-
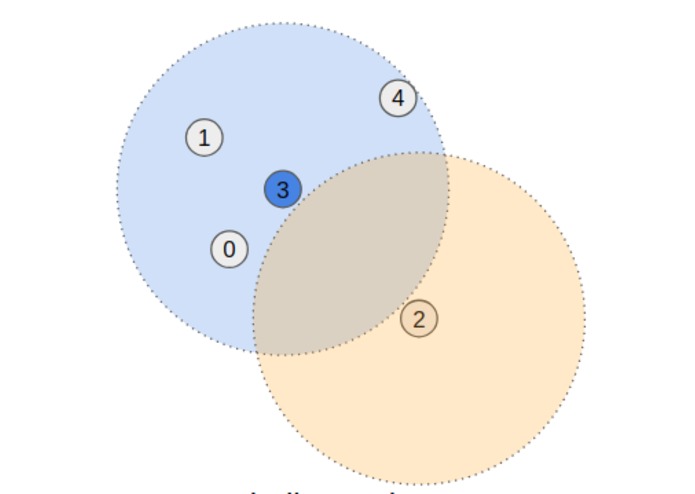
Ball search neighborhoods are implemented using tf.RaggedTensors
-

Weighted averages with continuous weighting function makes operations continuous in space
-
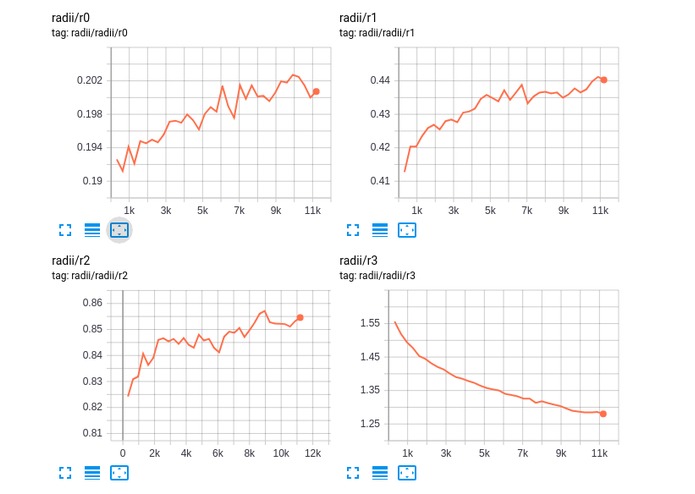
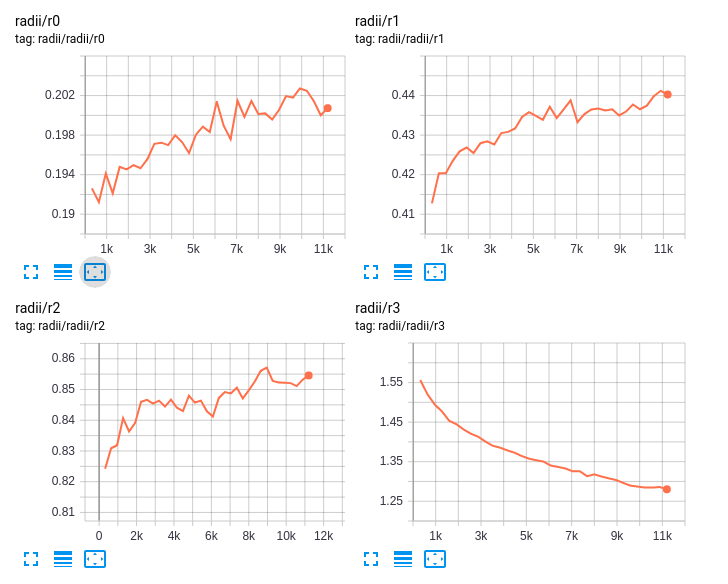
Unlike image CNNs, WeighPoint convolutions can learn an optimal receptive field based on a constant computational budget.
