-
-
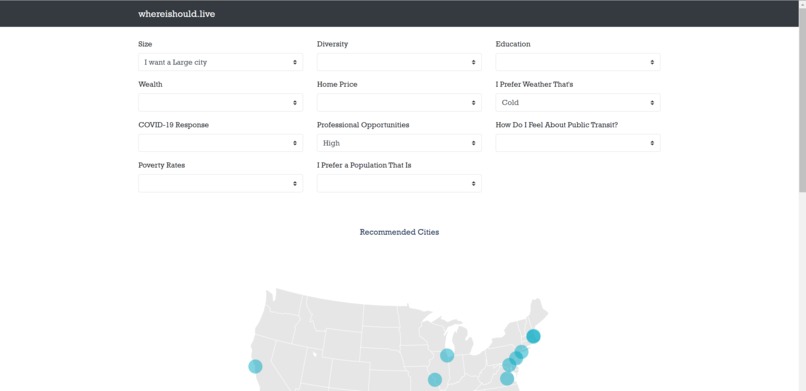
Users can submit their preferences using each of the dropdowns.
-
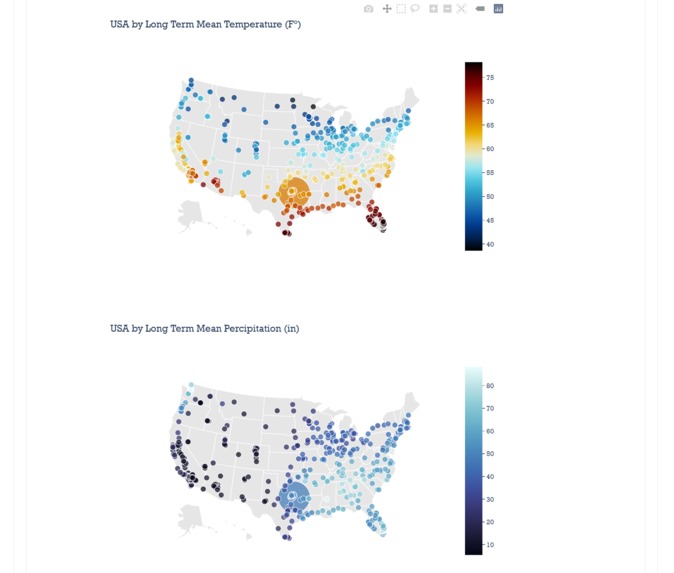
We're able to use data viz parameters inspect the city you're looking at. Interactive!
-
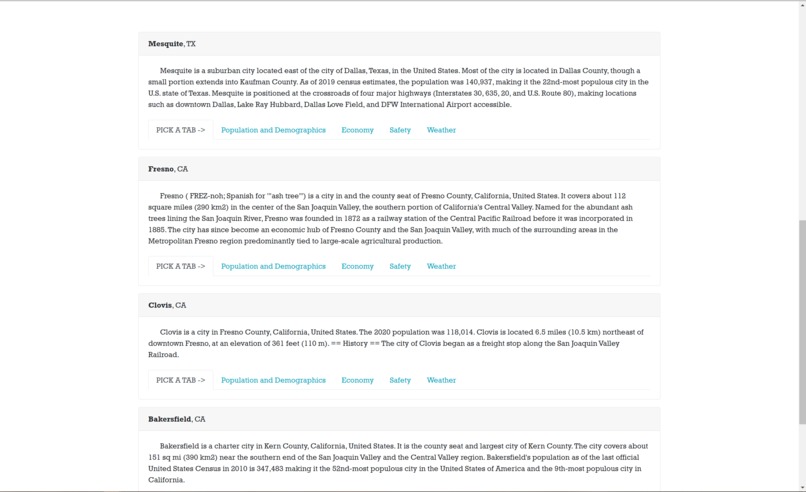
Below the map, cities are displayed with cards that give more info on each city!
