-
-

Banner
-

Choose participants
-
Battle Preparation
-

Intro
-

Battle simulation
-
Result
-
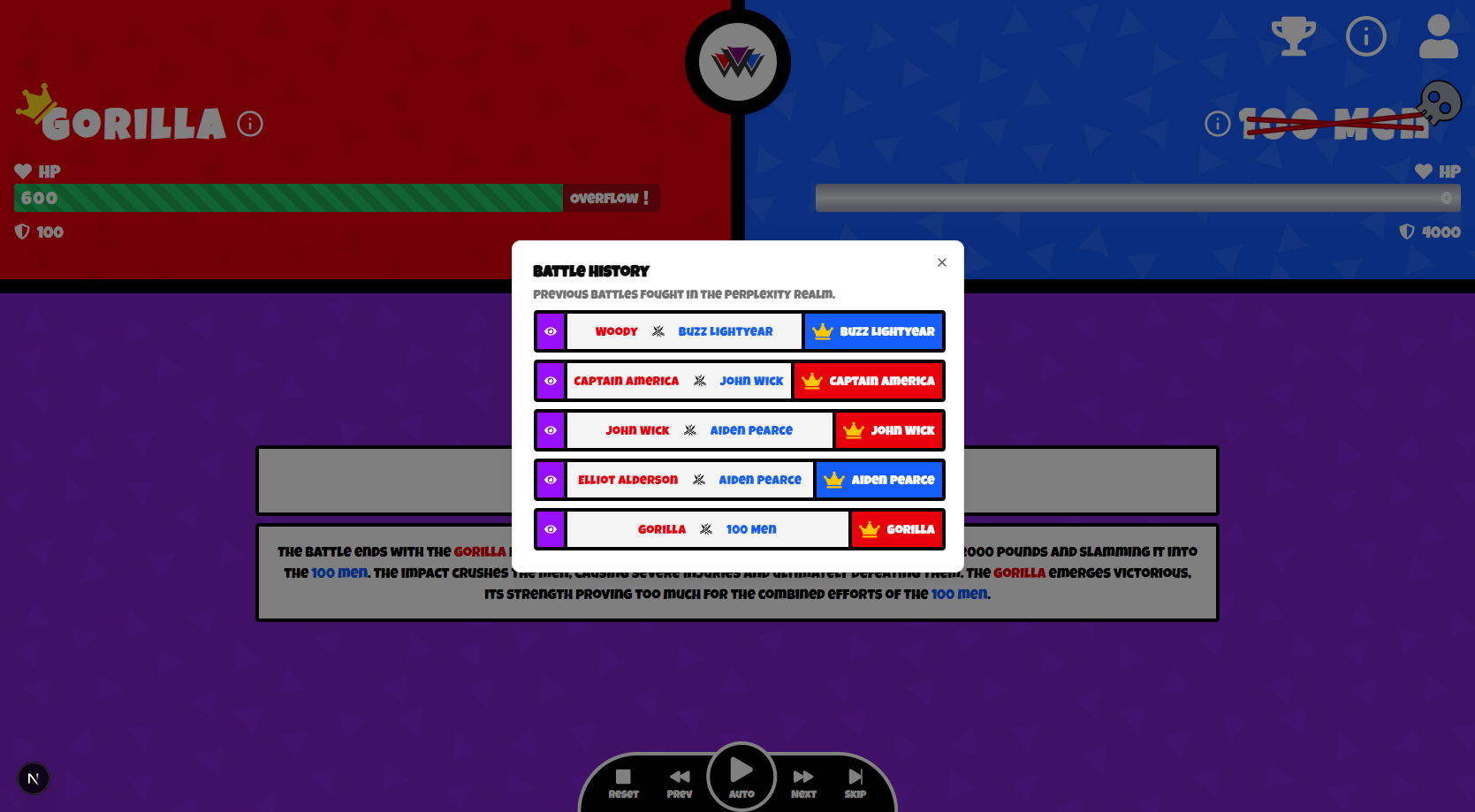
Battle History





Inspiration
If I have to be honest, the only reason I even came up with the idea for this project was the whole Gorilla vs. 100 men debate that blew up over and Twitter/X. Pure and simple.
After reading through the Sonar API's documentation, I became more intrigued. Sonar gives results based on grounded searches and cites real sources. I thought this was perfect for what I had in mind.
First, I played around on perplexity.ai/ and the playground. I receiv4d very promising results without spending any credits.
Then I went ahead and bought real credits so I could use it for on my app.
What it does
Basically, you put two names: one in the red corner; one in the blue corner. Then, using Sonar, we simulate a battle scientifically and determine a winner.
Because of Sonar's research/search capabilities, I made sure that battle calculations are grounded and scientific. And I don't mean nerfing an OP character into realistic standards. I mean calculate what their OP-ness would be by real metrics. If a character can destroy a planet, as unrealistic as that is, Sonar calculates all the metrics like firepower and force!
Here is the app workflow:
Getting Started

