-
-

WeEat Icon
-
introduction
-
llm
-
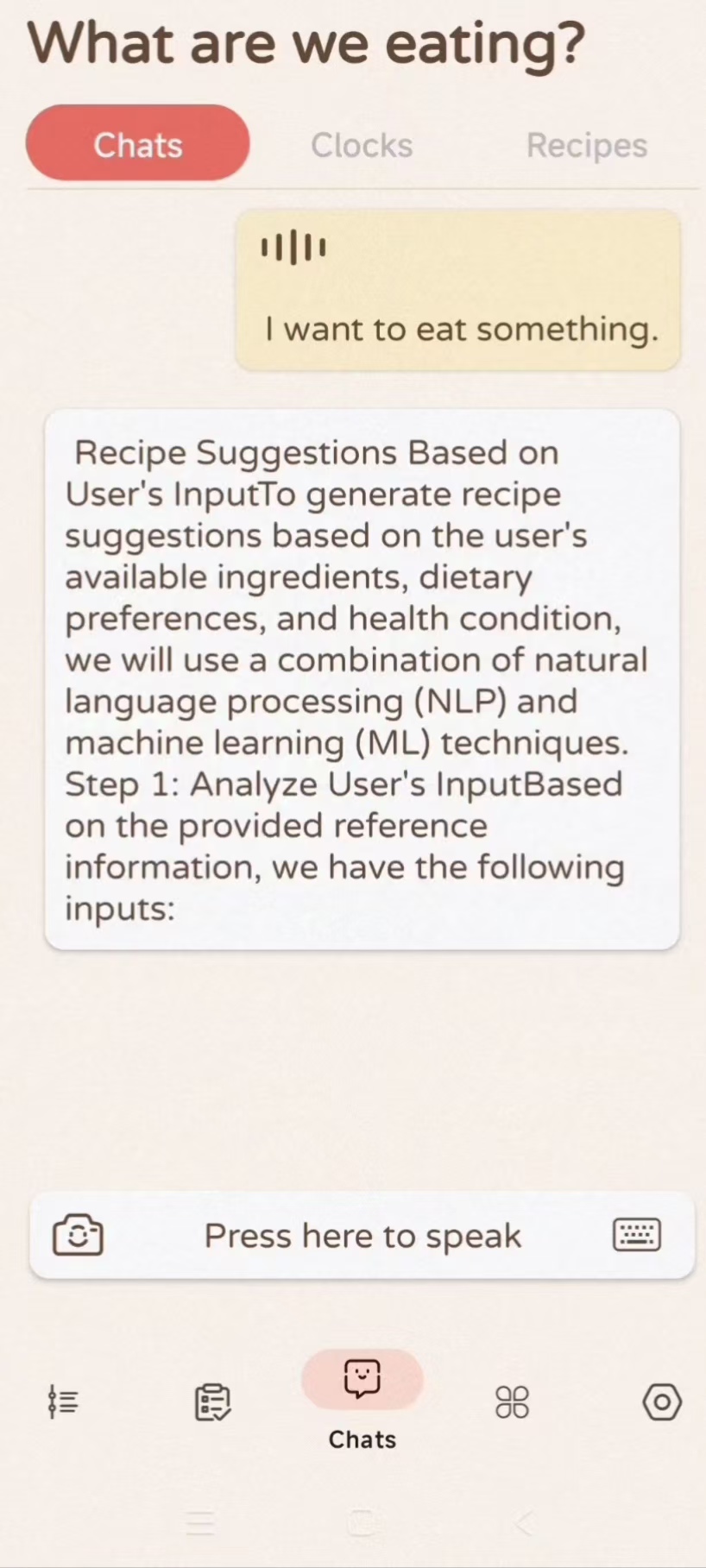
llm generated recipes
-
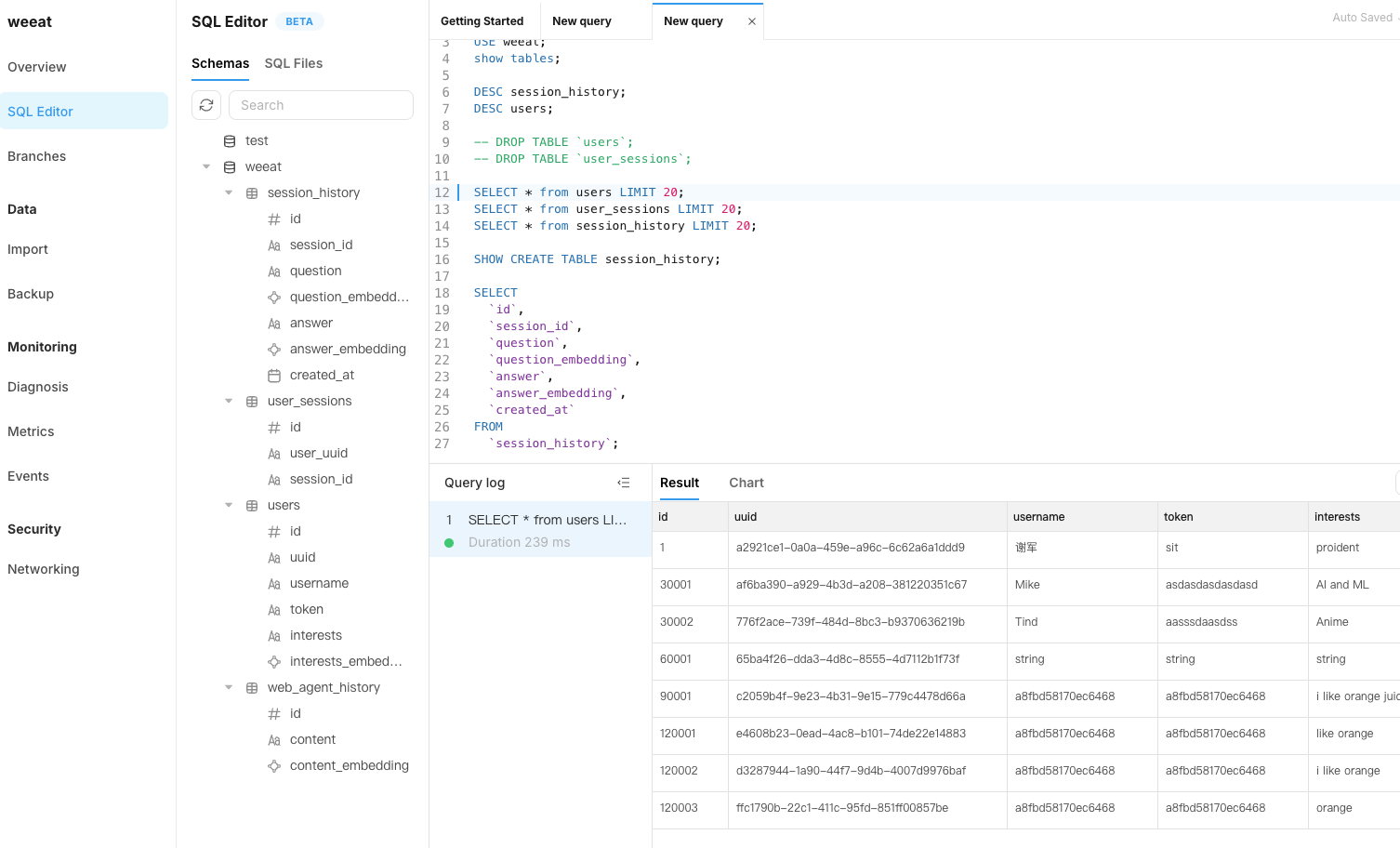
tidb dashboard
-
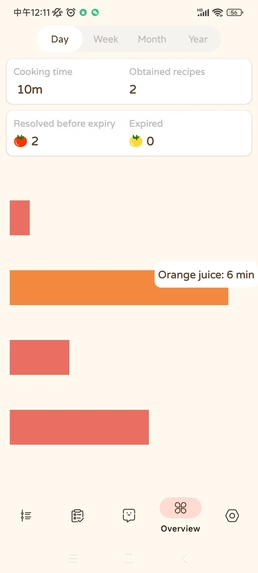
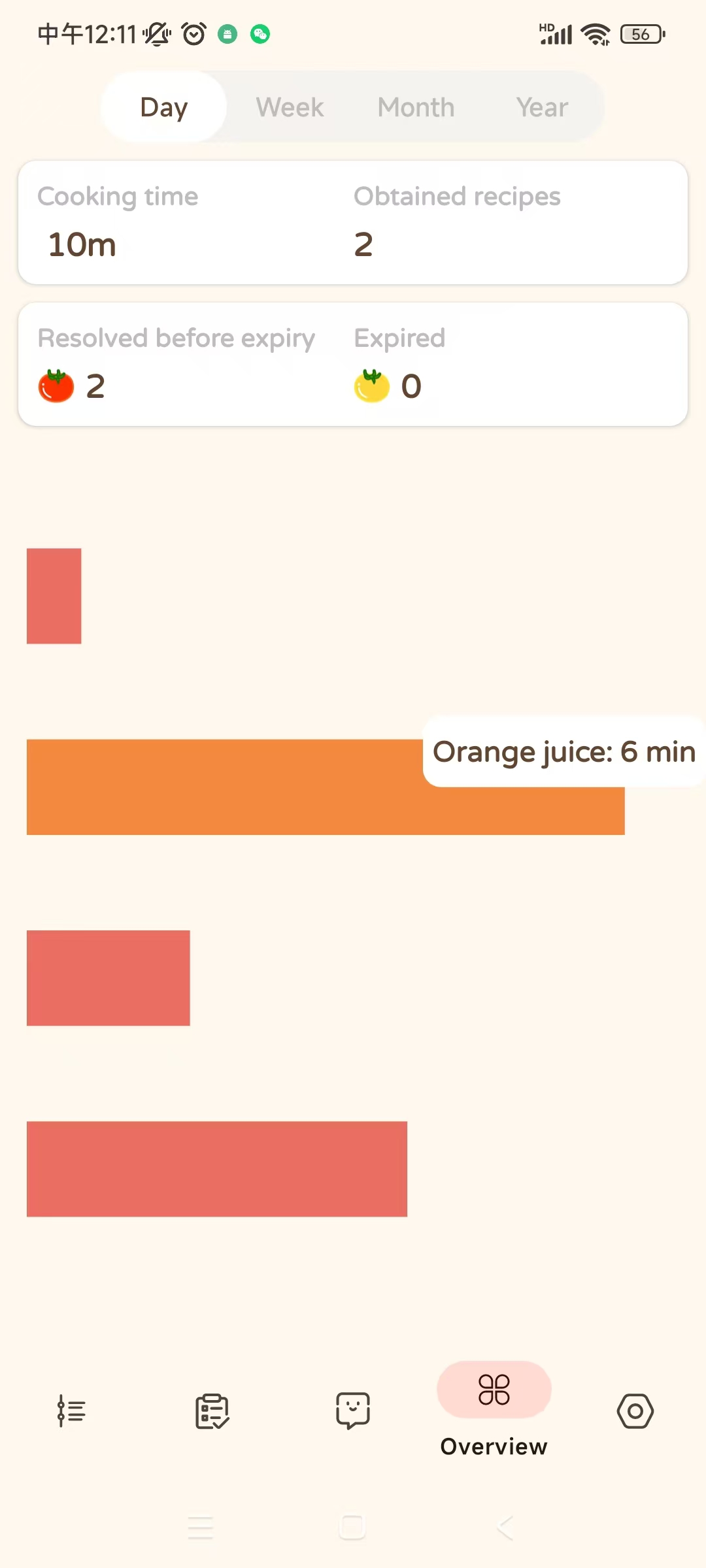
overview
-
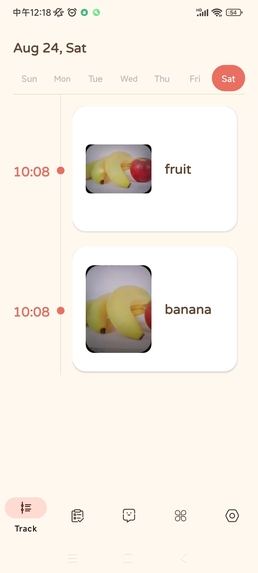
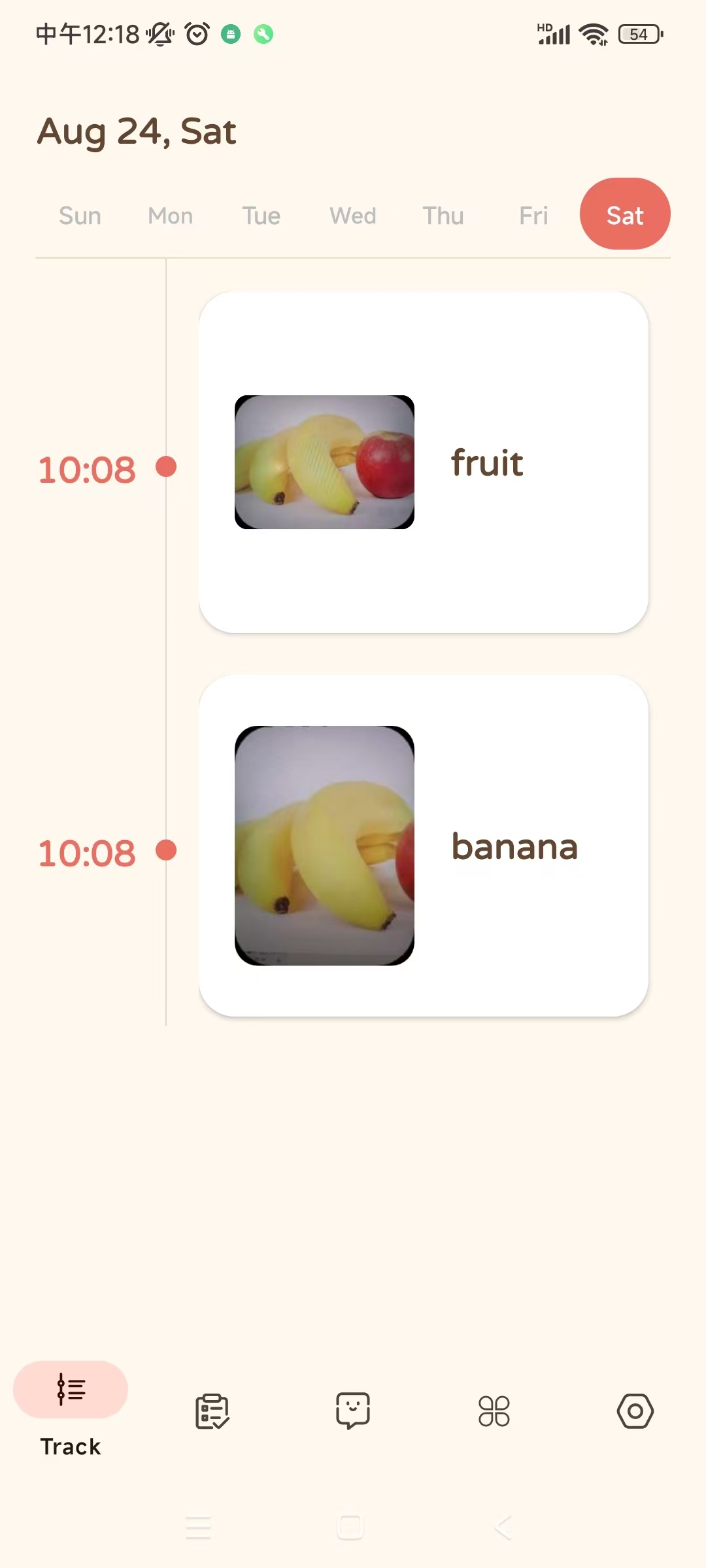
timeline
-
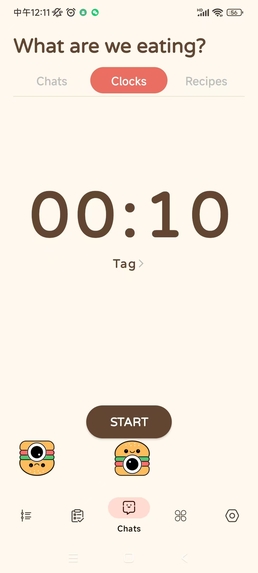