-
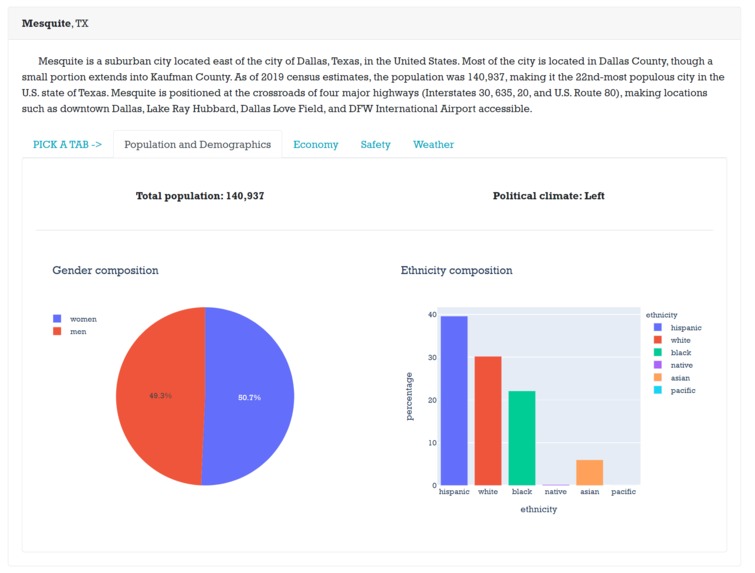
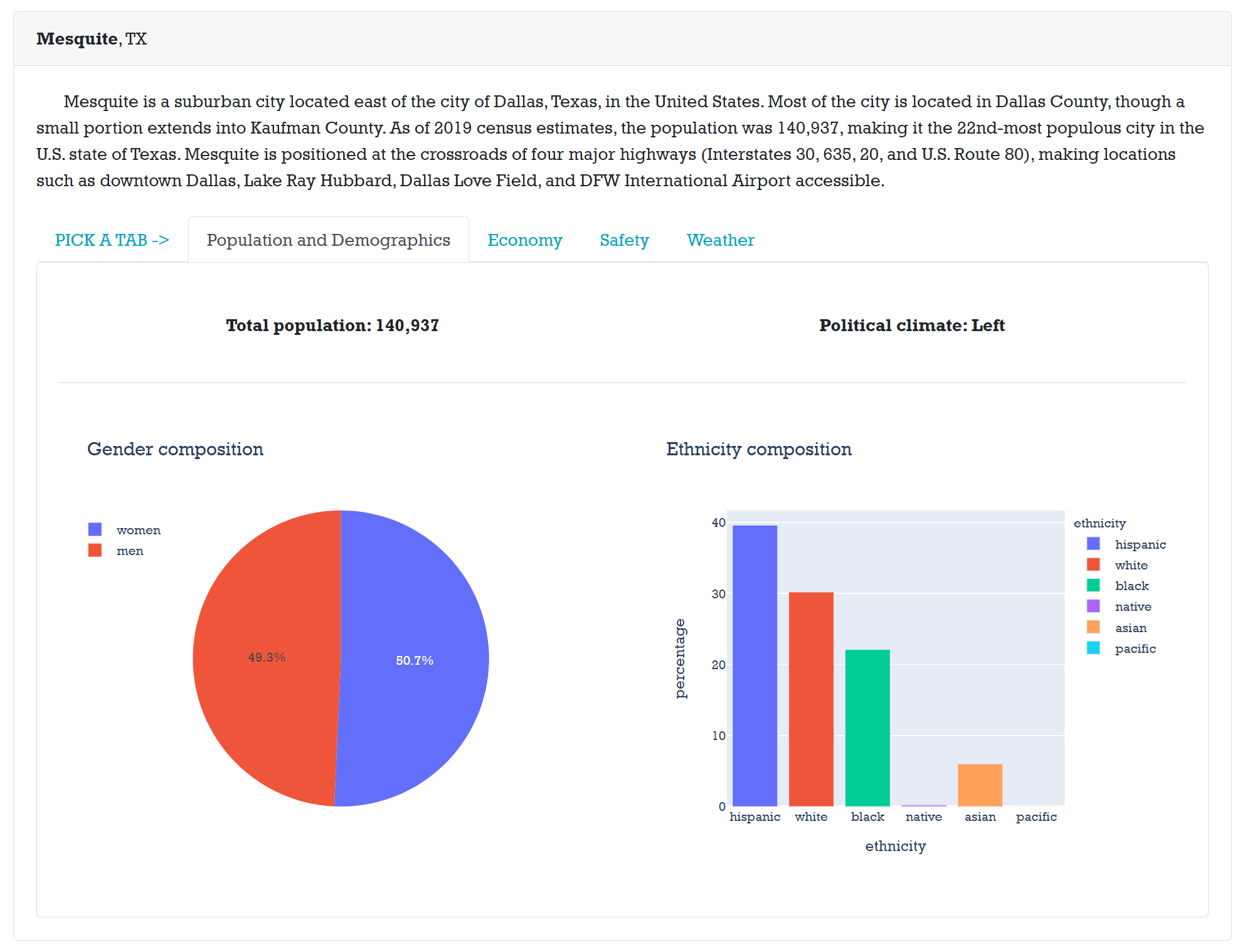
