Inspiration
The internet is dominated by just handful a languages, and social networks keep us in monolingual silos—billions of people are effectively disincentivized to use their languages online—including some in our group. The inspiration for weCAPTCHA is the dream of being able to surf the web in any language.
What it does
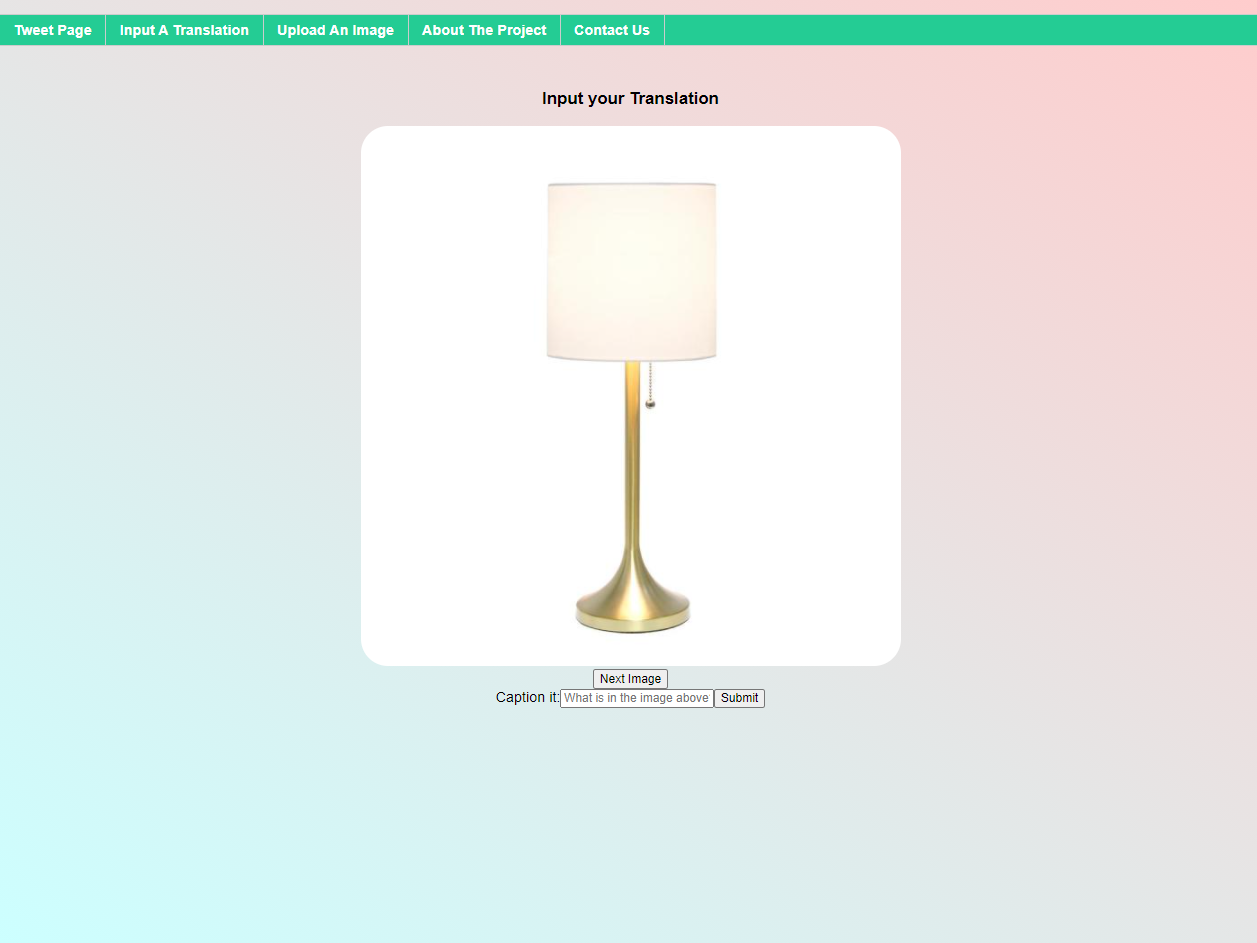
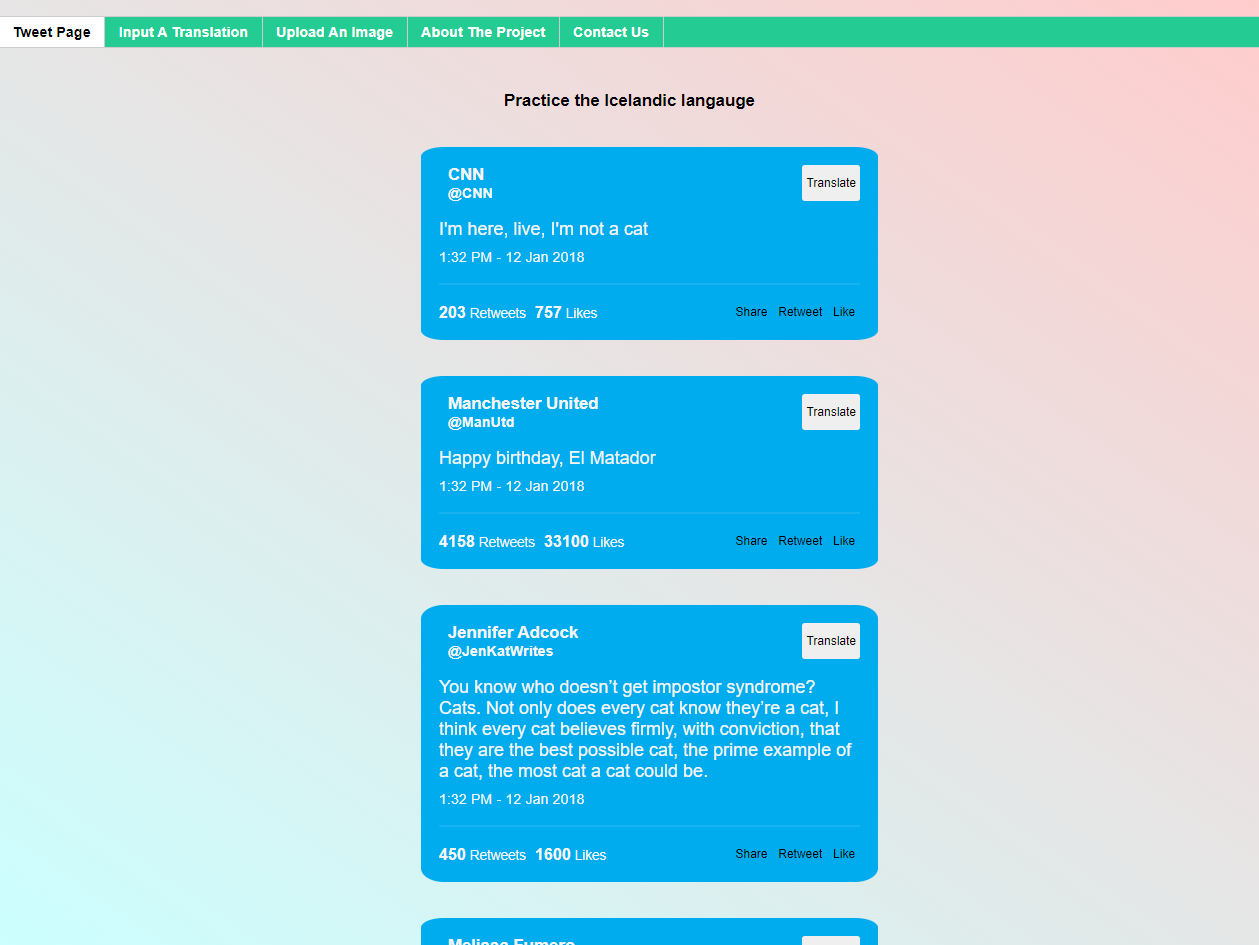
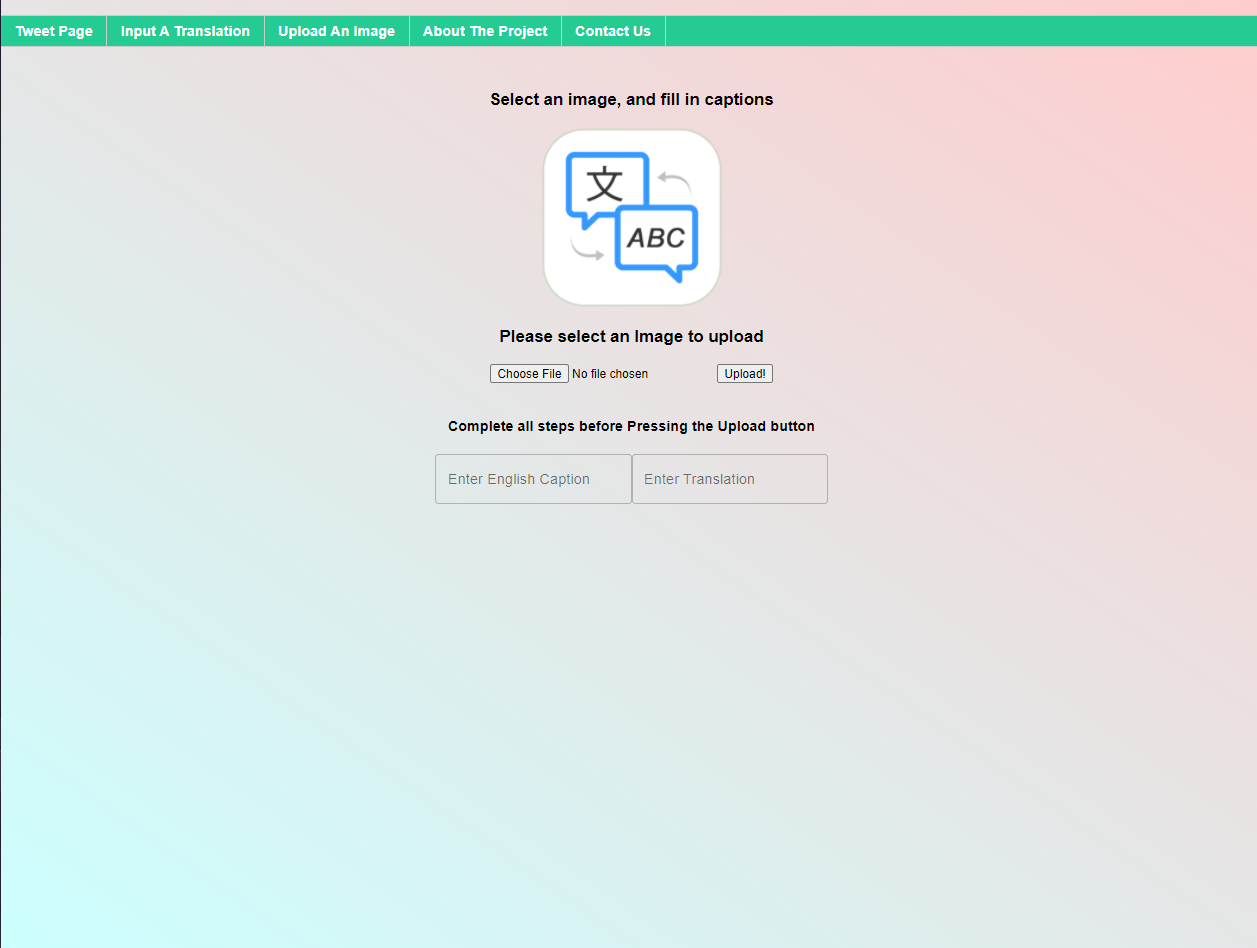
In an effort to create a machine translation algorithm that can learn to translate any language, weCAPTCHA displays images and asks the user to provide a caption in their target language. It also presents a Twitter feed where users can see our algorithm attempt to translate into their language–and help us improve the algorithm when our it is wrong.
How we built it
We built a React app and used Flask for the backend. We also designed a recurrent neural network that would map a user's caption for a given image with the pre-trained word vectors that FastText associates with the labels that Google's Cloud Vision API returns for that image.
Challenges we ran into
The backend and neural network were particularly challenging given that none of us had much experience with that.
Accomplishments that we're proud of
We're proud of all that we learned! We went quite a bit outside of our comfort zone by taking on this challenge. We pushed ourselves hard on this project and we are proud of what we were able to make.
What we learned
We learn a ton! None of us had worked in React before so we all learned that, as a team we also learned a lot about linguistics and applications for machine translation. We also learned about neural networks and how the state of the art machine translation works.
What's next for weCAPTCHA
When we started this project we didn't realize just how much we had taken on; the next steps include connecting the backend so that we can actually process users' input, fixing the Twitter feed interface so that it actually pulls tweets, and creating a user authentication flow that we can keep track of users and their translations.
Future features we are considering—in addition to what we originally planned on making—include an Amazon Mechanical Turk -like interface for researchers to host data collection tasks, and a Patreon-like interface where users can crowdfund projects—ideally language arts related projects.

Log in or sign up for Devpost to join the conversation.