-
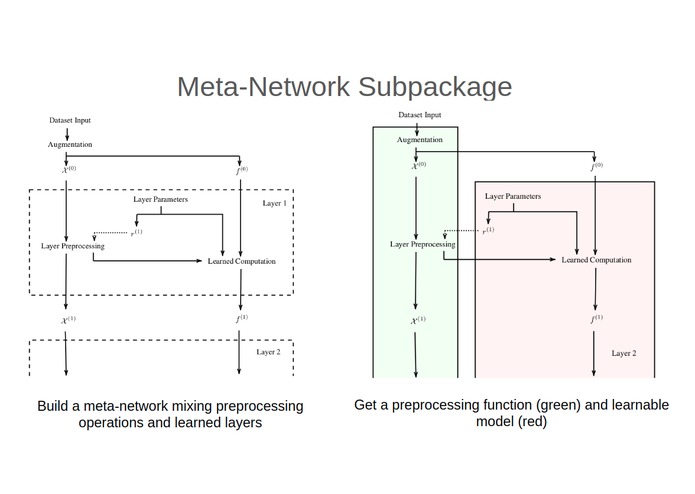
-

Presentation slides available at https://drive.google.com/open?id=1zR1GR2ZBhmv3ITlLMnGwCeXcVkI_WrZii1Mg3hwq3Ho



Inspiration
Point cloud convolutions in deep learning have seen a lot of interest lately (pointnet++, generalized convolutions, PointConv, FlexConv, SpiderCNN). These approaches involve grouping points according to local proximity using data structures like a KDTree. While results on classification and segmentation tasks are promising, most publicly available implementations suffer from a number of factors including:
k-nearest-neighbors search to ensure a fixed number of neighbors, rather than a fixed neighborhood radius;- discontinuity in space:
k-nearest neighbors is discontinous as thekth andk+1th neighbors switch order; and - custom kernel dependency which requires additional setup and maintenance.
What it does
WeighPoint addresses each of these issues.
- Our base convolution takes a "ragged first" approach, taking advantage of tensorflow's new RaggedTensor class to support ball searches of specified radius, rather than a fixed number of neighbors.
- Continuouity is addressed by replacing summation with a weighted average, where the weighting function continuously decreases to zero at the ball-search radius
- The
tf.data.Datasetpipeline is used extensively to ensure neighborhood searches are conducted via scipy's KDTree implementation on CPUs during preprocessing.
The resulting architecture requires no custom kernels to be built. Basic models can be trained in a number of hours (2-8) on a single desktop GPU (timings based on GTX-1070/ GTX-1080-TI).
How I built it
While this project was developed using 1.12/1.13, it was always intended to be easily ported to 2.0. As such, the tf.keras framework was used throughout. It also makes extensive use of the tf.data.Dataset API and is configurable via gin-config.
Challenges I ran into
- I found the requirement in 1.x for keras lambda layers to wrap basic operations to be quite infuriating - especially when combined with
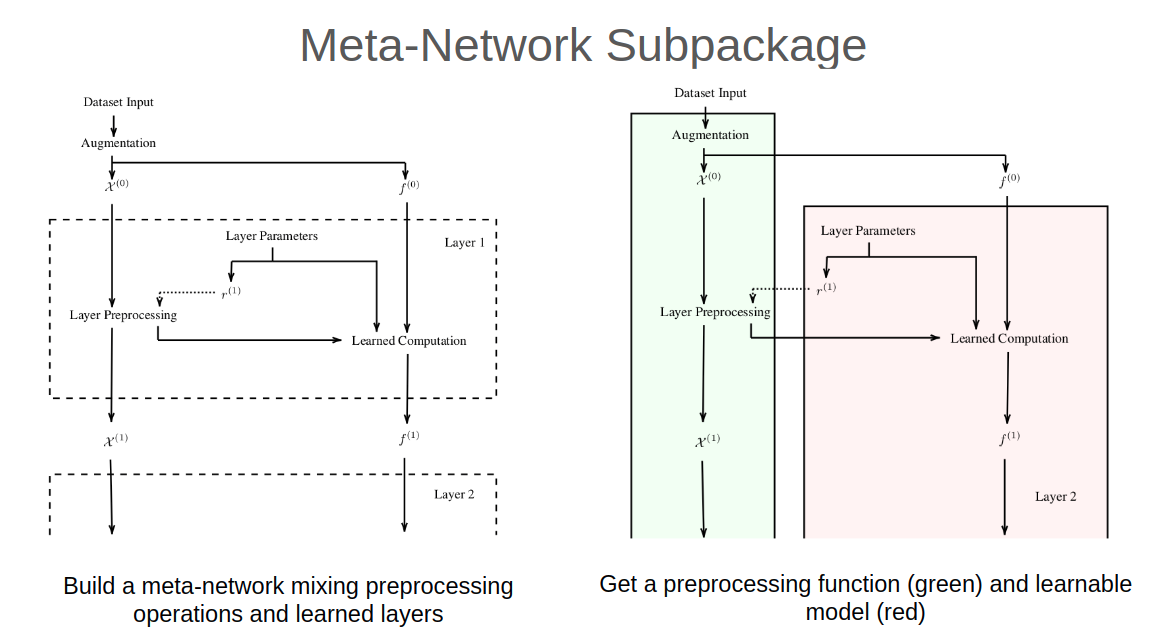
tf.RaggedTensors, as they cannot be the input or output of lambda layers. I am pleasantly surprised this requirement is dropped in 2.0 (though the code still has them to support earlier versions). tf.RaggedTensors, while amazing, were a bit rough around the edges at the start of the project. Subtle bugs, unimplemented gradients and unpredictable memory usage during gradient computation - while completely understandable as with any new release - led to several re-writes of the core convolution implementation.- Each convolution in a WeighPoint CNN has it's own neighborhood that must be calculated. These calculations can be done during preprocessing, but this is per-layer preprocessing, and thus network dependent. Writing preprocessing and learning networks separately and coordinating them proved unviable for all but the most basic proof-of-concept.