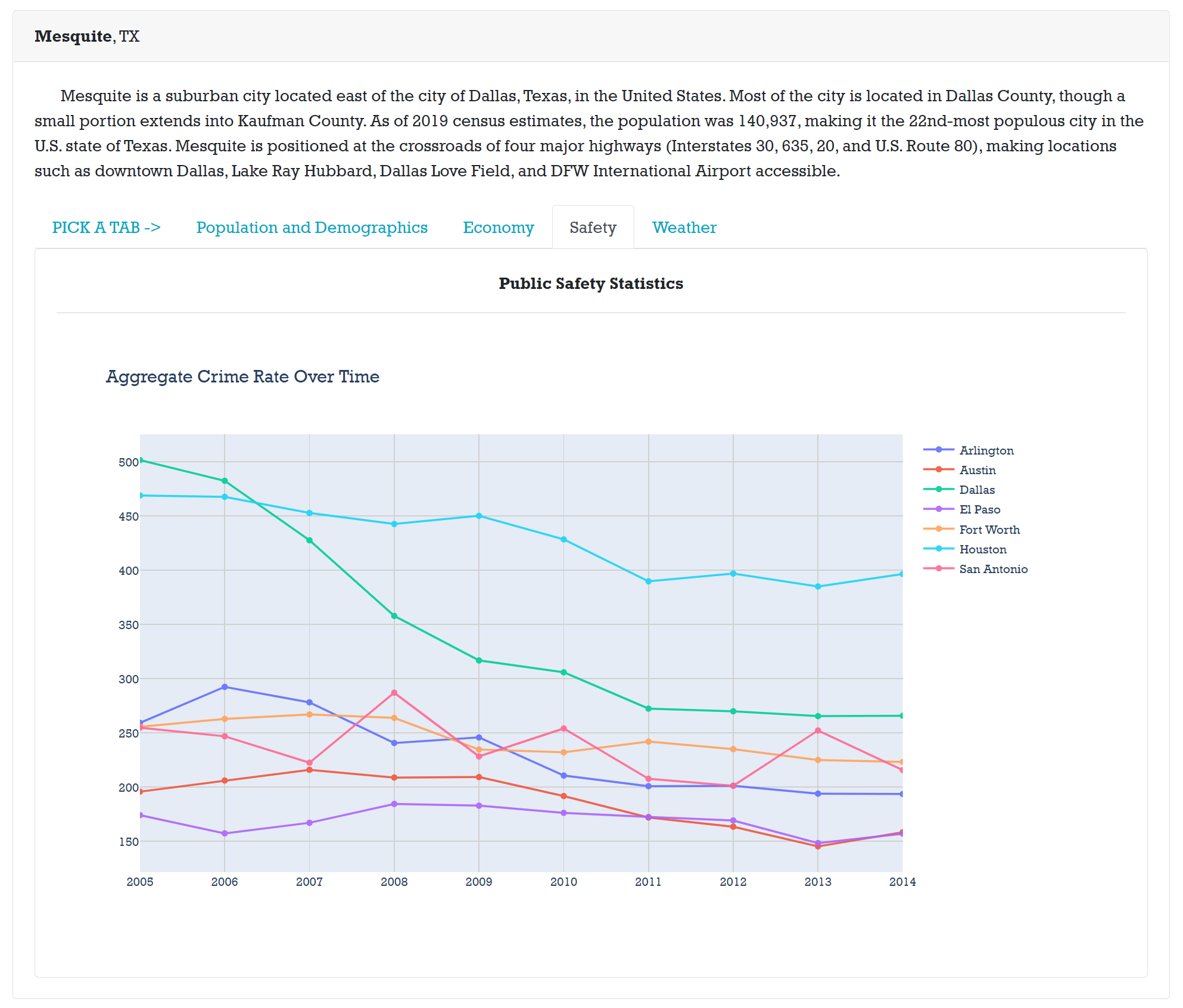
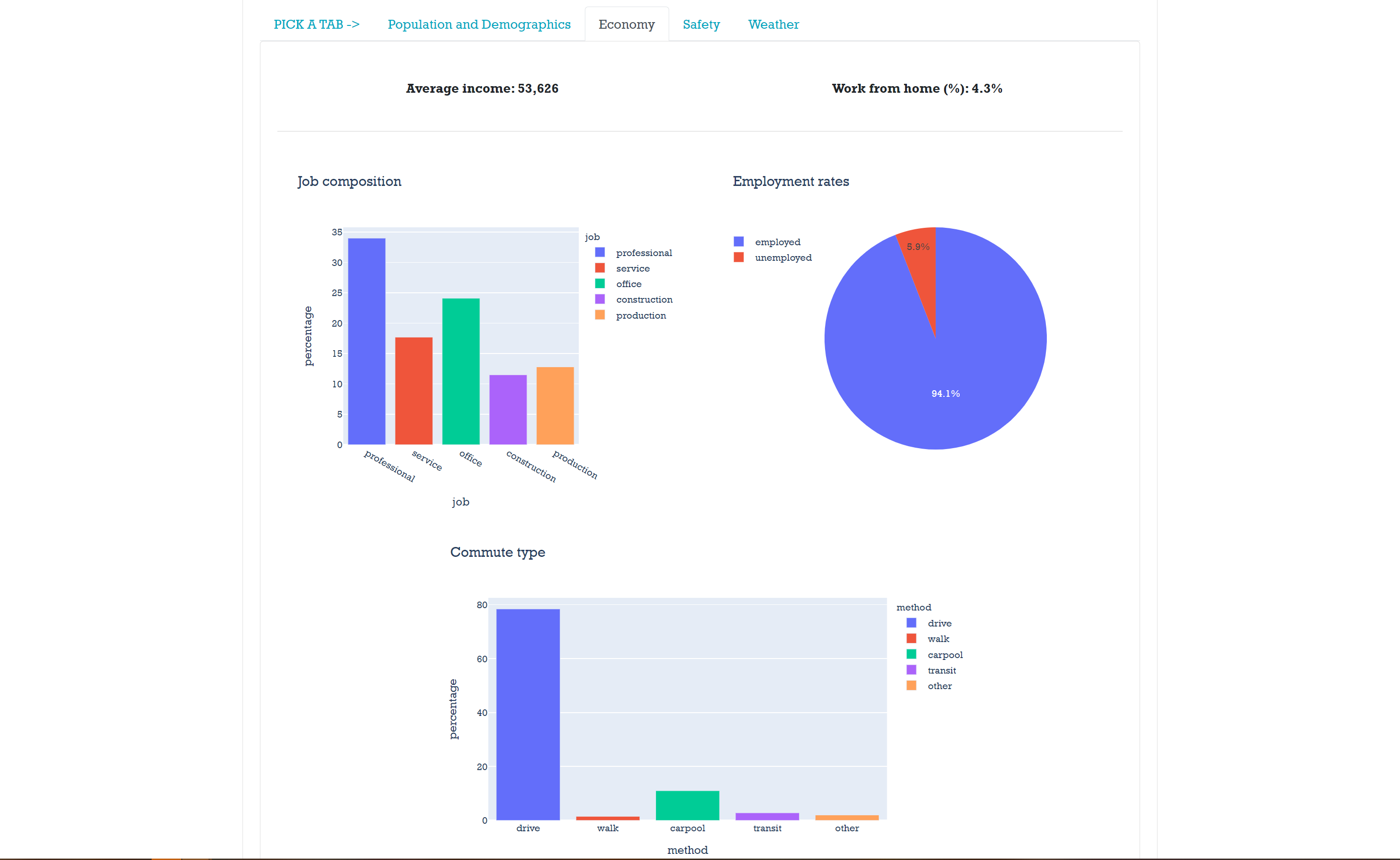
Each tab has information for specific characteristics of data.
