-
-
Project Overview
-

Contact Information
-
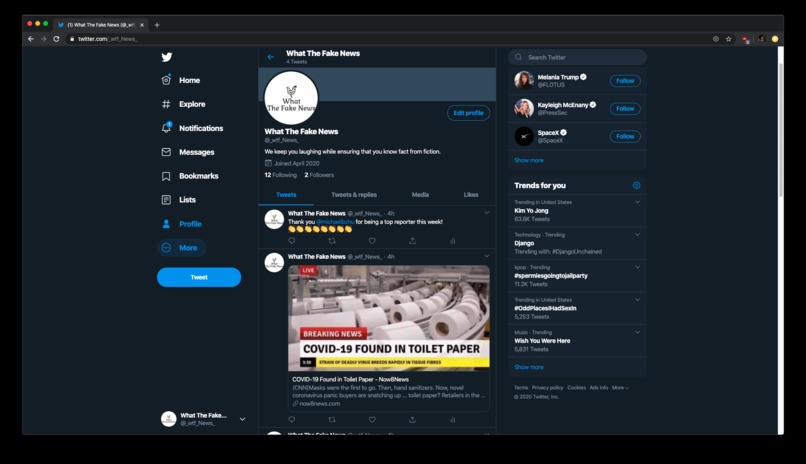
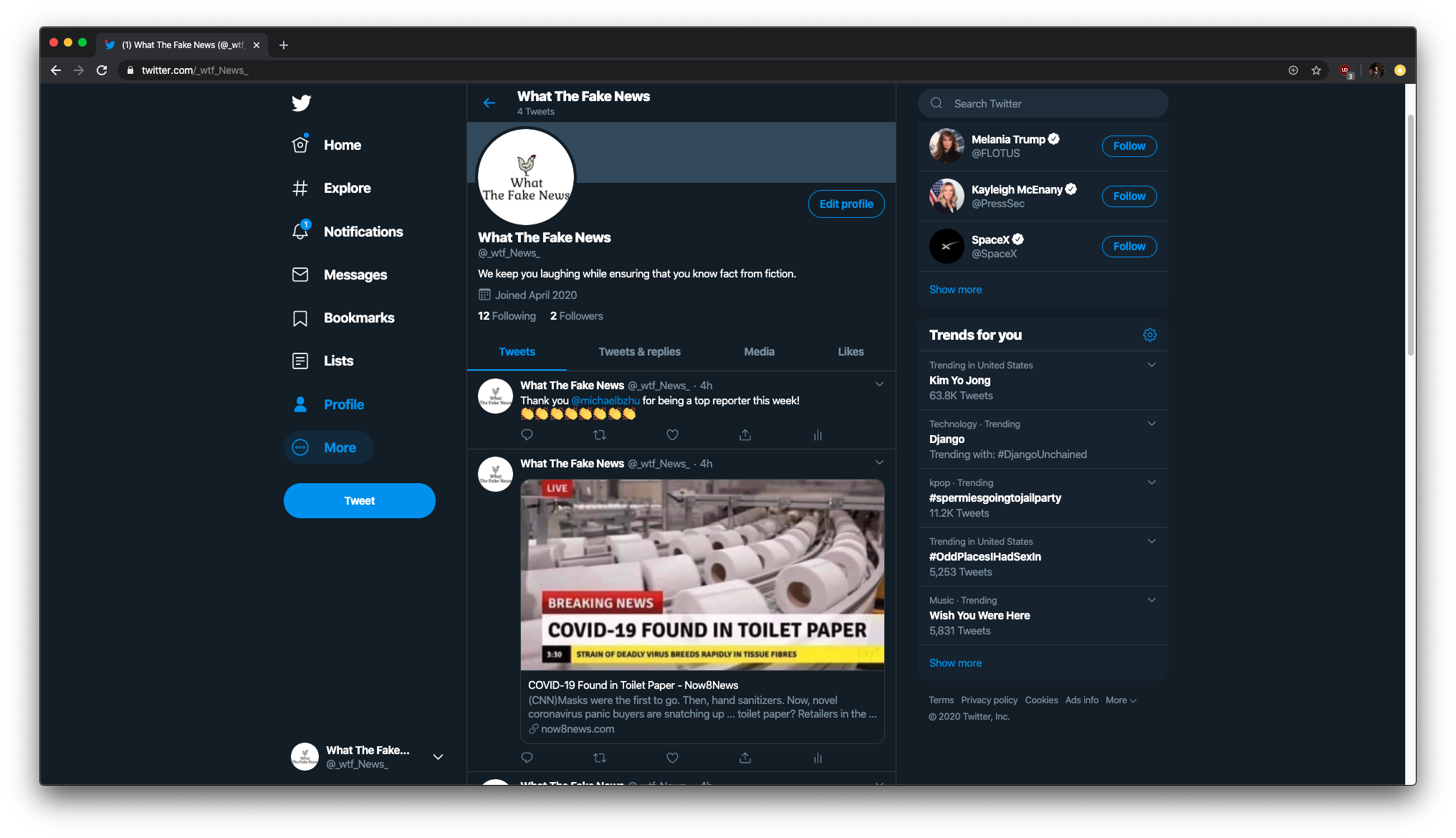
Follow us on Twitter @_wtf_News_

Inspiration
We wanted to create a fake news classifier model, but make it more user-friendly than existing fake news projects. We found that almost all fake news projects are built in the form of a web application, chrome extension, or mobile app. These types of projects are generally only for the sake of training a machine learning model, and pay negligible attention to the user experience around the product. We wanted to go above and beyond that standard, by not just training a model but also designing a product that is able to engage with users in creative ways.
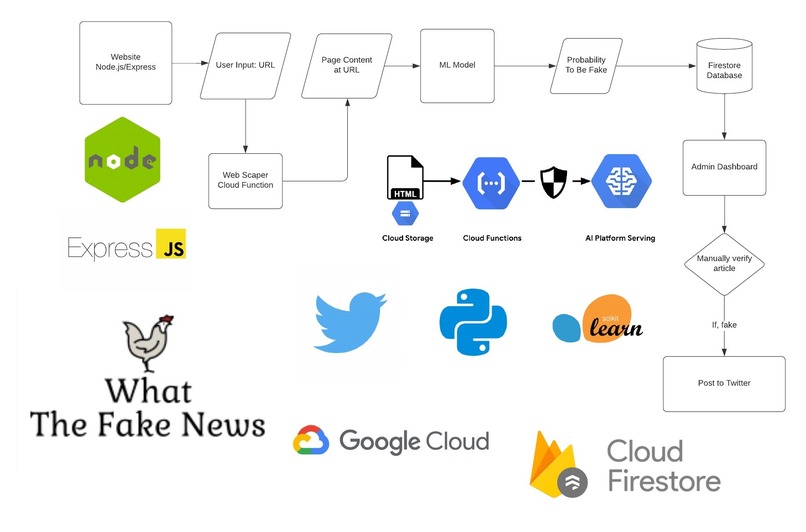
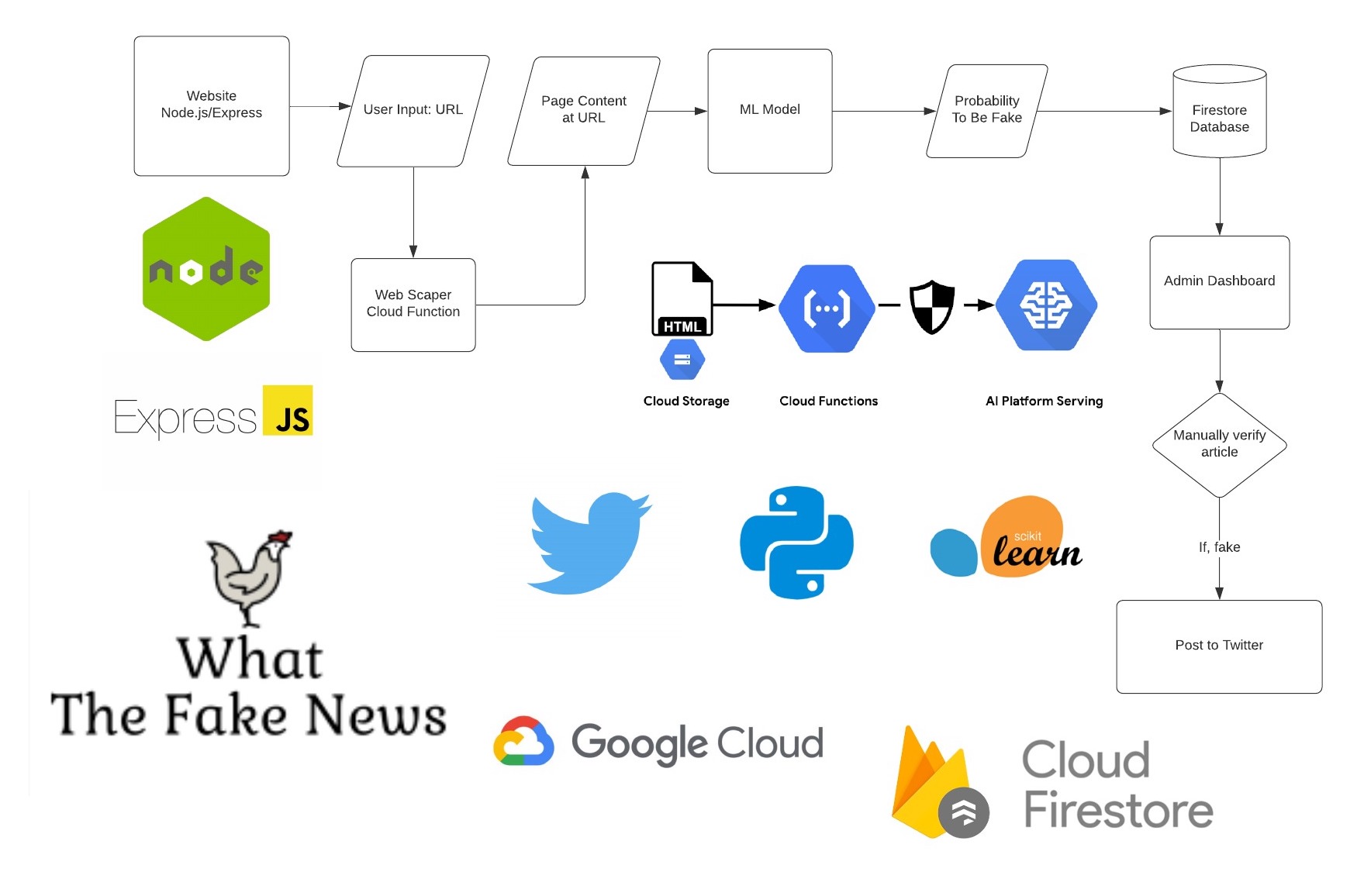
Project Overview