Login/Register

Enter Participants

Calculating

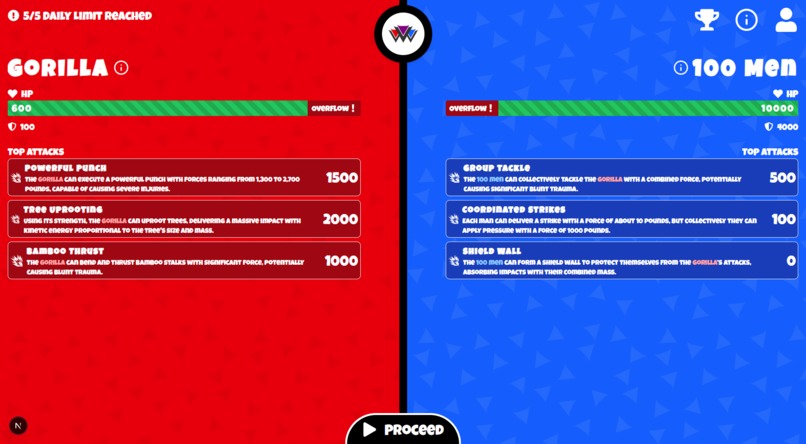
Preparation Stage It should be noted that I've asked Sonar to calibrate
HP,defense, andattacksbased on humans. Where they would have the following stats:
From all the battles I've generated, Sonar has calibrated it pretty well.

You can click the more info button (i) to display extra info generated by Sonar.

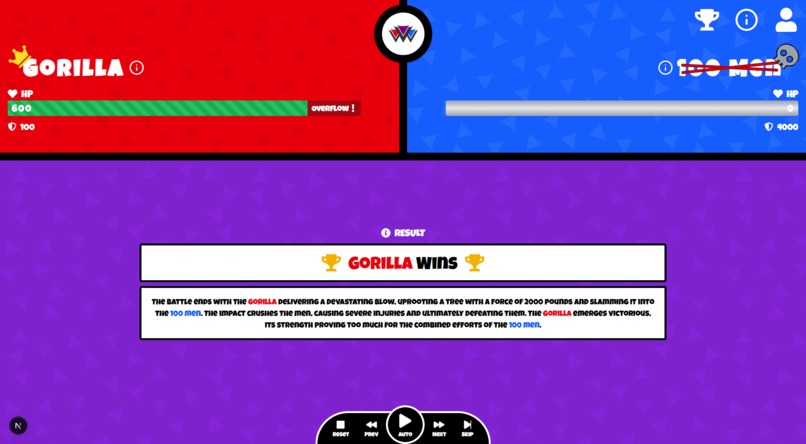
- Playing Out a Battle
To play out a battle, you have many controls. You can click on Next and Previous. You can skip to the end result. Or you can reset.
Most importantly, you can let it auto-play to immerse yourself into the battle.



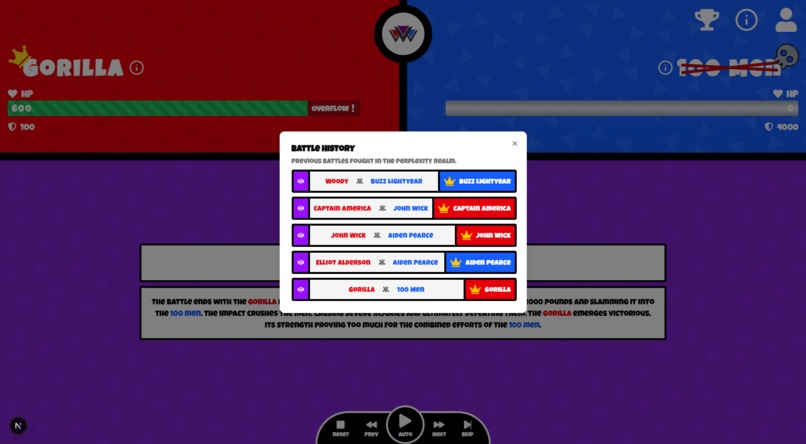
- Battle History
You can view the battles other people have simulated.

How we built it
I've built this using Next.js to quickly get a secure environment to call the chat completion API. Then I simply hit the chat/completion endpoint of the Sonar API to generate the battle simulation.
I tried every model available, including deep research. All models yielded very good results. And I've found that even the sonar model does a great job simulating a battle scientifically.
Challenges we ran into
No unique challenges really. Just the typical formatting issues you run into when using LLMs. Generating the perfect prompt, though, definitely took a while.
Accomplishments that we're proud of
Not necessarily MY accomplishments. But there are some aspects of my prompt and the content it generates that I'd like to highlight:
- Wrapping names with color tags:
I asked Sonar to wrap any references to the participants with their respective color (
<red>name</red>or<blue>name</blue>). And it does a really great and thorough job. Even nicknames and pronouns are wrapped without fail. - I also ask Sonar to make sure that there's always a winner, meaning one participant will end up at 0 hp. It's definitely not as consistent as the color wrapping, as there are some rare hiccups-- but it's consistent enough.
What we learned
I learned that prompts aren't that expensive really. I've managed to create a pretty good prompt for my main functionality. And it costs around ~0.01.
What's next for Who Would Win
I'd like to add more features. Maybe allow users to describe the participants more. And, as good as it is now, there's always room for improvement for the prompt I used.
Built With
- appwrite
- nextjs
- perplexity
- react
- sonar
- tailwindcss

Log in or sign up for Devpost to join the conversation.