-
-
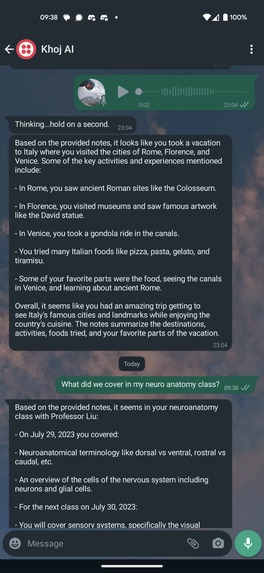
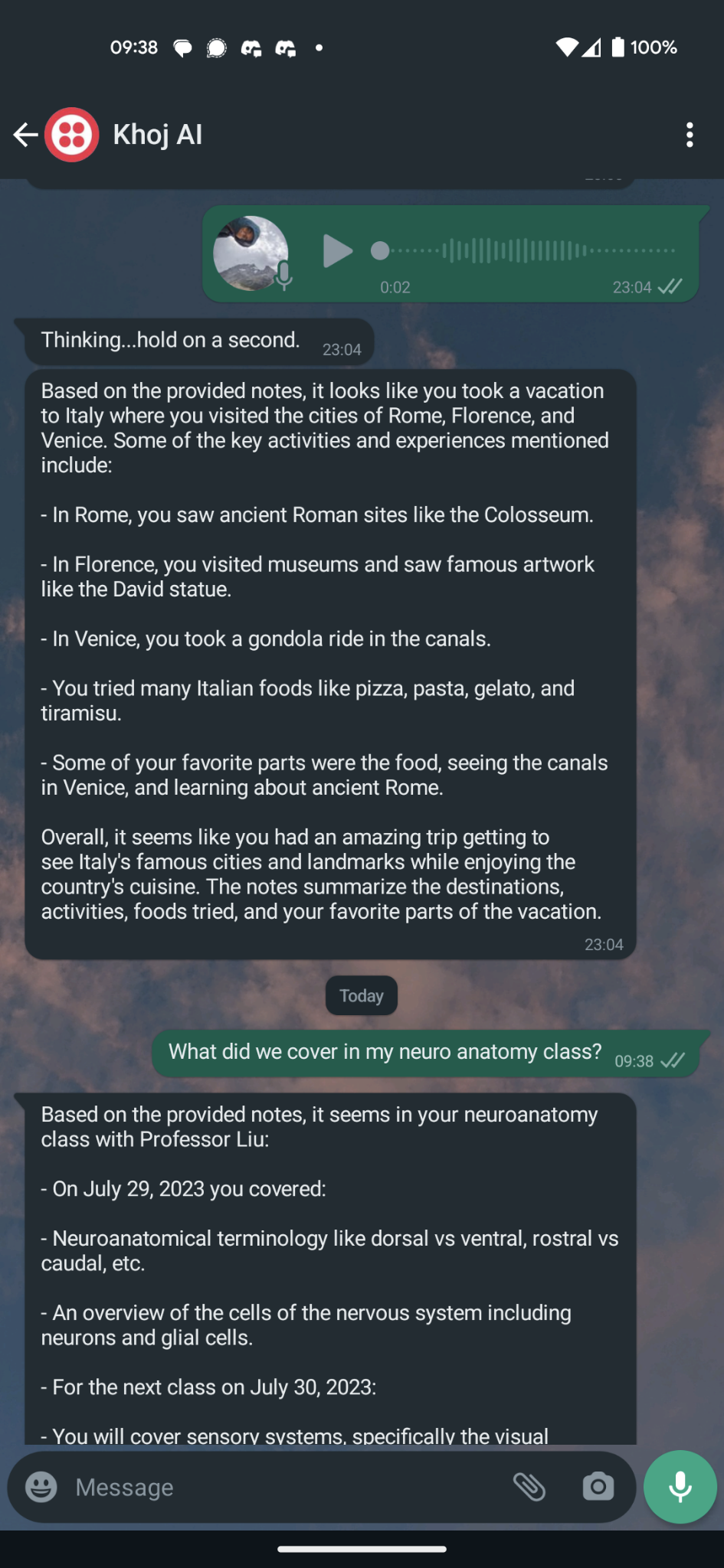
Claude returning a valid response based on a voice-first query
-
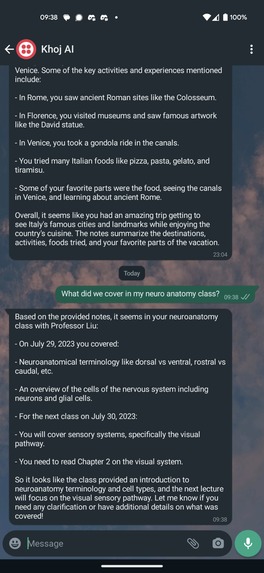
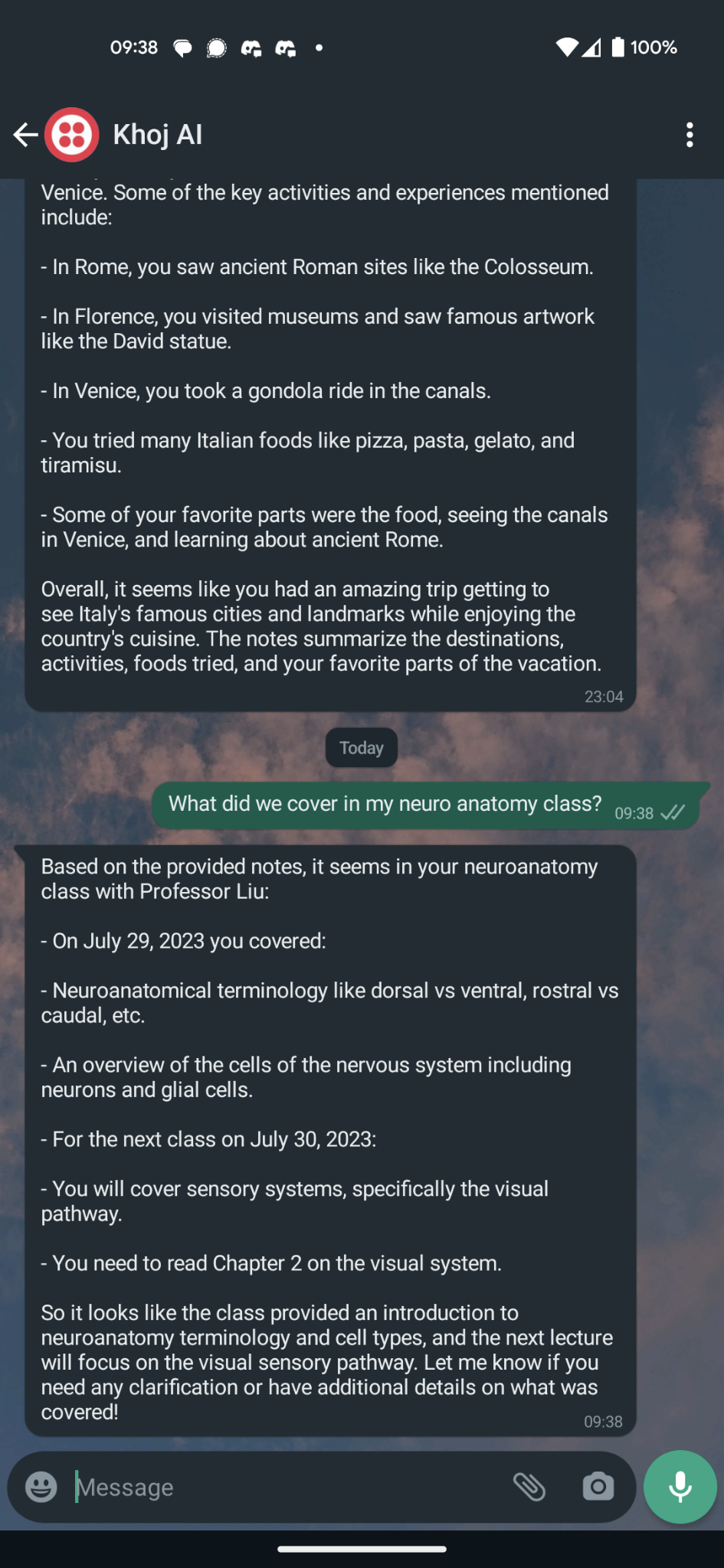