Our project consists four main components: a twitter bot, a website, a machine learning model, and an admin dashboard. A live version of our website is available at https://hacknow-275310.firebaseapp.com/index.html
The Twitter Bot
The twitter bot posts fake news articles that are verified by our internal team of moderators. It also highlights the top users of our product so that we can reward loyal users. For the majority of users, the twitter account will be their main interaction with our product. We believe that a twitter bot is much more advantageous than a chrome extension or web app because it doesn't require repeated actions from the user. Users don't need to copy and paste URL's every time they wish to check a website's veracity, they can simply hit the follow button once and they will receive updates in their feed automatically. Our goal is for the twitter bot to post fake news articles that are so absurd that it brings joy to the reader in the form of laughter. Of course, there is also an added moral bonus of being able to prevent the spread of malicious fake news.
The website
Our website is built using Node.js and Express, and it serves as a companion site to the Twitter bot. It is meant to be a form of engagement for more dedicated users, those who have a true passion for journalism and upholding the truth. The website has a form where people can report articles that they believe to contain false information. The report is then sent to our Firestore database which saves the report for one of our internal moderators to review. Once an article is confirmed to be false, we post it on twitter through the Twitter API and tag the original reporter to credit their contribution. We also have a live leaderboard of users who provide us with the most reports as another way to highlight our top users.
