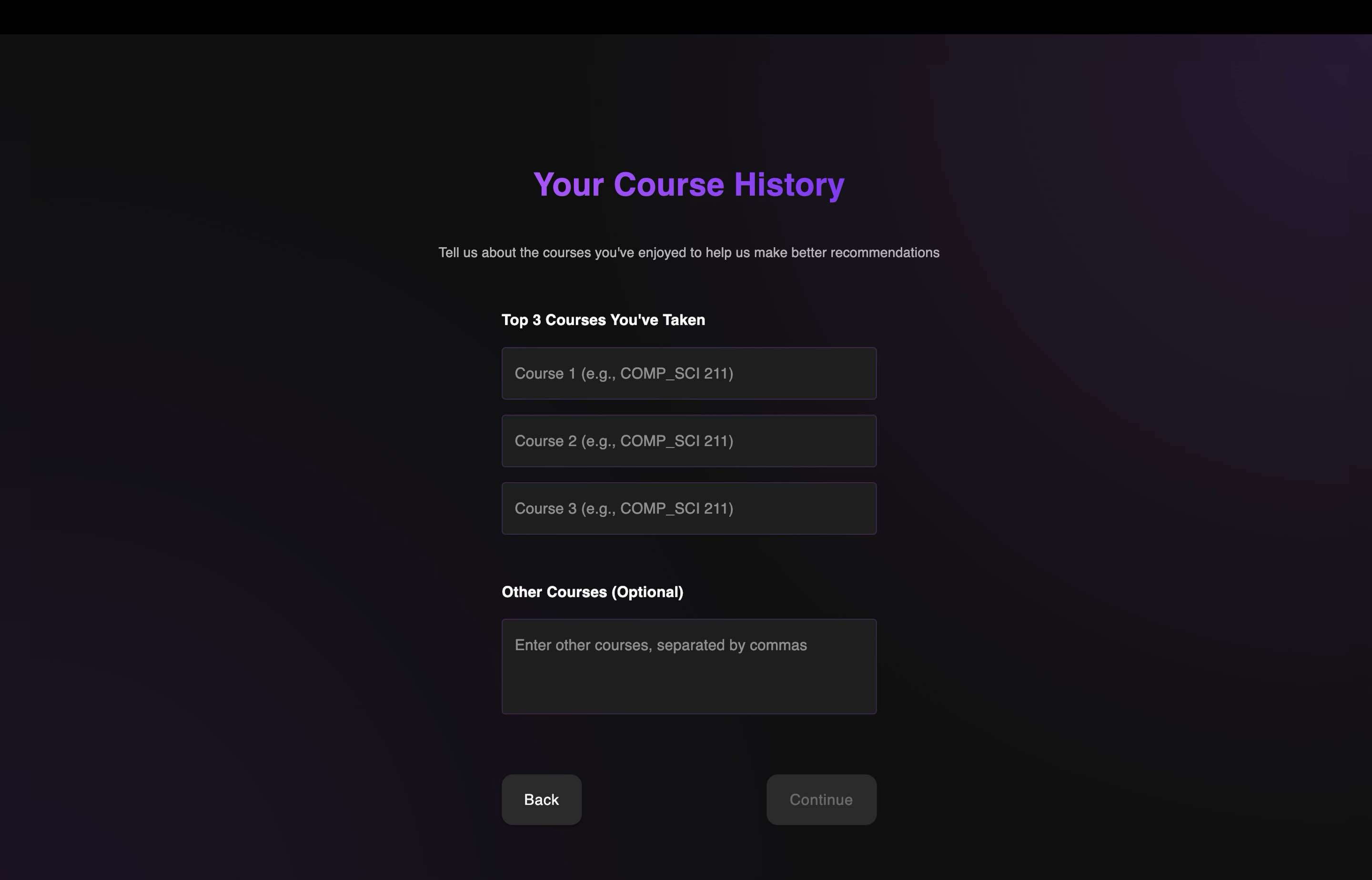
Onboarding Form 1
-
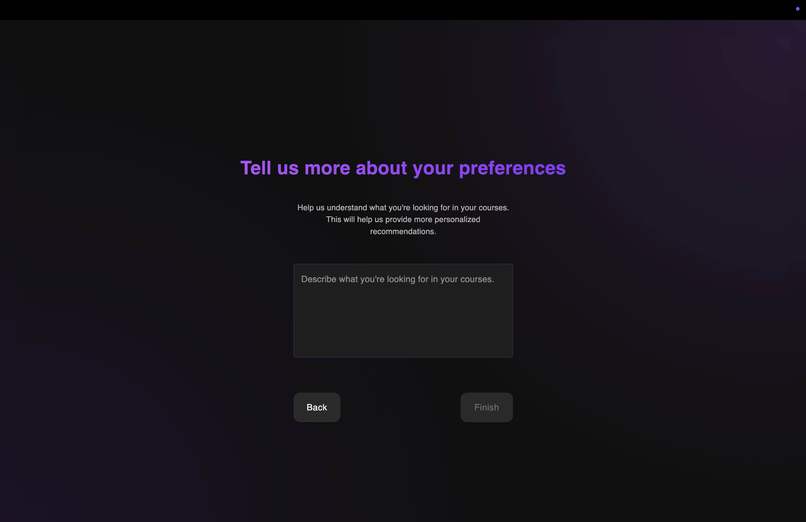
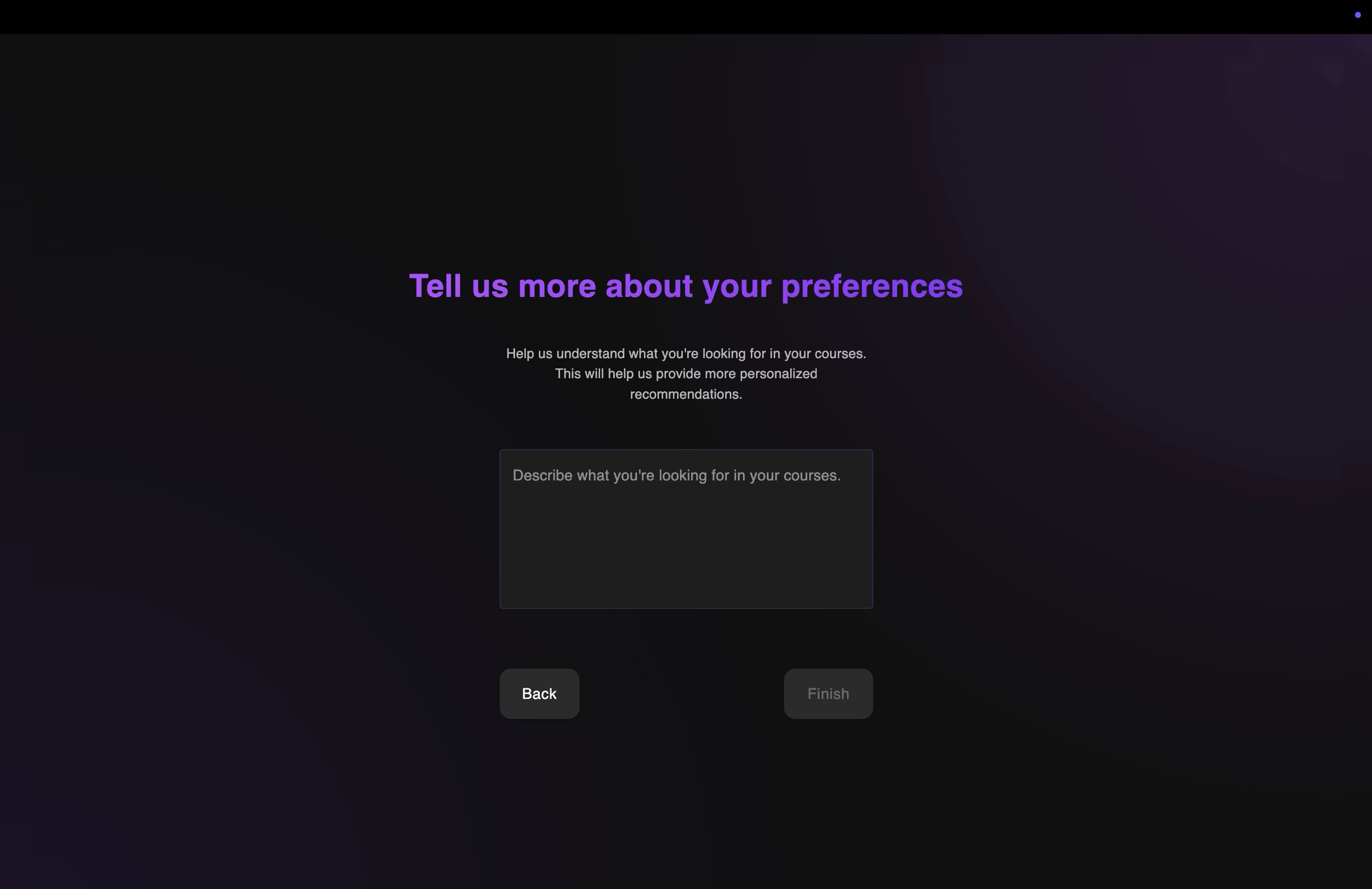
Onboarding Form 2
-

Algo


About the Project
The Inspiration
The idea for WildRec was born out of our collective frustration with the traditional course discovery process. As students, we found ourselves repeatedly scrolling through half-written course catalogs, archaic CTECs, and feeling deeply uncertain about what classes would truly engage us. We realized this wasn't just a problem of organization but of presentation—course content was locked behind barriers that made discovery feel like a chore rather than an exploration.
We asked ourselves: what if discovering new knowledge could feel as engaging as scrolling TikToks? What if academic content could be transformed into something that sparks curiosity rather than inducing decision fatigue?
