-
-

Categories of COVID-19 disinformation for the Deep Learning Models
-
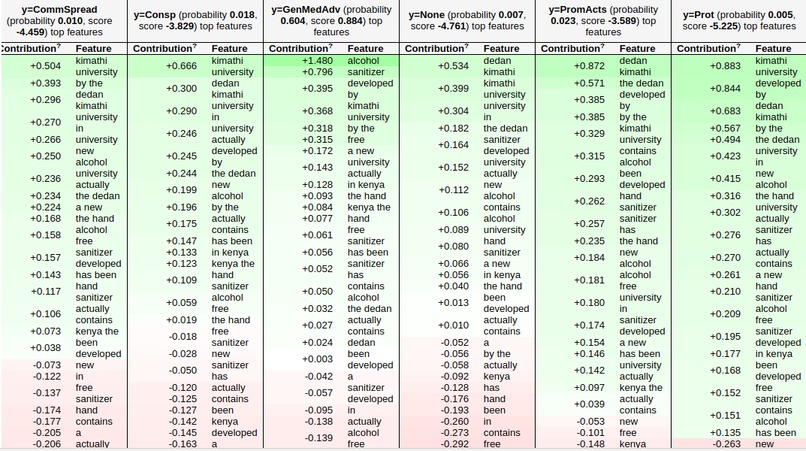
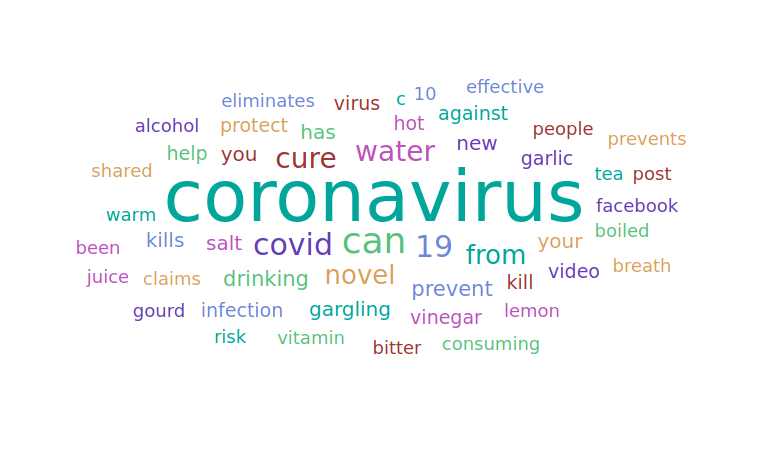
Words associated with some COVID-19 dinformation categories
-
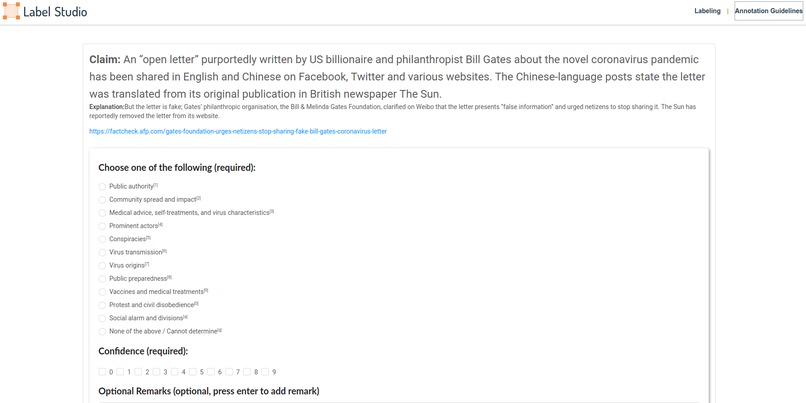
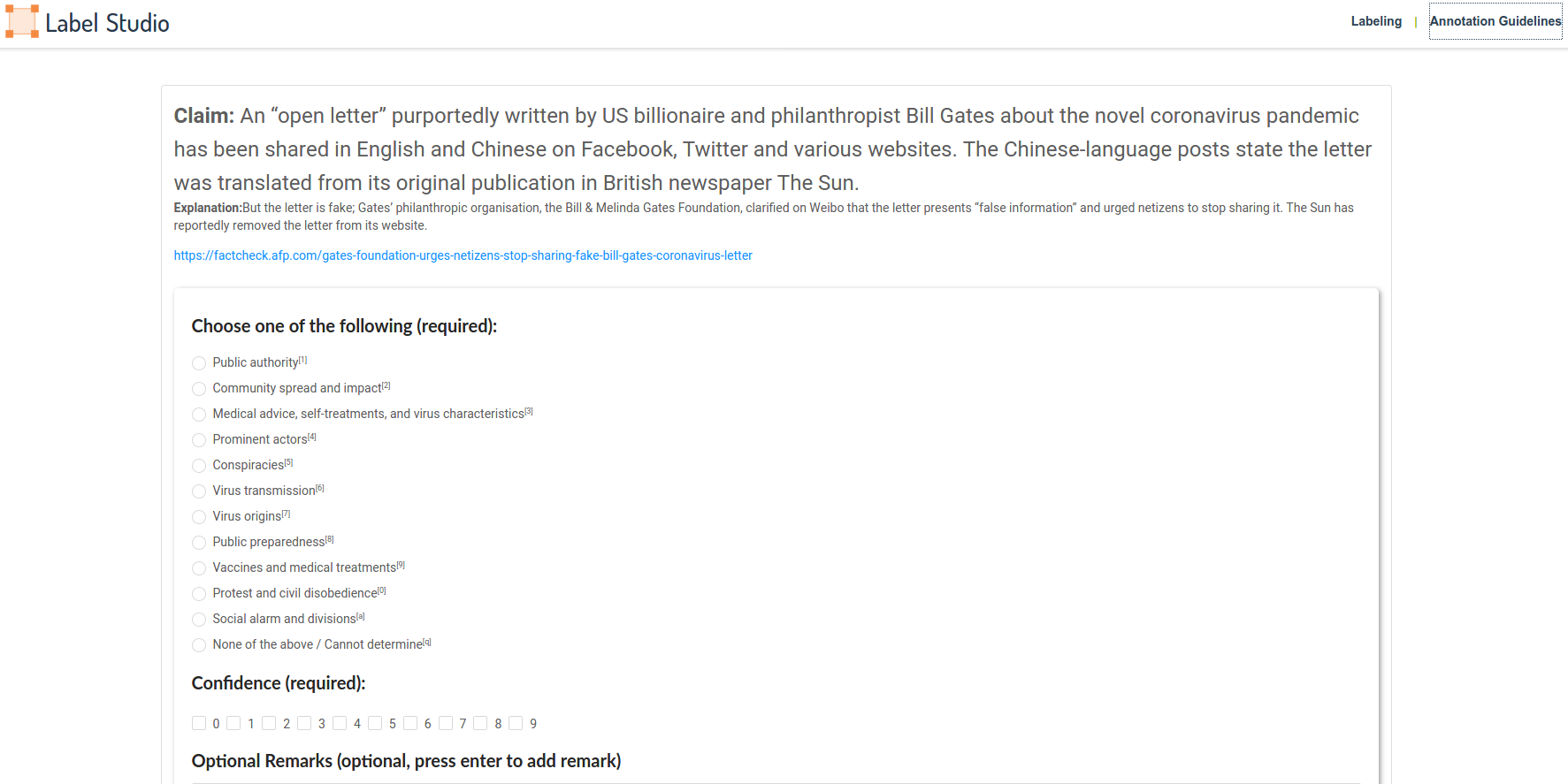
User Interface for collection of human-labelled categories, for validation
-
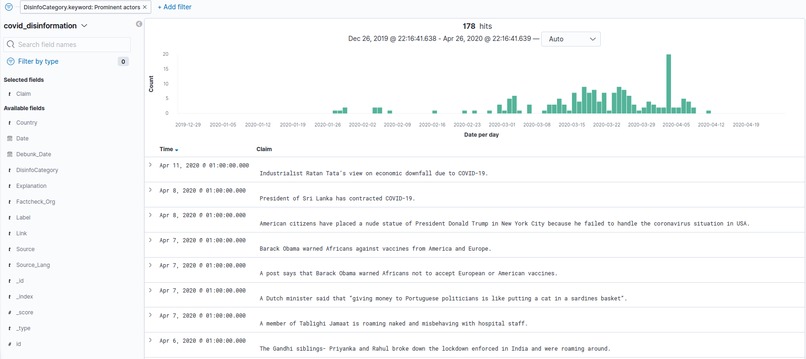
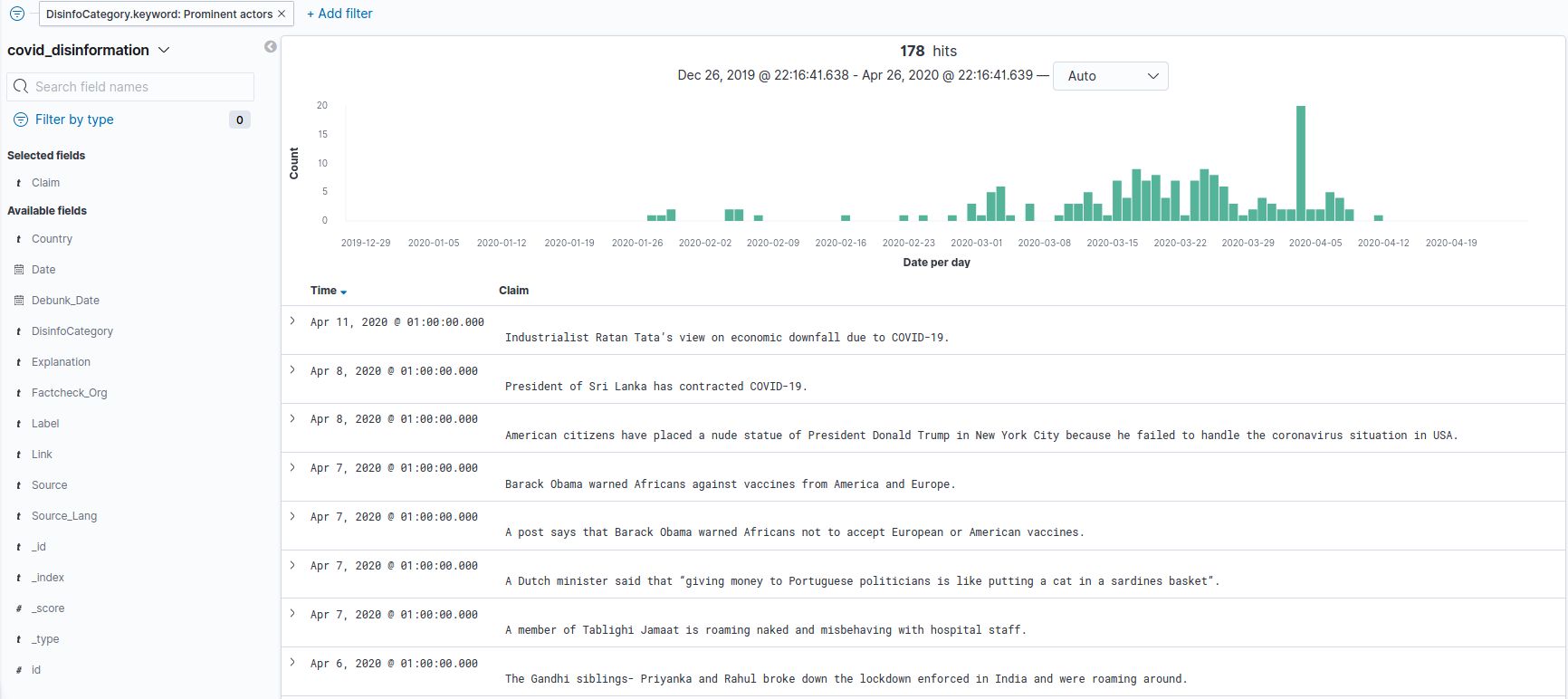
User Interface based on Kibana, user can explore debunked disinformation under a given category (about prominent figures in this case)
-

Users can get an overview of disinformation stories under a chosen category (COVID-19 "cures" in this example)

The problem this project solves
The COVID-19 pandemic has given rise to an online “disinfodemic”, with dangerous real-life consequences (burnt 5G masts, deaths from unproven and dangerous “cures”, disregard for healthcare advice).
