Motivation
Our ability to support sustainable companies is one of the most powerful weapons available to us in the fight against climate change. However, whether you are an investor picking out a portfolio or any individual who simply wants to make a positive impact, we recognise that carrying out in-depth research into companies can be time consuming and difficult.
WeLikeTheSpeech aims to make this process of determining how environmentally conscious a company really is as easy as possible, empowering anyone to make informed decisions. This is done by scoring and ranking companies by analysing speeches, text and websites related to companies using natural language processing techniques.
What it does
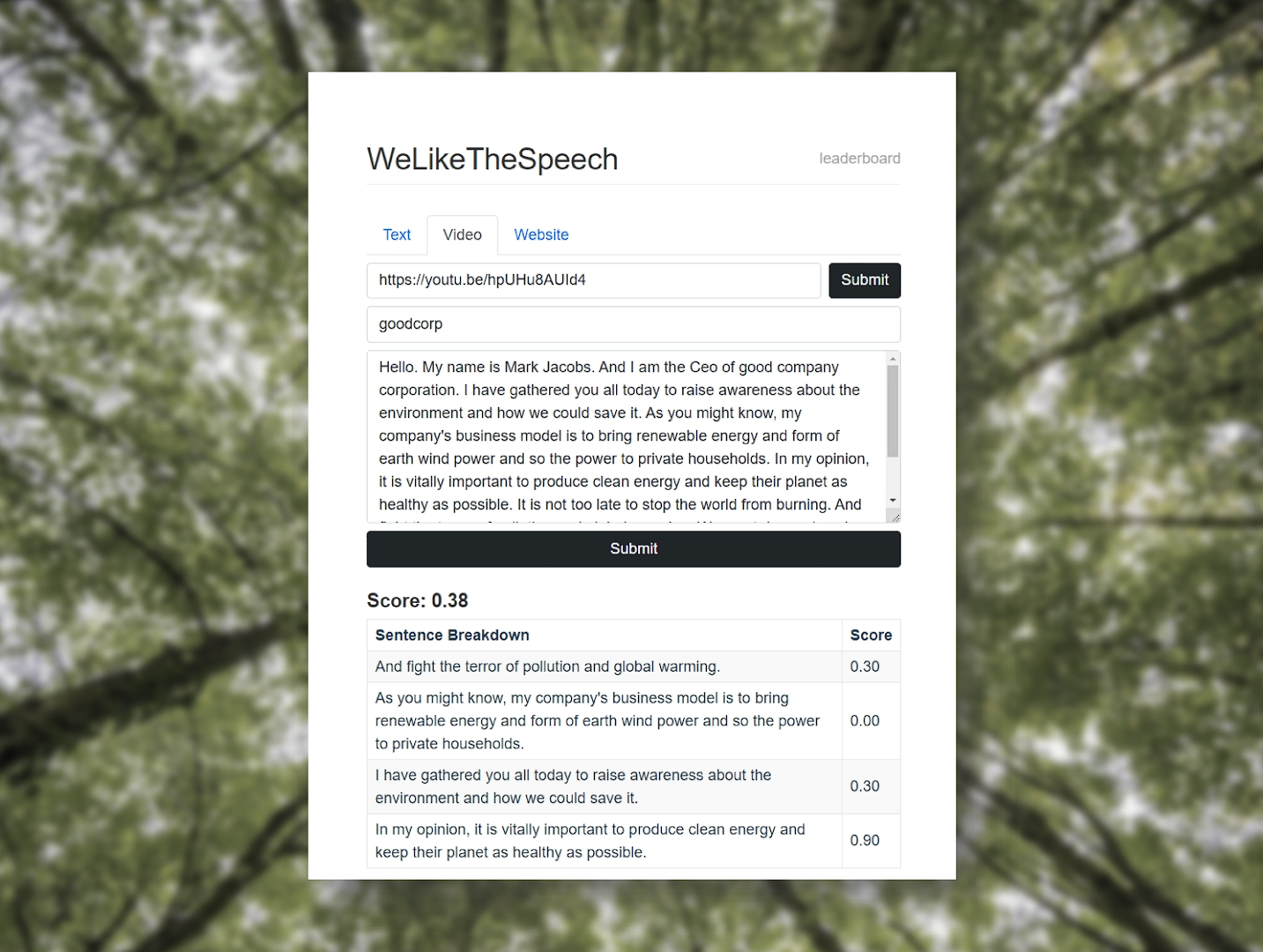
Through our web app (https://welikethespeech.github.io/), users can provide text, a YouTube URL or a website URL related to a company they are interested in. Text from YouTube videos will be automatically transcribed using the Deepgram API and text content from websites will be extracted on the backend.