The admin dashboard
Our admin dashboard is what our internal moderating team uses to verify each report. It is built using Node.js and Express, and retrieves entries from our Firestore database to display as widgets. Each widget displays the URL of an article and the probability of that URL to contain fake news. The internal tool helps our moderating team save time by filtering out the articles that are least likely to be false. It also simplifies the process of posting to Twitter by utilizing the Twitter API to automatically tweet articles that are confirmed false.
You may be wondering how we were able to generate a probability value for each URL. This process works in two steps. First, we used the BeautifulSoup4 python library to scrape the text content at the given URL. Then this content is used as input to our machine learning model which outputs a value indicating the likelihood of the text to contain false information.
The Machine Learning Model
The brains of our project is built upon two machine learning features of Python's "sklearn" library. We used a Term Frequency Inverse Document Frequency (TFIDF) Vectorizer to process our database of hundreds of random articles and analyze the discrepancies between word frequencies in fake and real sources. We then used this structure to train a Passive Aggressive Classifier (PAC) to be able to determine whether any further articles that our users feed the website are indeed fake news. The decision_function method of the PAC class allows us to quantify the algorithm's confidence in its guesses by determining the distance between an article's TFIDF vector and the projection of that vector on the PAC's hyperplane. Having this information allows the website to feed the most suspicious news articles to our admins first.
Google Cloud
We used Firestore database to store the user reports from our website.
We implemented many of our python scripts, such as web scraping, as cloud functions so we could access them with a POST request.
Our ML model is deployed to Google's AI Prediction Platform
Finally, we used Firebase hosting to deploy our website at https://hacknow-275310.firebaseapp.com/index.html
Challenges We ran into
On the web development side, we encountered a lot of authentication errors when we were trying to deploy our project to Google's Cloud Platform. Thankfully, we were able to leverage the mentoring channels to figure out where we made mistakes and how to fix those errors.
We also couldn't find the documentation on how to request predictions from the model using Node.js, so we ended up creating a python cloud function as a workaround. Our Node.js server would make a POST request to the cloud function, which then requests the prediction from our model and then sends it back to our server.
On the machine learning side, the biggest challenge that we faced was figuring out how we could save the matrix and vector created by the machine learning algorithm so that the data set wouldn't need to be retrained every time we wanted to make a guess about a new article. Eventually, we found the "joblib" library which allowed us to save the objects created by the ML algorithm into files that were much smaller and more manageable for using Google's cloud services.
Accomplishments that We're proud of
We are proud that the end product was as fun and lighthearted as we had wished. We were looking for a way to make fake news algorithms more accessible, and I think What The Fake News made big strides towards what we wanted to achieve. This was also Matt's first hackathon and we are both fairly new to machine learning algorithms, so we are proud of the progress that we made in understanding what goes into constructing one.
What We learned
On the technical side, we learned how to create web applications with Express, use scikit-learn to train and develop machine learning models in python, and how to deploy our projects to Google Cloud. We also had a great time speaking with mentors from our VC sponsors who helped us realize that it's important to not just develop a great technical product, but also think deeply about how this product will interact with users. Will it be eye-catching for a first time user? What features will incentivize users to keep coming back? They gave us great insight into the business side of our project, that we didn't initially consider. Taking this into account, we ultimately learned not only a lot about machine learning algorithms and web development but how to make it fun. In a CS major's eyes, these types of side projects will always evoke our excitement, but this project allowed us to see how important usability is for ensuring a product's success.
What's next for What The Fake News
After hack:now, we will continue to developing this project by refining the machine learning model to improve its accuracy and fine tune its parameters. We want to implement a reinforcement learning model so that our algorithm will improve the more we use it. We are also going to redesign the entire front-end of our product, from the logos to our tweeting templates to our website's appearance. This will ensure that we maintain a consistent theme throughout the user experience and highlight our unique branding. Finally, we will rebuild our admin dashboard with the goal of automating as much work as we possibly can for our internal moderating team.



Log in or sign up for Devpost to join the conversation.