-
-
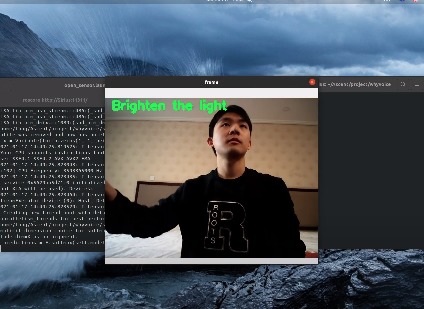
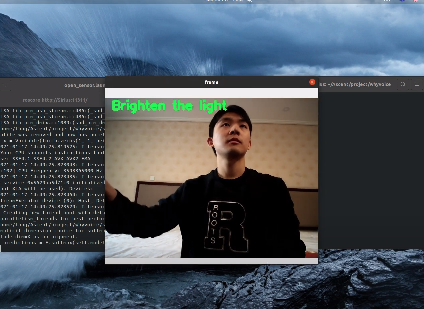
Swipe to the right to turn up the brightness of a light
-
The keyword spotting system is trying to spot my prerecorded command (knocking the desk with a rhythm)
Inspiration
Smart assistants, such as Google Assistant, Siri, and Alexa, have been deeply integrated into our lives. With one simple command, people can wake up their smart assistant and ask them to do them a favor ranging from setting up a timer to turning on the light. However, built on voice commands, current smart assistants do have some limitations. One of them is that mute people cannot use smart assistants unless by manually opening the app and type the command. When it's not very convenient to speak, communicating with a smart assistant is also not a very good experience. That's why we built whyVoice, an idea of using smart assistants without the need to say anything.
What it does
Our system is expected to recognize a key rhythm (such as the sound of knocking the desk with a specific rhythm), record the hand gesture movement using its camera, and output the classification of the hand gesture video (such as turn on the light). The whole experience does not need the user to speak a word.
How we built it
We target the mentioned problem by making the input command voiceless. In keyword spotting (KWS), the technology of detecting a keyword in a continuous speech such as "ok google", we replace the wake-up phrase with an easy-to-remember beat: the sound of knocking on the desk with a rhythm “do----dodo--do”. In the second part, we replace speech recognition with hand gesture recognition (HGR), where each hand gesture represents a pre-defined command like “turn on the light” or “call daughter”. Our solution is built on artificial neural networks. For KWS, we recorded the necessary dataset (the beat, background / silent, random talking), extracted MFCC features from the audio clips, and feed them into a light-weight neural network. For HGR, we use a 3D convolutional neural network that takes in sequential hand gesture images. The two trained models are deployed on a Ubuntu 20.04 ROS Noetic system that is connected to a USB camera with a microphone. ROS nodes are developed so that the two systems can communicate with each other. The hand gesture recognition node subscribes to the topics the keyword spotting node publishes in order to turn on the camera and predict what the hand gesture is once the rhythm is detected.
Challenges we ran into
- dataset recording. We need to record the keyword spotting dataset by ourselves because the dataset of the sound of knocking on a desk isn't very popular so far.
- Tuning the model. We had a difficult time making the keyword spotting model not misclassify silent as the rhythm. This was caused by our recorded dataset and specific model parameters.
- ROS integration: Letting two systems talk to each other is hard. For instance, when the beat is given as an input, the keyword spotting system can constantly output positive results because of the sliding audio window over a small shift (10ms). How the hand gesture recognition system handles this repetitive positive feedback took us some time.
Accomplishments that we're proud of
We did it! It is a system that's exactly what we thought the workflow should be. The two systems communicate with each other seamlessly. Both models give decent performance after model tuning. Further, we kept in mind of user's privacy during our development. The camera is never turned on until the beat is detected, and will be turned off once the hand gesture is detected. We are proud that we stand at a user's perspective regarding privacy concerns during our system design.
What we learned
We have learned a lot from model tuning, ROS debugging, audio processing, and so much more!
What's next for whyVoice
- Flexible customization: So far some configuration is hardcoded (model parameter, the beat for keyword spotting, which command is defined for which hand gesture, etc). We want to give users a better experience to train their own "beat detector" and "hand gesture detector" to personalize this system.
- Integration to the available smart assistants: We have the back end that supports key-rhythm spotting and hand gesture recognition, but we have not integrated it to any smart assistant hardware or use their APIs. We will keep exploring the possibility of adding our features to the current smart assistant services.
- Model tuning: these two models still have room for improvement in terms of stability. We will keep tuning the models for optimal performance through parameter tuning and dataset expansion.




Log in or sign up for Devpost to join the conversation.