Claude returning a valid response to a text-based query
-
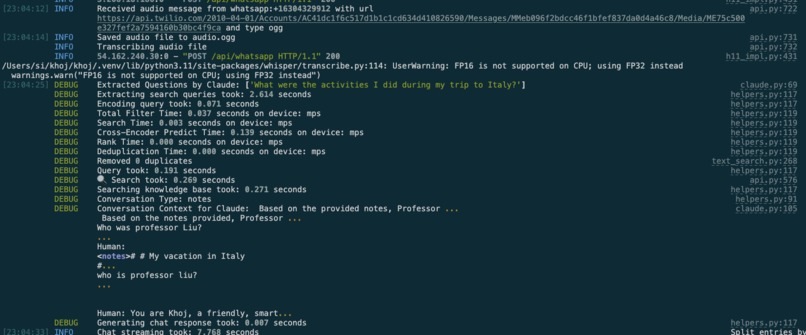
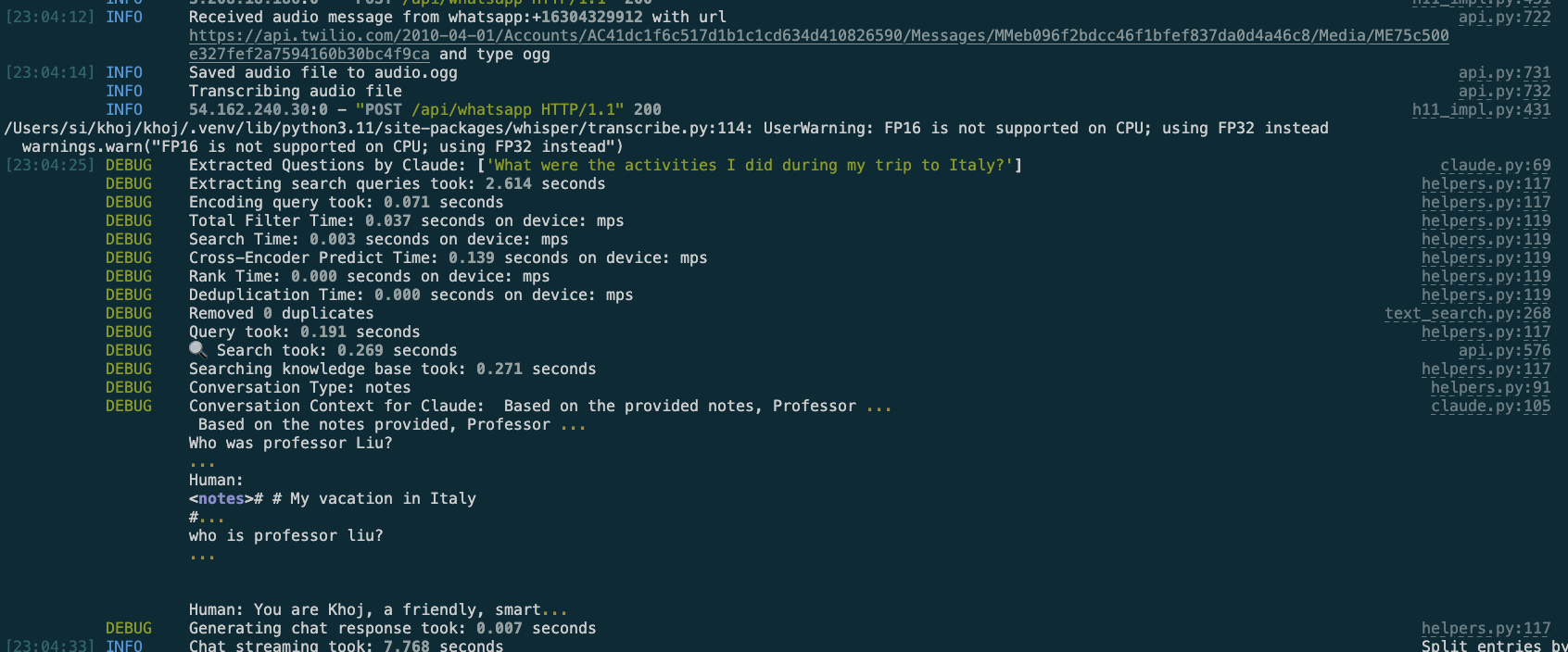
(logs) Claude successfully extracting additional questions and returning a valid answer to the user
-
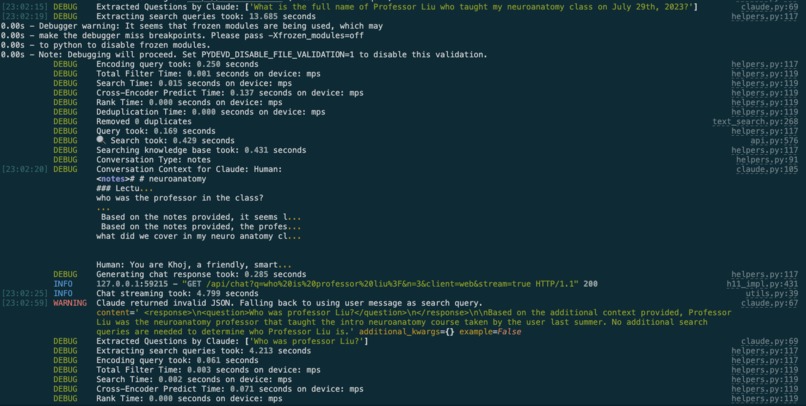
(logs) Claude extracting addtl questions based on the user's input - was not able to return XML, so fall back to the user's query.