- As far as I am aware, there is no simple way to batch ragged tensors together using the
tf.data.DatasetAPI.padded_batchgives you the tools, but early experiments showed naively padding them stripping based ontf.RaggedTensor.from_tensorthrottled performance unacceptably. - Making the one project compatible with 1.x and 2.0 is difficult. The idea that keras code will work in either 1.x or 2.0 - while a nice idea - simply isn't the case for non-trivial projects. For example, trainable models generated raise errors on serialization in 2.0 but not 1.13. It's also not clear how to replicate reinitializable iterator behaviour in 2.0 without resorting to
tf.compat.
Accomplishments that I'm proud of
I'm most proud of the way in which network-dependent preprocessing is implemented. While it isn't super easy to debug and precludes the use of eager mode during network construction, it allows all network code - per-layer per-example preprocessing and batched learned components - to be written in one place without sacrificing any control, and while also automating the ragged batching process.
A side effect of the ragged first implementation is the output is differentiable not only with respect to point positions, but also the neighborhood radius itself. This means - unlike image convolutions - the receptive field of each layer itself can be learned.
What I learned
keras in 2.0 is looking very promising. Coming from estimators I was disappointed by the lack of comparable out-of-the-box features in keras in 1.13 (e.g. tensorboard logging of custom metrics is, in my opinion, highly unintuitive and unlike all other tensorboard logging, and restarting training from a previous checkpoint is distinctly non-trivial), but I'm optimistic looking forward.
What's next for WeighPoint
Classification with basic models are close - but still worse - than state-of-the-art (87-89% vs SOTA 92%). There is a vast amount of configurations possible however, and a I am hopeful a non-exhaustive architecture search will yield better results.
A segmentation dataset and model has also been written, though a known bug that needs to be resolved before results beyond random guessing can be expected. Point cloud generation/reconstruction from images should also be possible with the operations.
Built With
- python
- tensorflow
- tensorflow-2


Log in or sign up for Devpost to join the conversation.