Daily, tens of millions of posts about COVID-19 are shared through Facebook, Twitter, Instagram, and other platforms.
Therefore, journalists, fact-checkers and health authorities are overwhelmed by the effort to monitor these daily, identify the disinformation and rumours, and debunk them effectively. The International Fact-Check Network has over 100 fact-checkers working daily in over 70 countries, who have so far debunked over 3,500 false stories, however this is just a drop in the ocean.
Existing automatic tools for fact-checking and disinformation analysis have been optimised for accuracy on political disinformation. When applied to COVID-19 disinformation, they are significantly less accurate.
Moreover, COVID-19 disinformation falls into new, distinct categories (e.g. origin, social distancing, government lockdown policies) and there are no tools, which given a social media post will classify that according to such COVID-19 specific categories. The ability to do so automatically and reliably is paramount, as fact-checkers can then easily navigate prior debunks related only to the relevant topic (e.g. origin) in order to speed-up their work.
The solution
The urgency of the situation calls for open, scalable and cost-effective solutions that increase the efficiency of processing and classifying information around COVID-19.
Solutions like ours should already be in the hands of professionals like journalists, researchers, and everyone working on high volumes of COVID-19 (dis)information.
The Goal:
- To provide journalists, media, fact-checkers and other professionals with an AI-based COVID-19-tailored solution to help automate part of their workflow and minimise repetitive tasks
- To provide these professionals with real-time analytics and insights over COVID-19 information like trending topics, categories with the highest volume of disinformation, etc.
