-
-
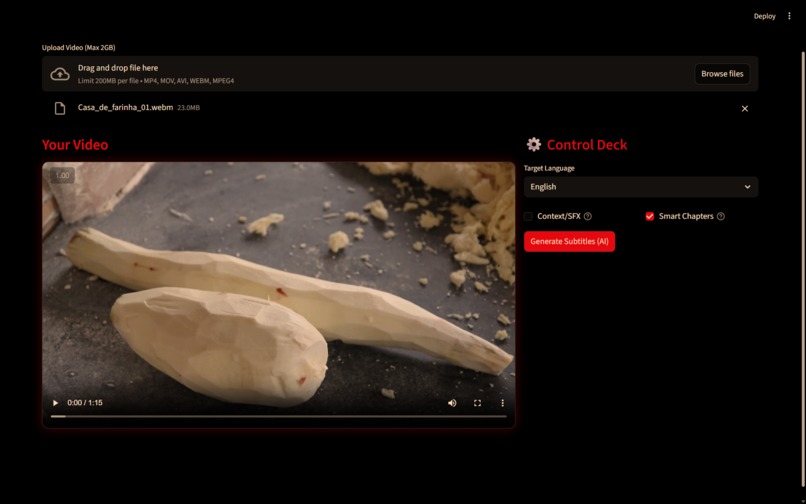
Welt VX User Interface
-
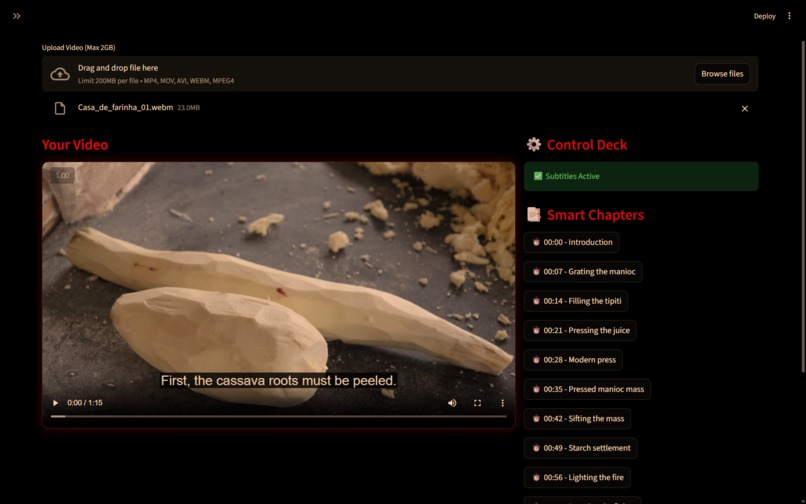
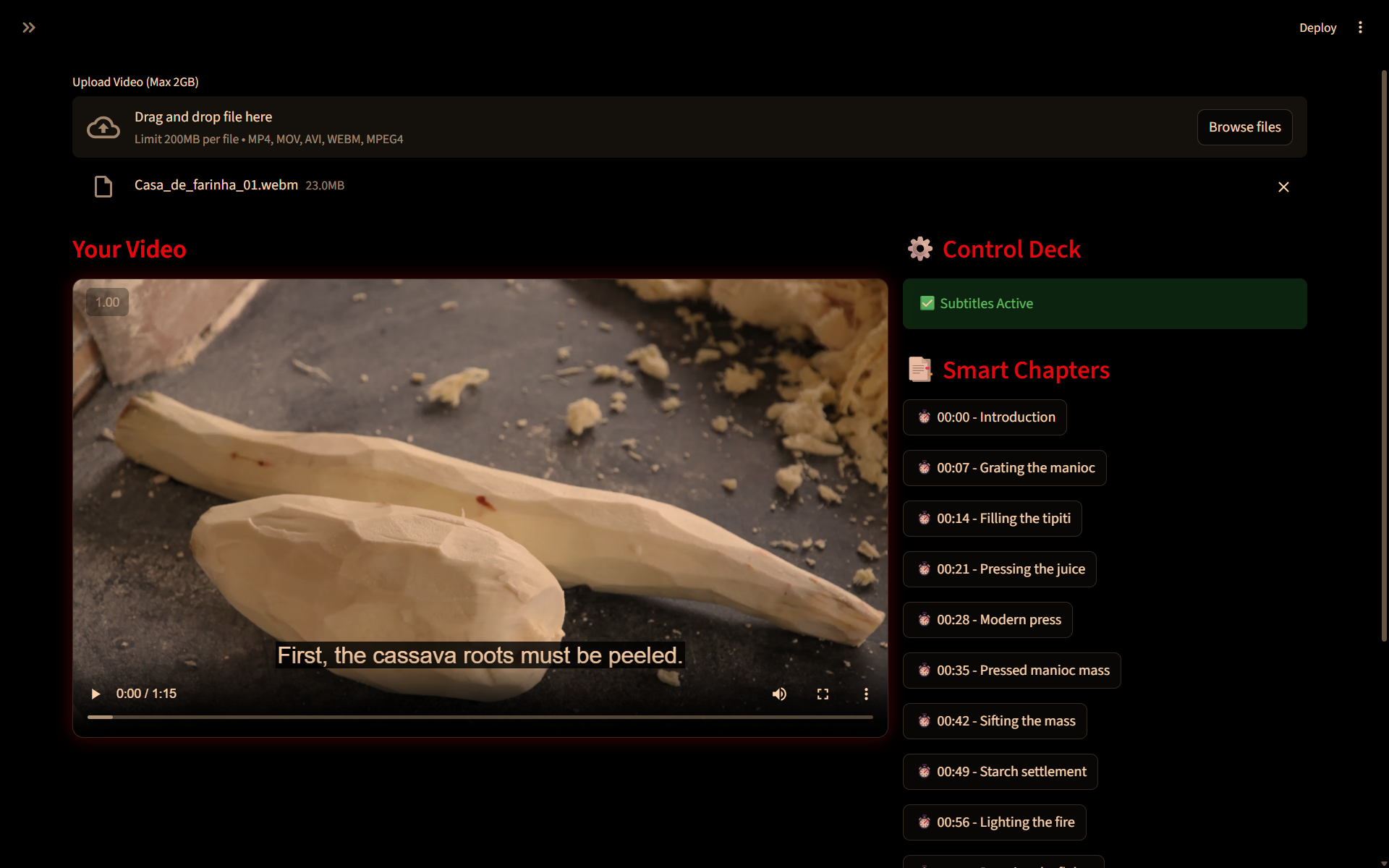
Generated subtitles and smart chapters
Inspiration
I watch alot of foreign shows and content, and most often the bottleneck from getting the full experience is the localization. This made me feel the need for a tool to enable great quality localization in real time, without any manpower. This was not the only problem I encountered with videos, though; a viewer doesn't know what content lies in the video till it is played and verified. Sometimes, this leads to viewing undesirable content. 'Undesirable' is a subjective description and requires a personalized filter.
AI has reached a stage where its capabilities are sufficient for enhancing viewer experience with personalization, be it cinematic or educational. With Gemini providing advanced multimodal capabilities, many services can be realized with one API.
What it does
Welt VX is a Video Intelligence Environment that is built on a Modular Agentic Architecture, using an Orchestrator to handle flow of control by intent routing a request to their specialized agents.
- Multimodal analysis: Welt VX recieves a video from the user and uploads it to Gemini's secure context window. Gemini extracts auditory and visual information, generating translated text that can also include visual context ([Alarm ringing], [Laughing],[Applause] for appropriate situations in the video content).
- Matrix Language distinction: Welt identifies the most spoken language, or the matrix language, and formats any other language in Italic font with a prefix tag having the name of this language. This helps preserve important cultural context in the video.
- Smart Chapters: Welt uses Gemini's multimodal capabilities to identify key timestamps in the video, so the User has a table of content to navigate through the video.