-
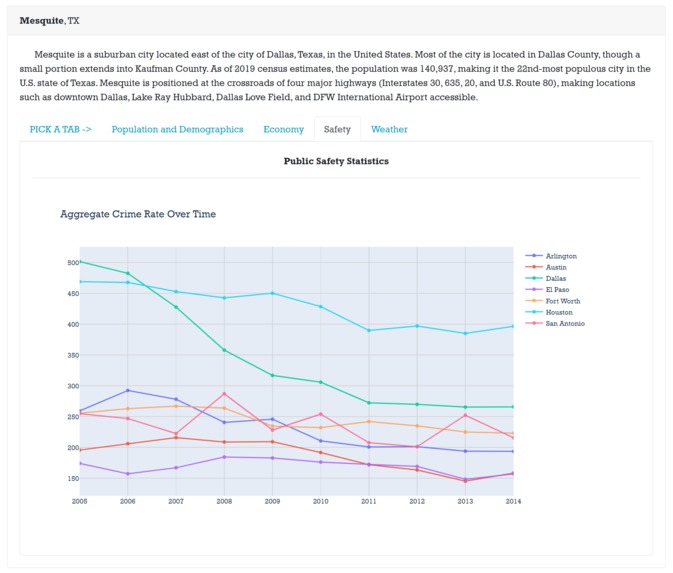
Some tabs have comparisons between the selected city others in that State.
-
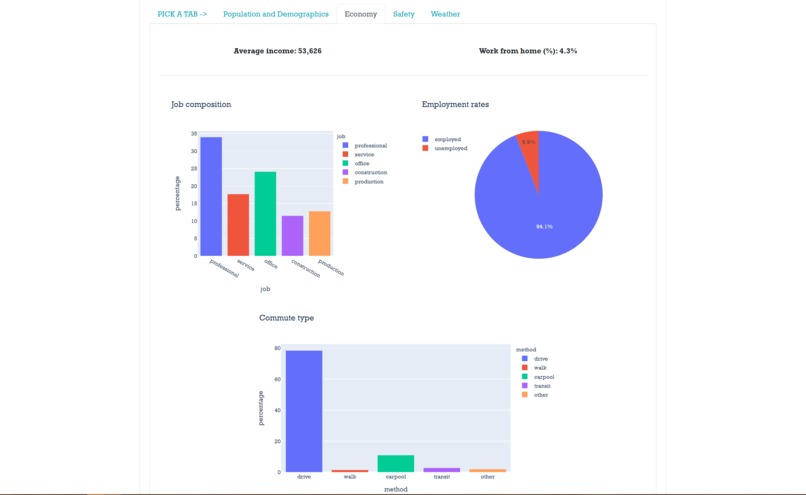
Other tabs have information about the city itself.
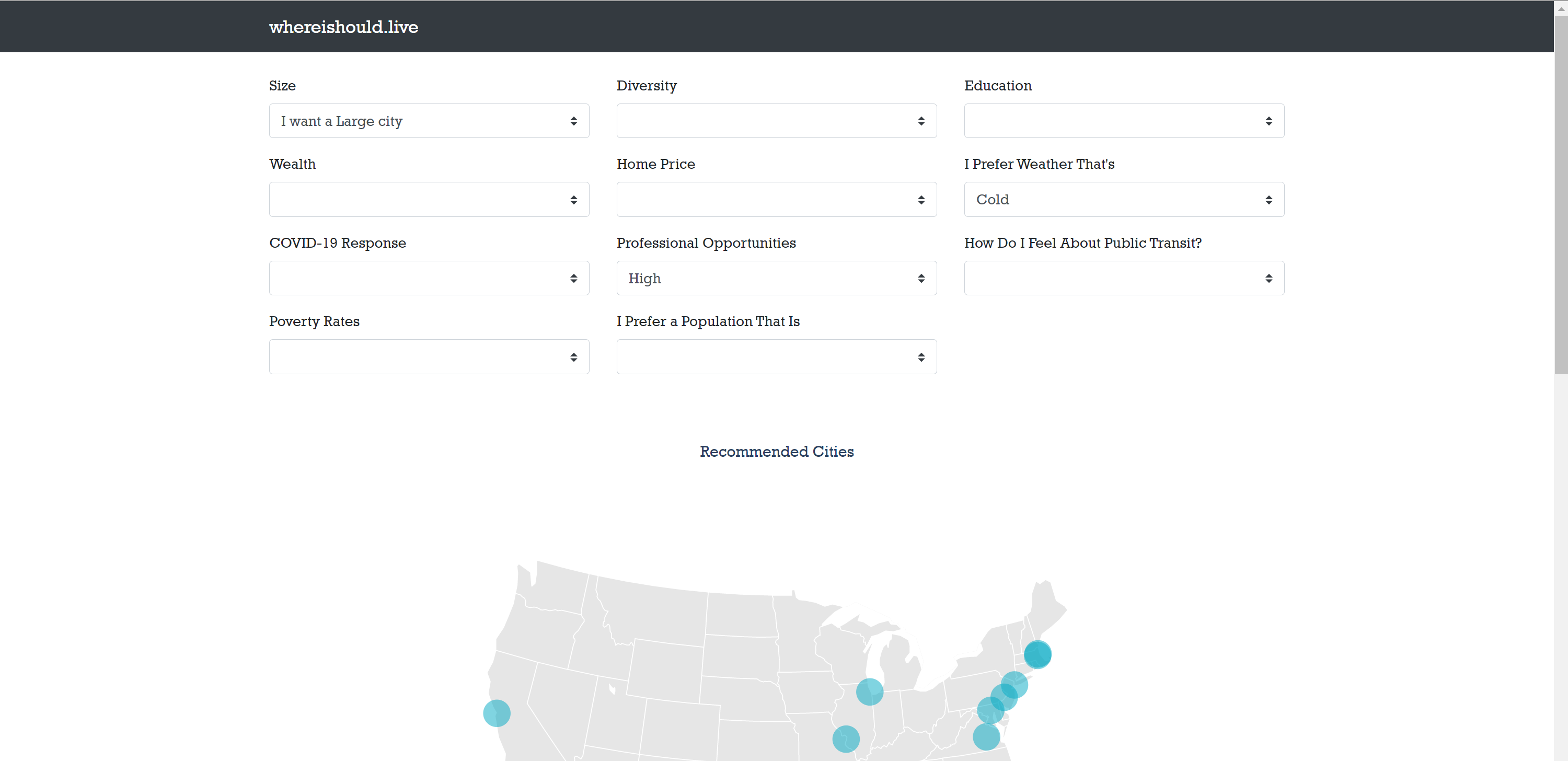
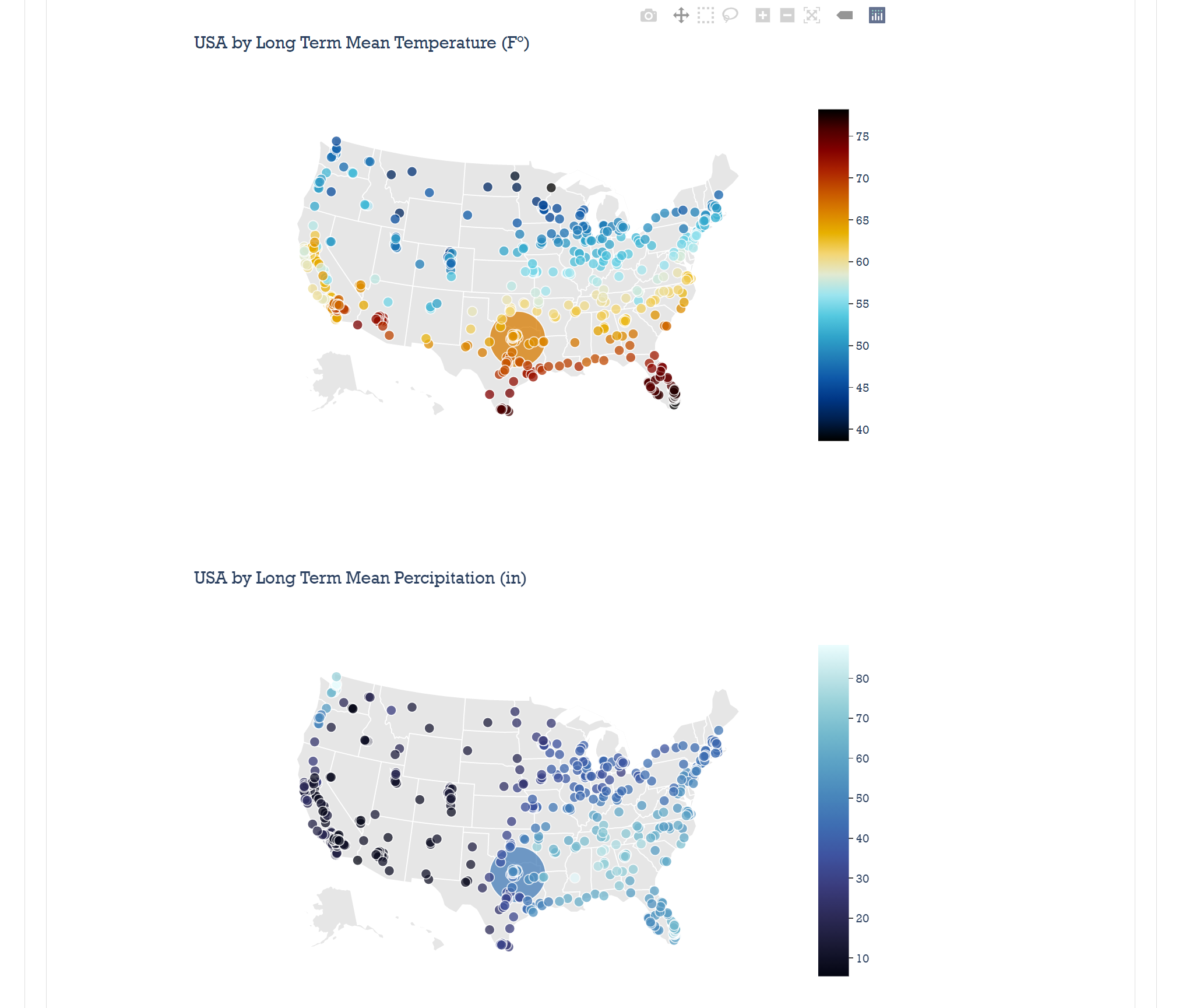
Inspiration
We were inspired by the rankings in the starter notebook of the challenge, but we wanted to go further. From the beginning, we decided to make a tool that would allow users to select the qualities that are the most important to them in selecting a city, and we wanted to include as much data on those cities as possible so our users could make their choices with the most information possible. We know that not everyone has the same preferences for what they're looking for in their optimum city, so we employed a clustering algorithm to recommend users relevant cities based on their preferences. We also knew we wanted to host an amazingly awesome webtool with an easy to remember domain name (purchased from Domain.com) where users could input their priorities and find multiple cities matching their criteria, and SO MUCH MORE!
What it does