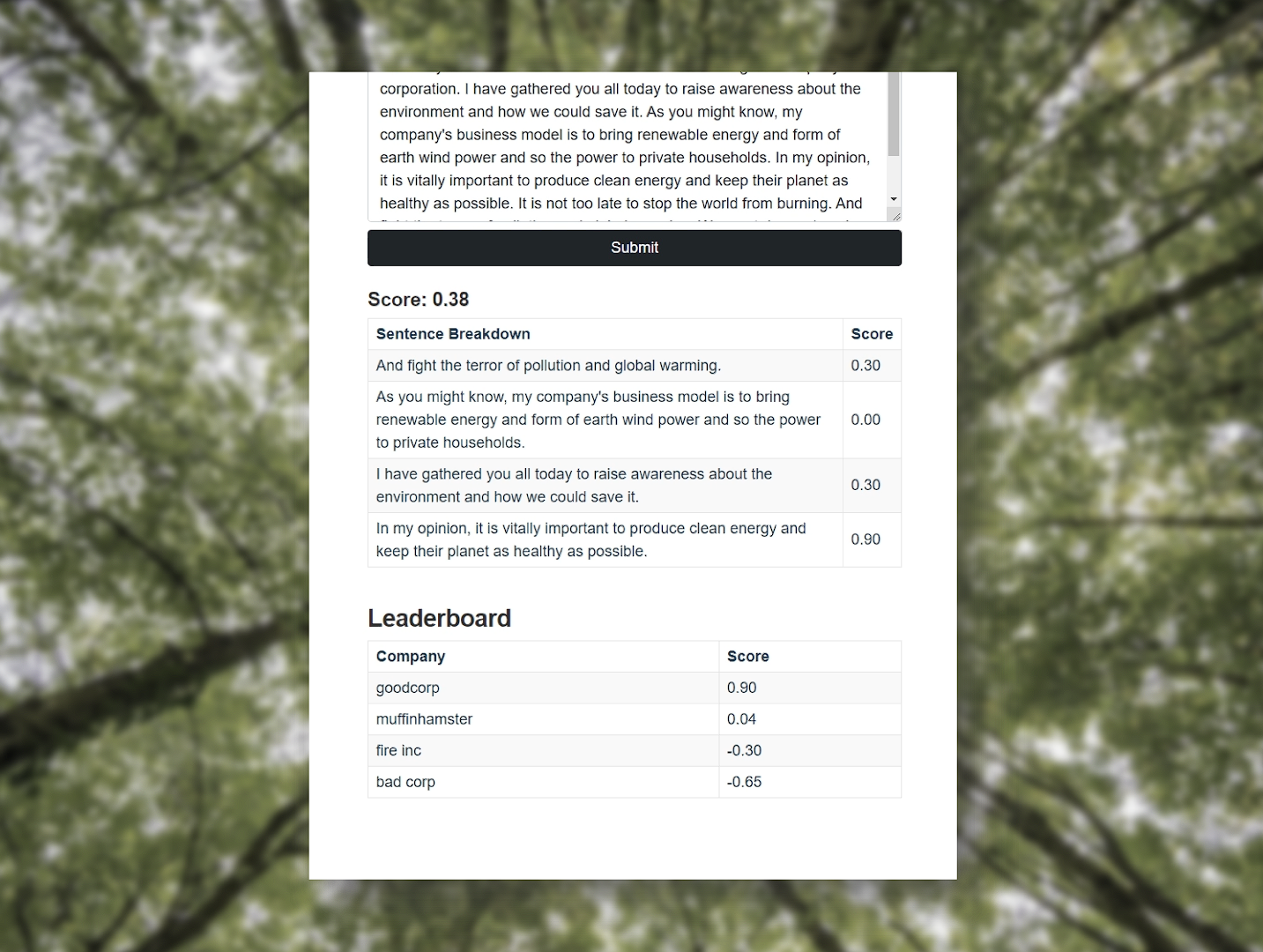
This text is then processed using natural language processing techniques using the Google Cloud Platform, considering a number of key factors such as sentence classification and sentiment analysis.This will result in an ecological score for the requested company based on how environmental consciousness our algorithms have assessed them to be on a scale from -1 to 1. A breakdown of how this value was calculated is also presented to the user.