- VX Assisstant: VX Assisstant is an agent that uses Human-in-the-loop approach for iterative refinement; Users may report any instance of faulty subtitles/chapters/timestamps with reference (timestamps for subs and chapter names or indices for chapters), explain the issue and what changes should be made, and the agent would follow the User's instructions in correcting that part. By utilizing an iterative approach, the output is refined and personalized while accounting for any instances of hallucination. VX Assisstant offers semantic seek, user may describe the scene they wish to jump to, and the assisstant would perform that action and take them to that point in the video. The features are quick to access with smart chips, which introduce a dedicated inline input for selected feature (jump to, fix subs). Doing so avoids ambiguity in intent, ensuring accuracy and removing the need for user to provide context.
- Video Queries: VX Assisstant is able to watch the video and answer any queries from the viewer regarding the content using gemini's multimodal processing capabilities. A user might forget some details mentioned previously, or may be curious about the name of any article in the scene; the Agent is available for resolving these without disrupting the current experience.
- Content Scan: VX Assisstant recieves a description or a 'tag' for specific types of content or objects, and watches the whole video, checking for any content that falls under the description. It returns all instances of the object/content appearing in the video alongside timestamps. This may content be visual or auditory. This avoids any 'bait' content with hidden harmful parts, or any content that the user personally cannot tolerate. It can also be used for Analytical purposes.
How I built it
Welt XV uses a Modular Agentic Architecture: The Brain: Gemini 3 Flash Preview for lower latency and superior multimodal processing Interface: Streamlit (with custom CSS) for UI Logic: A robust backoff loop handles API request failures to prevent crashes
- The system orchestrator (weltengine), routes customized user requests (analyzes user intent to determine whether to 'jump' or to 'find') to specialized agents making the workflow dynamic and flexible.
- The specialized agent recieves the request and returns a defined output format
- The parsing and validation layer ensure the output doesn't contain invalid characters/format. In case of subtitles, time synchronization is validated by SRT
- For further refinement, a dedicated repair agent takes user feedback to change the output as per their request. The agent also provides scan, query and semantic seek features.
Challenges we ran into
Zombie subtitles: Earlier versions of Welt retained the subtitles generated in a previous iteration. I had to implement session state cleaning so the lingering subtitles would be cleaned in every new session. After the application functionality was tested, I added a reset option for starting over without terminating the current session.
503: During high frequency testing, I encountered many '503' errors with the Gemini API key. I built a robust Exponential Backoff retry loop to make it crash proof.
Invalid formatting: The agents would sometimes return unnecessary and disruptive characters (adding [] to seek commands). I implemented a parsing layer to process the output before it gets to the interface.
Suggestion Chips not responding: In the earlier implementations, using the suggestion chips would result in a prompt being stuck at the top of chat log, without any response from the AI. I modified the logic to trigger a response if the most recent message is from the user.
Accomplishments that we're proud of
I am most proud of VX assisstant. Most of my experiences with AI chatbots were unsatisfactory, and I was strongly against the idea of adding such a feature. Instead, I designed a Repair Agent, that utilizes human-in-the-loop approach for subtitle refinement. The users can report any part of the subtitles that requires change, along with the timestamp, and VX assisstant would fix the text as instructed. While such was the original intent, since the agent could leverage the multimodal processing of Gemini 3 and watch the video, It became more than just a repair agent and full fledged companion for a viewer.
What we learned
- Multimodality is crucial for context: While audio alone allows for context based subtitles to some extent (Alarm noise or laughter, etc), it is unable to account for gestures and such visual context
- Copilots VS Automated systems: VX assisstant's repair feature works better with human coordination, allowing for more personalized subtitles and accounting for terminology used by fictional works, etc. which lead me to stick with a hybrid copilot architecture
What's next for Welt VX
Dub: I would like to add a feature for voice dubs aswell, using Gemini to translate the speech and generate audio for it.
Chrome extension: Convenient feature for users to have in their browser
Model options: If Welt VX has access to Gemini's more powerful models, the user's may choose to switch between them for lower latency or more capability.
Built With
- gemini-3-flash-preview
- google-genai
- python
- srt
- streamlit
- visual-studio

Log in or sign up for Devpost to join the conversation.