We combined, census, weather, voting, economic, crime, weather and MORE data to provide users with the most robust data on all U.S cities with populations greater than 50,000 people, presented to the user in an easy to read format.
A user of our service would go to our website and from there they'd use our simple interface and select their priorities in a city. Our written-from-scratch clustering algorithm determines the cities that best match their preferences.
Finally, each city is presented with maps, charts, and rankings so the user knows how their city sits in the categories they selected.
How we built it
Data Aggregation - We synthesized a total of 8 datasets with the goal of generating a relevant subset of variables to consider when city shopping. We ended up generating a master dataset with 701 cities each with 59 attributes!
Clustering - Based on user preferences, we wanted to be able to recommend cities with your desired characteristics. At first glance it might make sense to just recommend cities whose attributes fall within some interval. For example, I could say I want to live in a city that has $70k income per capita and is very cold. From the get go, I am already limiting myself to cities that strictly meet these two characteristics! How can we move from limited search results to a richer collection of cities to suggest? The answer is K-Means! With the K-Means algorithm, we are able identify each city uniquely as a high dimensional vector (59-dim) and find clusters of cities in this richer space! These data was Z-transformed before being fed into a k-means++ clustering algorithm which gave us 100 clusters with about 5-20 cities per cluster. To determine what clusters should be used to make a user recommendation, we constructed 13 metrics using all of the data which allow us to measure more qualitative things like racial diversity and wealth. By asking the user for preferences across these 13 things with dropdown ranges, we were able to construct a feature vector for each user based on their custom preferences. We calculated the inner product between the user's input and the feature vectors for each of the centroids identified by K-Means and suggested cities within these clusters. Note that we applied K-Means on our original 59-dimensional space, and then calculated the inner product with vectors in the subspace defined by span input features with the centroids in the higher dimensional vector space.