Product Features
WildRec is a personalized course recommendation platform that transforms the tedious process of course selection into an intuitive, engaging experience. The platform analyzes multidimensional course attributes—course content, class experience: difficulty, practicality, collaborative nature, and instruction quality—to match you with classes that align with your unique learning style and academic goals.
The platform begins with a comprehensive onboarding process that captures your major, course history, and learning preferences. This information feeds into our hybrid recommendation system that balances your explicit preferences with content-based analysis, ensuring recommendations remain relevant while still introducing serendipitous discoveries outside your usual academic pathway.
Course profiles come alive through interactive radar charts visualizing key attributes, while the innovative "Discover" feed presents academic content in an engaging, social media-inspired interface. Perhaps most innovative is our TikTok-style content feed that breaks down complex course concepts into bite-sized, interactive videos with AI-generated visuals and natural-sounding conversational dialogue between AI speakers.
Behind the scenes, WildRec employs cutting-edge AI orchestration techniques—from autonomous deep web research that intelligently crawls academic resources to LLM-powered script generation that transforms dense academic material into engaging conversational formats. Our multimedia assembly process combines Perplexity Sonar web search with OpenAI GPT-4o for script generation, ElevenLabs voice synthesis with DALL-E visuals, creating educational content that maintains academic rigor while significantly enhancing engagement.
What We Learned
Building WildRec pushed us to pioneer advanced AI orchestration techniques at the intersection of multiple cutting-edge technologies. We developed a sophisticated agentic workflow that transformed how educational content is discovered and consumed. Our system begins with autonomous deep web research that intelligently crawls through academic web resources, extracting relevant concepts and examples that traditional search methods often miss. This research feeds into our custom LLM scripting pipeline, which we engineered to transform complex academic material into engaging, conversational multi-speaker formats.
The multi-modal generation process presented fascinating technical challenges—we learned to apply ElevenLabs voice synthesis to create natural-sounding discussions between AI speakers, creating podcast style short form videos. Simultaneously, we developed precise automated prompting techniques for DALL-E that generate contextually relevant imagery timed perfectly with key concepts in the audio. Perhaps most challenging was creating the automation layer that seamlessly orchestrates these components—synchronizing subtitle generation, managing parallel processing of thousands of content pieces, and implementing quality assurance checkpoints throughout the pipeline. This end-to-end system is a reimagining of how knowledge can be packaged and presented for discovery.
How We Built It
We structured our development around two key technical pillars: the content generation agent workflow and the recommendation system.
For the agent workflow, we began by developing a content extraction system using BeautifulSoup and Selenium to gather course materials, syllabi, and related resources. We then created a processing pipeline that uses Perplexity Sonar for deep research on each topic, extracting key concepts, examples, and perspectives that might not be immediately apparent from the course descriptions alone.
These enriched materials are then fed into our LLM-powered script generation system, which transforms academic content into multiple conversational, multi-speaker podcast video scripts. We carefully engineered our prompts to maintain educational accuracy while improving engagement through narrative techniques and dialogue.
The multimedia assembly process follows next: ElevenLabs API generates natural-sounding voices with varied speaking styles, while DALL-E creates relevant visuals that complement the audio content. Our custom orchestration system then combines these elements, adds subtitles, and produces the final video outputs.
The recommendation system was perhaps even more challenging. We implemented a hybrid approach that balances explicit user preferences with content-based analysis. Our multi-threaded content recall system ensures diversity in recommendations while still maintaining relevance, using a combination of collaborative filtering techniques and content similarity metrics.
Challenges We Faced
Our journey wasn't without significant hurdles. Initially, we struggled with processing large amounts of unstructured data for AI content generation—early versions either oversimplified complex topics or maintained academic density at the expense of engagement. Finding the right balance required numerous iterations of our prompting strategies and the development of specialized post-processing systems that could verify factual accuracy while preserving the engaging tone.
The recommendation system presented its own challenges. Traditional content-based approaches often created "filter bubbles" that limited discovery, while purely exploration-focused systems sacrificed relevance. We had to develop sophisticated algorithms that could introduce serendipity without straying too far from user interests, eventually implementing a dynamic weighting system that adjusts the balance between familiarity and novelty based on user engagement patterns.
Technical integration between our various AI components also proved challenging. Synchronizing voice generation with visual elements required precise timing mechanisms, and ensuring consistent quality across thousands of generated pieces of content demanded robust quality assurance systems and fallback mechanisms when certain components underperformed.
Perhaps most fundamentally, we faced the challenge of reimagining how educational content discovery should work in the first place. Breaking free from traditional paradigms meant constantly questioning our assumptions about how people learn and discover new interests—a process that continues to guide our development as we refine and expand WildRec's capabilities.
Through each challenge, we remained committed to our vision: transforming the tedious process of knowledge discovery into a joyful, serendipitous exploration that expands horizons rather than narrowing them.
Built With
- beautiful-soup
- claude
- dalle
- elevenlabs
- flask
- gemini
- javascript
- next.js
- node.js
- openai
- perplexity
- postgresql
- python
- react
- selenium


Log in or sign up for Devpost to join the conversation.