The computed scores for each company is also collated and aggregated to produce a ranking leaderboard for each company, also publicly accessible on the site, giving a great quick overview of popular companies.
How we built it
We used Vue.js as our front end framework as it was relatively simple but it has many powerful features such as components, bindings, hooks, etc, and can also be very easily compiled to static HTML files for deployment.
Flask was our choice for the backend. Flask was chosen because it is lightweight, easy to use and quick to prototype, which is exactly the backend framework we need due the time restrictions we have.
Our frontend is simply served on github pages as it is fast and requires minimal work. Our backend is deployed on Heroku as it was free and the site contained lots of useful tools for debugging and monitoring the server.
The backend is where the magic happens. In order to transcribe a video from a Youtube link, we must first download the file using Youtube DLP, then convert it to MP3 format and apply the necessary changes, finally send the MP3 to Deepgram and Deepgram will send us all the details about where every word was said.
If instead we want to score text on how long environmentally it is, we will need to call the Natural Language API on Google Cloud Platform with the tokens after the input has been padded and formatted, Google will then return a value associated with the relevant token.
Challenges we ran into
The biggest challenge we have run into was finding a good scoring algorithm, as we want to make sure that the scores are faithful to the text. This was achieved by some trial and error and some number crunching, but in the end we managed to come up with something that we are quite happy with.
Another worry we had early on into the hackathon was running out of credit.. Luckily, Deepgram was kind enough to provide free credits for about 200 hours of computation, and MLH also gave us $50 worth of GCP credits for free.
Accomplishments that we're proud of
What we are most proud of is that we were able to learn new technologies quickly and make a webapp that can be very useful for the general public. Before the event, we had never used the google cloud language API and we had never used VueJS but we felt that these would be most appropriate for our uses with the time and resource constraints we had. We believe that what we have made can be useful as people in general are scrutinizing what they invest and buy in more closely to make sure that the companies are serious about Climate Change. We are also proud of our UI design, we tried to keep it simple and functional and we believe that we have done exactly that.
What we learned
We have learned lots and lots of invaluable experiences from this event such as coordination in a team under pressure and time management and schedule quickly and effectively. They are the key for us being able to finish the prototype in time with good time left for polish.
On the technical side, we have also learnt a lot of useful tools and frameworks and if an opportunity arises where we would need to use any of the technology we have used in this project, we can very easily and effectively apply what we have learnt in this event.
What's next for WeLikeTheSpeech
The most important part of our project is the accuracy of the ecological rating algorithm to ensure that the users can make informed decisions based on reliable information. While our algorithm already provides a way of doing this, there is always room for improvement.
As an extension it would also be possible to utilize GPT-3 instead of the Google Cloud platform to receive even more accurate results.
Furthermore, currently there is a set limit on both the length of the video, as well as the wordcount of the transcript, which can be processed through our project. This also allows for further development potential.
Lastly there is still a vast amount of possible functionality to integrate into WeLikeTheSpeech, such as automatically finding and scraping the information off of a company website or analyzing their twitter feed.




Log in or sign up for Devpost to join the conversation.