# City population df["size_feature"] = df["city_population"]# Scaled categories (1-5) from most rural to most urban df["urban_feature"] = df["ruralurban_cc"]# Percent of population that voted democrat df['political_feature'] = df["dem_pct"]# Income per capita df["wealth_feature"] = df["income_per_cap"]# Maximum temperature over last twelve months df["weather_feature"] = df["LTM_max_temp"]# Percentage of population in private industry df["profession_feature"] = df["pct_private_work"]# Percentage of population that either walks or takes public transportation to work df["transportation_feature"] = df["pct_walk"] + df["pct_transit"]# Linear combination of adult and child poverty; child poverty is penalized more df["poverty_feature"] = df["pct_poverty"] + 2 * df["pct_child_poverty"]# Linear combination of COVID-19 cases and deaths; deaths are penalized more df["covid_feature"] = df["covid_cases_per_100k"] + 5*df["covid_deaths_per_100k"]# Probability that you select two individuals of different races (higher means more diversity) df['diversity_feature'] = 1-sum([(race_pct/100)**2 for race_pct in df['race_percentages']])# Linear combination of proportion of individuals that graduate high school and college; college is weighted more df["education_feature"] = 0.5 * df["lesscollege_pct"] + 1.0 * (100 - (df["lesscollege_pct"] + df["lesshs_pct"]))# Proxy for average home value (property tax ($) / property tax (%)) df["home_price_feature"] = df["avg_propty_tax"] / (1.11 / 100) # 1.11% = average national property tax rate# Estimated average age from proportion of individuals in 3 age groups: 0-29, 29-65, and 65+ df["age_feature"] = (15 * (df["age29andunder_pct"]/100)) + \ (47.5 * (1 - df["age29andunder_pct"]/100 - df["age65andolder_pct"]/100)) + (73 * (df["age65andolder_pct"]/100))Product - With our data and clustering algorithm in hand, we now have the tools needed in order to create an effective recommendation tool. We decided to go with the Plotly/Dash/Heroku stack in order to host our web app because of the minimal overhead to get started. These packages support rich I/O and interactive functionality allowing for an immersive user experience. All a user has to do is fill out which data fields are important to them and based on that they will be shown cities that suit them!
Challenges we ran into
Finding and processing the data was a challenge because we used many sources that didn’t always have data for the same places. We had to do some fuzzy matching between cities and counties to map county-level data to cities.
We also had some discussions around how (if at all) to preprocess the data before clustering it. Eventually, we decided to give each column zero mean and unit variance, which improved the quality of our clusters. When it came to clustering, the written algorithm does work, but we went with sklearn. KMeans for performance purposes, however the written one gave us good data on how the clusters changed over each time step.
With respect to the web application we had some difficulty working as a team simultaneously with Microsoft VS Code Live Share.
Accomplishments that we're proud of
We are proud of being able to put out such a large project in ~24 hours. It required bringing elements from many different stacks including data analysis, web development and tools like Excel.
We also tried to stay true to the values of a datathon, and this means that we made sure data took center stage. By doing this we were able to generate some pretty cool insights and confirmed some predictions of ours that made sense.
What we learned
We learned how to clean and use large datasets, and how to design methods to use the information. We came up with quite a few recommender algorithms before we settled on the matrix factorization/k-means++ idea, which gave us the ability to prioritize a small number of features that a user could implement while also using all of them in the background to make clusters. Because we were unfamiliar with k-means, we wanted to make sure we learned it well. In order to do so, we actually wrote our own implementation rather than using a standard package to make sure we could learn the ins and outs!
We also spent a lot of time learning how to work together effectively while being remote. Unfortunately, none of us were colocated so we built our entire tool remotely! We learned to leverage the voice chat feature of Discord, Visual Studio's live code share, and DeepNote (Jupyter Notebooks with real-time collaboration features).
What's next for whereishould.live
We would like to incorporate more of our data into various graphs and charts. This would give users even more comprehensive information on their city rankings.
We would also like to eventually include more cities, so that users have more choice than the ~700 that they have currently.
Most importantly — we would like to continue to improve the user experience in everything from latency to the style of the graphs to make sure that people have an enjoyable time using the site.











Log in or sign up for Devpost to join the conversation.