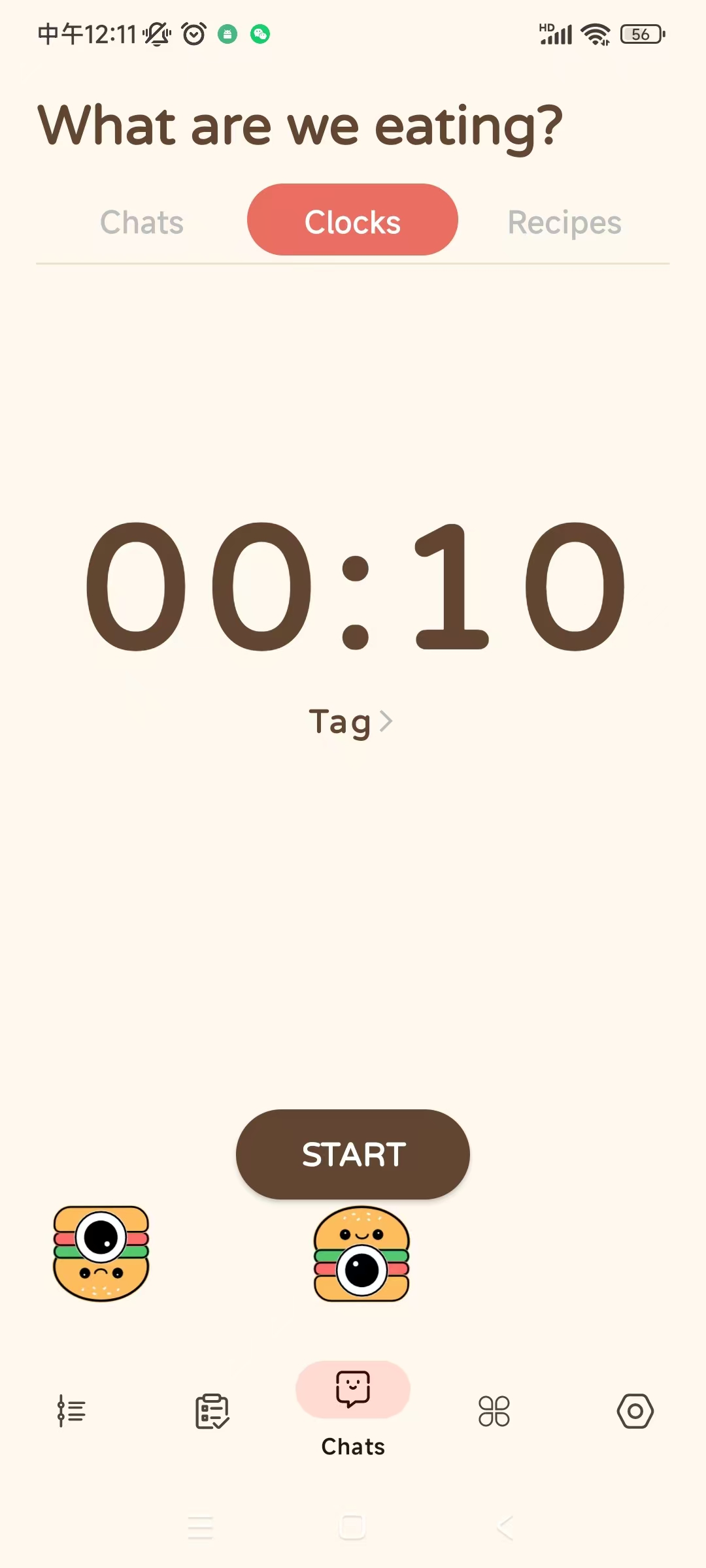
count down
-
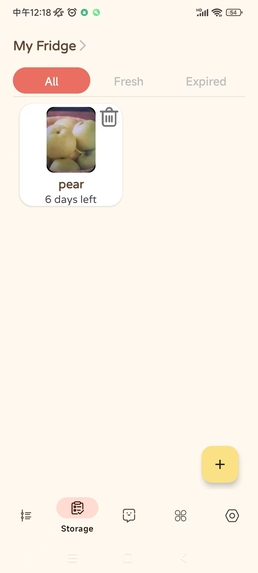
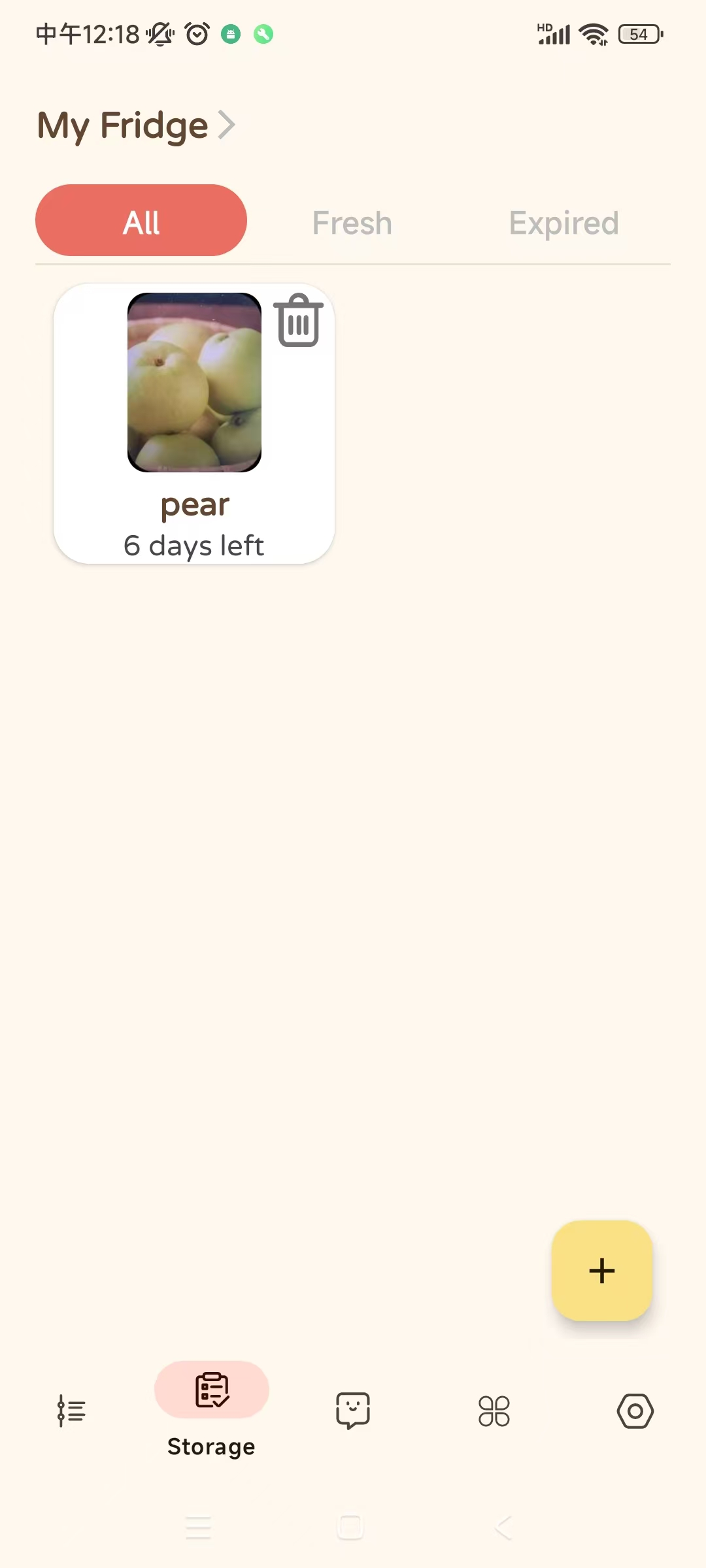
local storage
-
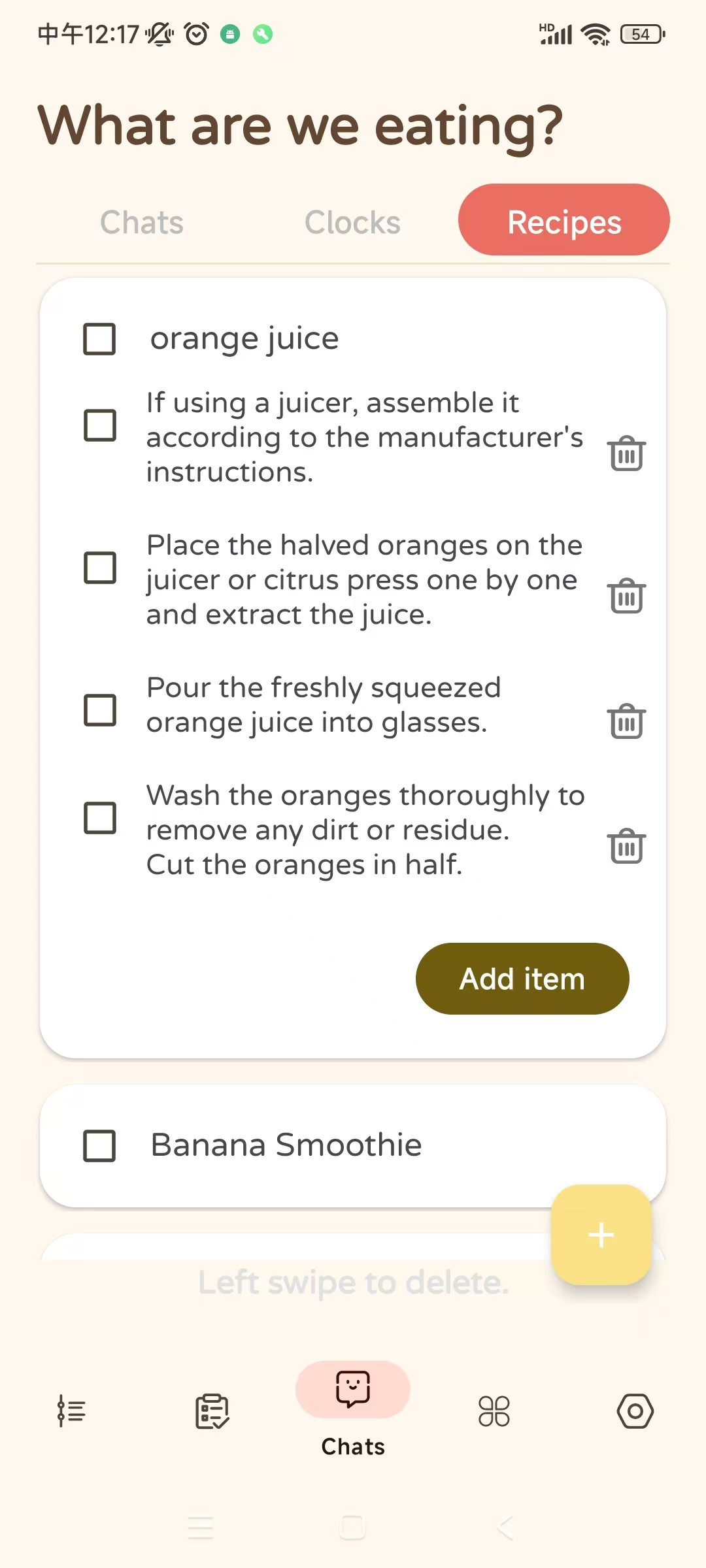
add foods
-
pick time
-
settings
-
modify item

Access our demo
Link: https://weeat-ai.vercel.app/ Github: https://github.com/Renaissance0412/WeEat
Inspiration
