Inspiration
This project was inspired by the experience of a first-time parent on our team. During long nights, repeated baby cries often lead to guesswork and rising anxiety. We wanted a calm, explainable assistant that helps parents decide what to try next, without medical diagnosis.
What it does
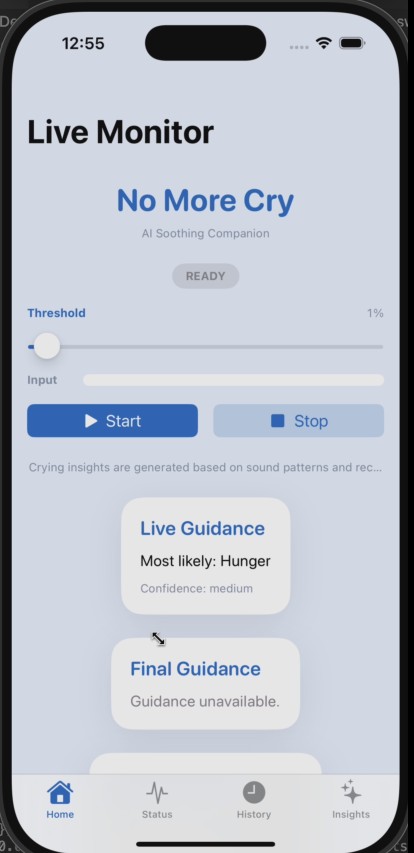
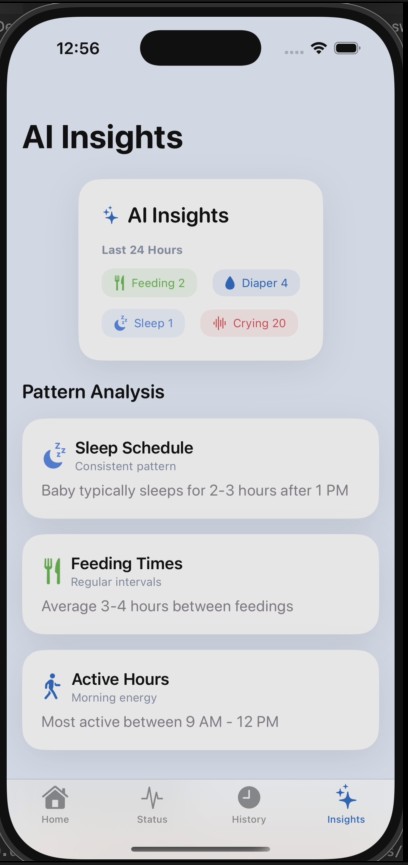
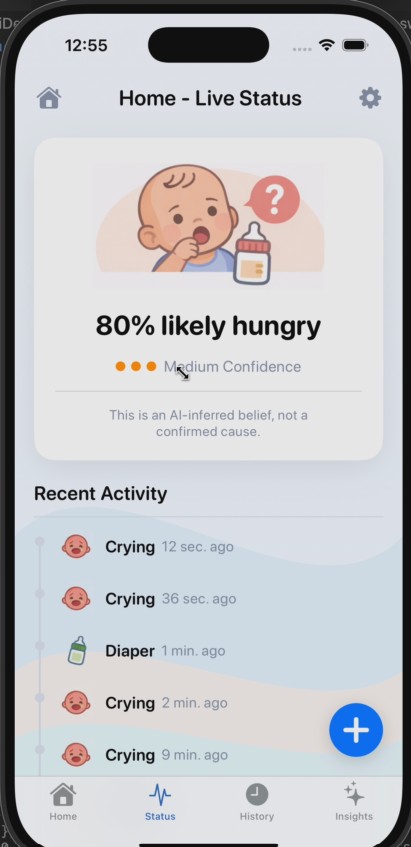
WhyMyBabyCries combines baby cry audio with recent care history to infer the most likely cause of crying and recommend the next best action. It provides:
Cry transcription and cause probabilities Clear, confidence-aware next-step guidance Low-latency hints during live recording Continuous personalization via context memory
How we built it
We use Gemini 3 as the central multimodal reasoning engine. Each crying event sends Gemini 3 a combined payload: crying audio plus structured care context (feeding, diaper, sleep, and feedback). Gemini 3 returns strict JSON with:
audio_analysis (transcription + probabilities) ai_guidance (cause, alternatives, actions, notice)
Live audio is streamed in chunks with partial reasoning for early hints. Context memory is fed into future requests, allowing Gemini 3 to act as a continuously adapting caregiver assistant rather than a stateless classifier.
Challenges we ran into
We balanced multiple input signals without over-weighting any single modality. Streaming partial reasoning required careful prompts to avoid premature or overconfident guidance.
What we learned
Gemini 3 excels at reasoning with context under uncertainty. Explicitly surfacing confidence and alternatives significantly improves trust in sensitive scenarios.
What's next
We plan to explore optional video-based context and parent-provided comfort audio as additional non-diagnostic signals. Future work will continue to prioritize privacy, transparency, and responsible AI use.


Log in or sign up for Devpost to join the conversation.