-
-
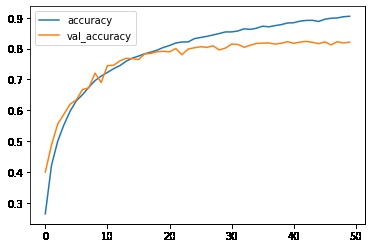
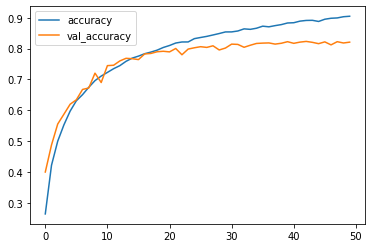
Training logs: accuracy
-
Training logs: loss
-
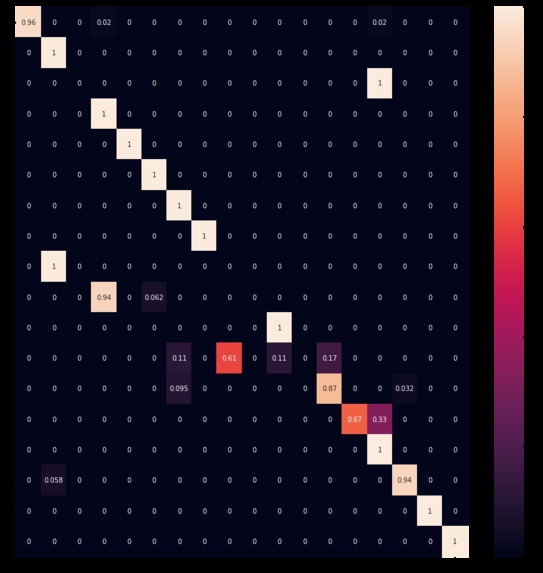
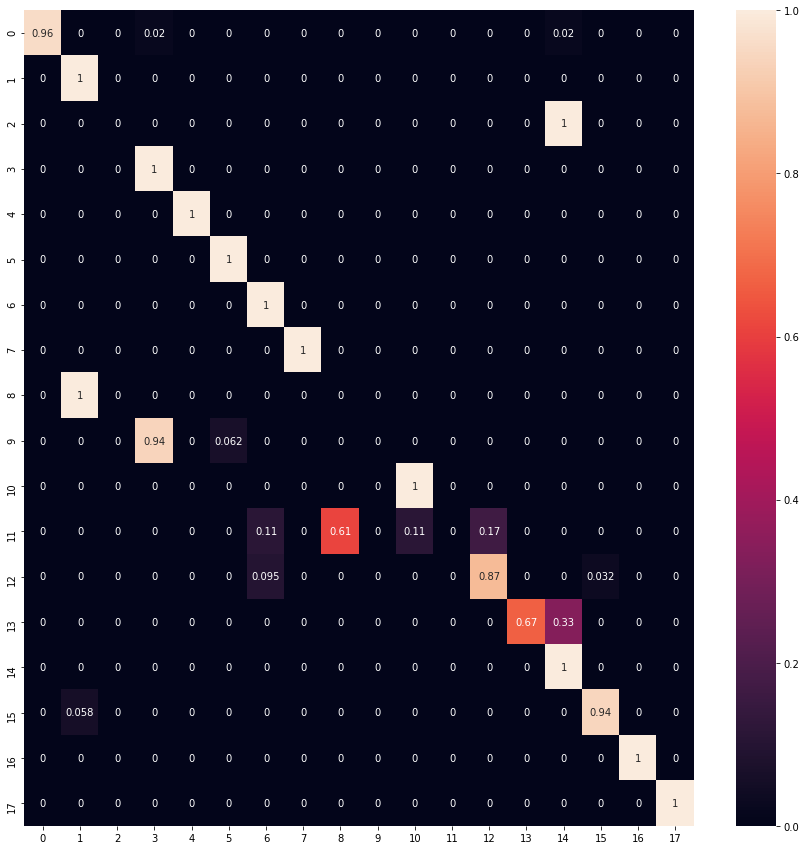
Test dataset confusion matrix
-
The mel spectrogram of the sound of my laptop crying
Inspiration
Marine species are dying off faster than they can be replenished. 300,000 whales/dolphins are killed/year and these are mainly due to human activity such as large-scale fishing and pollution.
What it does
WhaleWatch is a software that does automated classification of marine species based on underwater sounds. These sounds are captured by special audio devices. The idea is that big fishing ships would place these devices underwater to find out what species of marine life are around them at that time. If there are any endangered species, they can go fish somewhere else or inform authorities. WhaleWatch can also be used by marine scientists and researchers who need to track the movement of certain animal species over time or it can be used by conservationists who want to discover endangered marine life so that they can preserve it.
How we built it
I used the Watkins Marine Mammal Sound Database:(https://cis.whoi.edu/science/B/whalesounds/about.cfm) to train a machine learning model that differentiates between 18 classes of species of marine life. The audio files were first preprocessed with a fast fourier transform and a MEL filter to be converted into a MEL Spectrogram, a visual representation of the audio file. The Fourier Transform separates the frequencies of audio and the MEL filter transforms underwater sounds into data that would be more interpretable to human ears. After preprocessing all the images, I trained a CNN (Convolutional Neural Network) to inference marine animal species from the mel spectogram.
Challenges we ran into
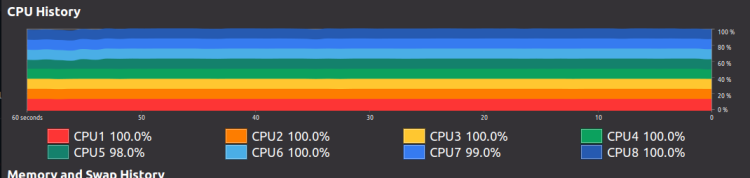
The biggest and only challenge I ran into was preprocessing the dataset. It was a terrible pain. It was excruciatingly slow to convert every one of nearly 3000 audio files into MEL spectogram and save the file. I ended up implementing multiprocessing in the data preprocessing script and consequently saw my laptop freeze for a solid 15 minutes as every one of my cpus was operating at 100%, which led to me being nearly half an hour late to my math class. I decided to then abuse google colab's cpus instead and after a few hours all the data was preprocessed.
Accomplishments that we're proud of
Proud of getting decent accuracy on this task. Proud of implementing multiprocessing in a python script.
What we learned
- Learned about how to do audio classification (converting to Mel Spectrogram and using a CNN)
- Learned how to do multiprocessing in Python
- Learned to never operate all your laptop's cpus at 100% ## What's next for WhaleWatch
- More species, better data, and deployment in the cloud
Built With
- keras
- librosa
- tensorflow



Log in or sign up for Devpost to join the conversation.