Inspiration
Our goal is to create tools that help people seamlessly integrate with their digital data. One of the biggest pain points for people who need to do search and retrieval with their digital information today is that they must translate their thoughts into some keywords or machine-understandable format to extract that data.
What we want is to feel like our data is perfectly integrated with us, accessible in the formats and places that feel most natural. That's why we worked on integrating a voice-first interface into our digital assistant that uses natural language queries for information retrieval.
What excites us about this idea is that it can unlock new human potential if we remove the brain-machine barrier. We also believe it can help advance our relationships amongst one another as we spend less time managing our data, and more time being present.
What it does
It allows you to talk to your notes, documents via WhatsApp. You send an audio (or text, if preferred) message, and your bot will send you a response using your knowledge base for context.
How we built it
- We extended our existing open source project which does desktop-first document-based retrieval. This portion allows us to talk directly with our personal knowledge base on a locally-run server.
- We expose that service on the public internet using ngrok.
- We setup a Twilio-WhatsApp integration which relays WhatsApp message events to our specified API endpoint via Twilio.
- In the backend, a message event is parsed for either the text body or the audio message. If it's an audio message, it's transcribed to English using OpenAI's whisper model
- The search query is relayed to Claude using Langchain. First, we ask Claude whether the query needs additional information from the person's personal dataset.
- For example, if we were talking about my vacation to Italy, and then I asked "what was my favorite pizza restaurant on that trip?", Claude will use this step to search for "pizza restaurants I ate at in Italy" against my knowledge base. It returns this data in an XML-formatted list of questions.
- Using notes from my personal data, Claude will now answer/respond to the the original question I relayed in my voice message.
Challenges we ran into
- Audio parsing and transcription takes a bit of time. Twilio by default times out the request after 15 seconds, if the response hasn't arrived in time. To mitigate this, we return a placeholder message to indicate to the user that the message has landed successfully, while we run an async operation to run the audio and data processing in a separate message.
- I tried at first to use JSON-responses from Claude to run the initial question extraction step, but found quickly that XML-based parsing was performing much better. Thanks to the Anthropic team for that recommendation 🙂
- We struggled a bit with figuring out how to get Twilio and WhatsApp talking to each other, made worse because our IP seemed to be getting flagged as a bot and preventing us from accessing configuration pages. Mitigated by using a VPN.
- Claude responded to a query in Korean at one point. I don't know why that happened, but perhaps my audio sounded Korean?
Accomplishments that we're proud of
- The interaction pattern feels fairly natural and Claude is able to provide us with high quality results based on the voice-based query
What we learned
- How to interact with Claude for best output/response quality
- How to setup a Sandboxed WhatsApp bot
- Using OpenAI's whisper for voice transcription
What's next for WhatsApp-first personal voice assistant
- The assistant response should be converted back to speech based on the user's voice configuration of choice. The experience should feel like you're talking to your own personal brain end-to-end.
- We want to setup a service where a user can just upload their documents, rather than using the personal-server based configuration

Log in or sign up for Devpost to join the conversation.