The inspiration for WeEat stems from the global challenge of maintaining a healthy diet and managing body weight. Research shows that over 80% of people struggle with these issues, as well as with improving their cooking skills. We wanted to create a solution that leverages the latest advancements in AI, particularly in Large Language Models (LLMs) and vector search technology, to offer a personalized, cost-effective, and private health assistant. Our goal was to empower individuals to take control of their dietary habits and overall health through intelligent, data-driven recommendations.
What it does
WeEat is an AI-powered health and nutrition assistant that provides personalized dietary advice, meal planning, and health tracking. It integrates multiple technologies, including speech-to-text conversion, image recognition for food items, and a robust knowledge base enhanced by TiDB vector search and a web search engine. The platform allows users to interact via voice, text, or images, offering tailored suggestions based on their dietary history and preferences. Additionally, WeEat helps users log their meals, track their nutritional intake, and provides structured recipes to support their health goals.
How we built it
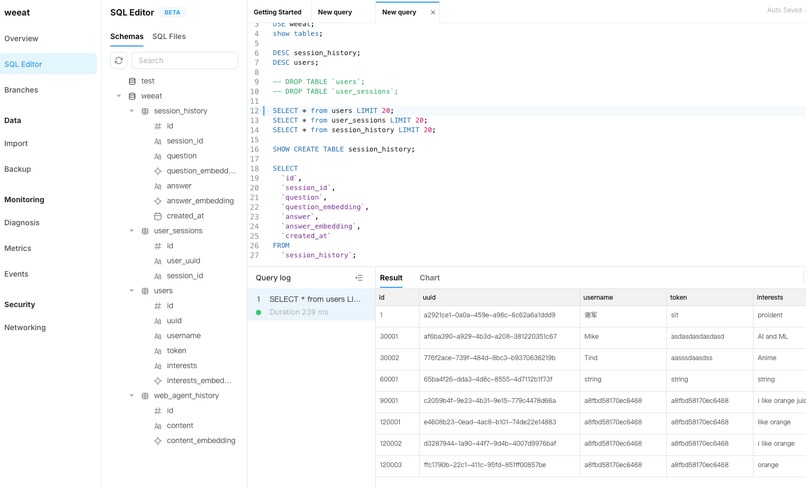
WeEat was built using a modular design, centered around the Vllm Llama3-8B model, which processes natural language inputs and generates personalized outputs. We integrated TiDB’s vector search capabilities to store and retrieve 768-dimensional embeddings of users’ dietary data, ensuring accurate and relevant recommendations. The architecture comprises five key modules: API, LLM, RAG (Retrieval-Augmented Generation), ASR (Automatic Speech Recognition), and Image Recognition. These modules work together through microservices, providing a seamless and scalable user experience. Additionally, we implemented a Mem-driven mechanism to optimize the retrieval of conversation history, enhancing the contextual accuracy of our responses.