To this end, we have developed open source deep learning AI techniques to automatically identify and cluster COVID-19 (dis)information into ten categories:
- Public authority actions, policy, and communications
- Community spread and impact
- Medical advice and self-treatments
- Claims about prominent actors
- Conspiracy theories
- Virus transmission
- Virus origin and properties
- Public preparedness
- Vaccines, medical treatments, and tests
- Protests and civil disobedience
- Other
Post-hackathon, we envisage deployment in two main kinds solutions:
- Operating as a standalone service for individual users (fact-checkers, researchers, etc.) who wish to classify and analyse a corpus of claims
- Interfacing with CMS and other working environments for organisations that wish to integrate automatic COVID-19 information classification features into their internal processes
Achievements During the Hackathon
We coordinated the collection of large amounts of high-quality human-annotated data and developed open source deep learning AI techniques to automatically identify and cluster COVID-19 (dis)information into ten categories:
- Public authority actions, policy, and communications
- Community spread and impact
- Medical advice and self-treatments
- Claims about prominent actors
- Conspiracy theories
- Virus transmission
- Virus origin and properties
- Public preparedness
- Vaccines, medical treatments, and tests
- Protests and civil disobedience
- Other
We also developed an Elastic search/Kibana proof-of-concept interface that demonstrates the added benefits of the automatic categorisation, through easy-to-use visualisations.
The solution’s impact to the crisis
The direct impact of our AI-based automation will be in achieving increased efficiency and minimising the workload of news media, journalists, and other professionals covering the pandemic. As compared to existing tools and products, our solution is trained on COVID-19 data optimised for COVID-19 information, which delivers high accuracy results, minimising the effort required for manual post-editing and corrections.
The proposed solution is furthermore advancing the innovation capacity of the European news industry by:
- making open source, state-of-the-art tools widely accessible to European news professionals and organisations independent of their financial resources and size;
- lowering barriers to access cost-effective AI based solutions for news organisations.
Our solution also strives to contribute to the strengthening of democratic institutions by equipping journalists with cutting edge technology in their effort to combat disinformation around COVID-19.
Finally, being open source, the proposed solution promotes the concept of open science and the uptake of the technology by other interested parties.
For an enhanced social and technological impact, we adopted a commercially friendly open-source approach, based on a SaaS freemium model. This will also provide ongoing sustainability. The key organisations in the team are world-leaders in development and deployment of open-source text, image, and video processing algorithms and tools: the University of Sheffield’s GATE NLP team and CERTH. This is complemented by the software deployment and integration expertise of ATC. Other researchers and companies external to the team will also be able to enhance and adapt it to other contexts (e.g. automatic categorisation of COVID-19 research articles).
To further maximise our reach and impact, we plan to offer the maximum possible flexibility by developing a solution that works based on the SaaS model, operating through a web based platform, while also exposing a public API that can be connected with the backend of existing disinformation analysis tools and platforms, or be interfaced with CMSs, data repositories, collaboration platforms, and other working environments.
The necessities in order to continue the project
We would like to adapt the COVID-19 information categorisation to languages other than English. To do this, we will need some time and ideally a small amount of funding in order to recruit speakers of at least the major 5 or 6 languages, who can help us adapt the solution to the languages and countries most affected by COVID-19 disinformation.
Costs:
- 5,000 euros per language to be covered.
- 10,000 euros for a software developer to optimise, stress test, deploy, and document the solution as a highly scalable cloud-based Software-as-a-Service solution
The value of the solution after the crisis
The need to study, analyse and understand SARS-CoV-2 and its implications on our lives and societies will remain long after EU countries have lifted their lockdown restrictions. Even after the pandemic has been contained, researchers, media, social scientists, governments, and companies will still face the need to process documents and information related to COVID-19.
In addition, we will continue with our academic research and experimentation, in order to develop further the accuracy of the algorithms. We will also aim to add additional facts to the categorisation, e.g. which platforms were affected, whether the disinformation exploits tampered images, false narratives, old videos, etc. We will also work towards expanding the language coverage beyond English, in order to make the MVP solution relevant to other widely spoken languages.
Furthermore, the proposed solution is easily scalable and adaptable to other medical topics (e.g. anti-vaccine disinformation), especially looking at the intersection of SARS-CoV-2 vaccines and anti-vax disinformation.
Finally, the solution is open source, which means it can be further developed and adapted by other interested parties to their needs and context of work.
Special thanks
In addition to the team members, thanks are due to:
- Johann Petrak, who hacked the web UI for annotating COVID-19 disinformation classification and took care of many methodological aspects
- Mia Polovina, Andreas Grivas, Steven Zimmerman, Zlatina Marinova, Nikos Sarris, James Wood, Diana Maynard, Julia Ive, Lamiece Hassan, Tosin Dairo, Jon Chamberlain, Francesco Lomonaco, Tasos Papastylianou, James Allen-Robertson who all volunteered time to manually some disinformation examples so we can train the machine learning models. Apologies if I missed anyone out.
Built With
- deep-learning
- elastic
- javascript
- machine-learning
- natural-language-processing
- python











Log in or sign up for Devpost to join the conversation.