-
-
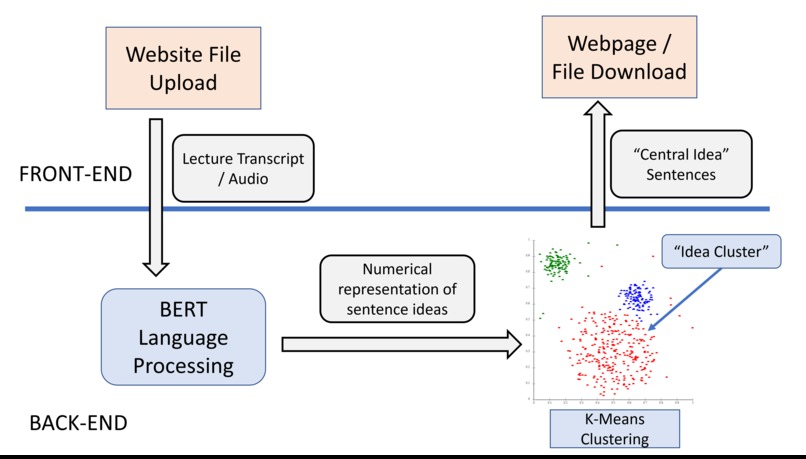
Project Flowchart
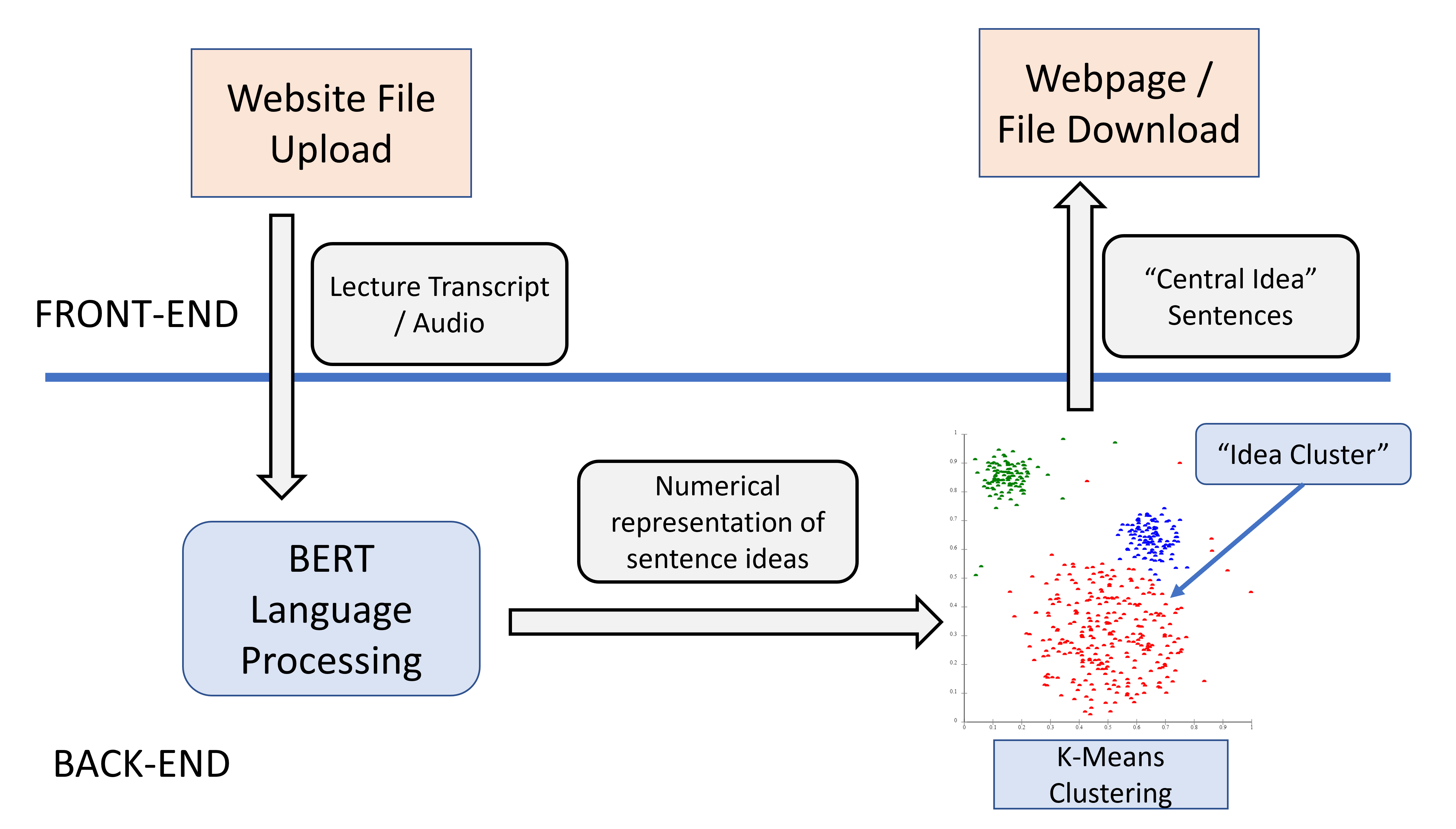
What it does
What’s the Word? offers a solution by summarizing hour-length videos into 1-page study guides, allowing students to review lecture material more conveniently, comprehensively, and efficiently.
Inspiration
Online education has generated millions of hours of Zoom lectures. Combing through these lectures for exam-relevant information is both boring and tedious.
How we built it
Natural-language processing to convert English sentences into numerical vectors using Bidirectional Encoder Representations from Transformers (BERT).
Find clusters of sentence ideas via K-Means Clustering.
Audio-to-text conversion using Google Cloud API.
Web Stack
Flask
Challenges we ran into & what we learned
Completing a large-scale project within 15 hours necessitated strong teamwork and time management.
Learning to implement BERT API required us to learn about natural language processing.
Understanding K-Means clustering required study of linear algebra.
Google Cloud API helped us learn about authentication mechanisms.
Delimiting sentences using different forms of punctuation yielded different results.
Accomplishments that we're proud of
Our product is useable in our own lives. The next time we are confused in class or are overwhelmed by our academics, we can use our website to streamline our studies.
We are also proud of the quantity of APIs and Python modules we learned about. For many of us, this project was a first exposure to the more complex machine learning techniques.
What's next for What's the Word?
Each bullet-point note will list a time-stamp so that the student knows which part of the lecture they can revisit for additional information.
We also want each bullet point to include a few links to external studying resources that can supplement their understanding.
Finally, we also want to train our model against actual exam questions so we can maximize the probability that a given exam question is covered by our study guide.
Bibliography and Literature Review
In order to see how the BERT model can be used to summarize Lecture transcripts, we used Derek Miller’s study “Leveraging BERT for Extractive Text Summarization on Lectures”. The study can be found here https://arxiv.org/pdf/1906.04165.pdf.
In order to implement the BERT module, we used Arushi Prakash’s code and article. The code and article we used can be found here https://github.com/arushiprakash/MachineLearning/blob/main/BERT%20Word%20Embeddings.ipynb and here https://towardsdatascience.com/3-types-of-contextualized-word-embeddings-from-bert-using-transfer-learning-81fcefe3fe6d.
K-means clustering graphical representation from https://en.wikipedia.org/wiki/K-means_clustering.






Log in or sign up for Devpost to join the conversation.