Mem-driven Mechanism
A crucial aspect of WeEat is our Mem-driven mechanism, which is designed to optimize the efficiency of information retrieval and contextual understanding during user interactions.
Here’s how it works: when a user begins a conversation with WeEat, we retain relevant dialogue history in memory. This allows us to selectively retrieve past interactions that may be pertinent to the current conversation, ensuring that the assistant can provide contextually aware and accurate responses.
For example, if a user asks for a healthy recipe today and then refers back to it in a future conversation, WeEat can recall the previous discussion and provide a coherent response, maintaining continuity in the user experience.
At the end of each session, the conversation history is flushed to TiDB. This ensures that all user data is securely stored and accessible for future queries, without overloading the system’s memory during active sessions.
Additionally, we leverage TiDB’s caching capabilities to store the most frequently accessed historical conversations. This caching mechanism not only speeds up response times but also enhances the assistant’s ability to understand and respond to complex user queries by preloading relevant historical data.
Multi-Modal Support
One of the standout features of WeEat is its support for multi-modal inputs. We understand that users might interact with the system in various ways—through speech, images, or text—and we’ve designed our backend to handle these inputs seamlessly.
Our private speech recognition technology converts spoken language into text, allowing users to give voice commands and receive immediate feedback. This is particularly useful for hands-free interactions, such as when cooking.
In addition to speech, we’ve integrated sophisticated image recognition capabilities. Users can upload pictures of their meals or ingredients, and WeEat can accurately identify the food items. This visual data is crucial for providing precise dietary recommendations. For instance, if a user uploads an image of a salad, WeEat can analyze the contents and suggest complementary ingredients or provide nutritional information.
These multi-modal capabilities are more than just convenience features—they’re central to our mission of providing highly personalized and contextually relevant advice. By capturing data from multiple sources, we can build a more comprehensive understanding of each user’s dietary habits, leading to better, more targeted recommendations.
Information Retrieval Capabilities
WeEat also excels in information retrieval. Our Web Agent can search credible online sources based on user queries and integrate this information into our knowledge base. This ensures that the assistant’s responses are not only accurate but also up-to-date and comprehensive. The retrieved information is stored in TiDB, which further enhances our knowledge base and allows for effective search and retrieval.
Challenges we ran into
One of the major challenges we faced was ensuring the seamless integration of multi-modal inputs—specifically, aligning the speech recognition and image recognition capabilities with our AI model’s processing. Managing the memory and caching system effectively, to balance performance with resource usage, was also a significant hurdle. We had to the TiDB vector search to handle large-scale data efficiently while ensuring the personalized recommendations remained accurate and contextually relevant.
Accomplishments that we're proud of
We are particularly proud of successfully integrating advanced technologies to create a truly intelligent and responsive health assistant. The development of the Mem-driven mechanism was a key achievement, allowing us to maintain a high level of context-awareness in user interactions. Additionally, the multi-modal support we implemented—enabling users to interact through voice, text, and images—significantly enhances the user experience and sets WeEat apart from other health assistants.
What we learned
Throughout the development of WeEat, we learned the importance of a modular and flexible design when working with complex AI systems. We also gained valuable insights into optimizing the performance of large-scale data retrieval systems, particularly with TiDB’s vector search. Furthermore, we recognized the critical role of user experience in AI applications, driving us to focus on making the interface intuitive and responsive to various input types.
What's next for WeEat
- Looking ahead, we plan to further refine WeEat by enhancing its recommendation algorithms and expanding its knowledge base through continuous learning and web data integration.
- We aim to improve the system’s scalability to accommodate a growing user base while maintaining high performance.
- Additionally, we plan to explore new features, such as real-time health monitoring and integration with wearable devices, to provide even more comprehensive health and nutrition support for our users.
- Hope for more integration and advanced features with TiDB Vector Search.



Log in or sign up for Devpost to join the conversation.