-
stage1a
-
stage1b
-

stage1c
Inspiration
Tested Majestic's API and wondered how tough it would be to create my own Web Crawler. Decided to set myself a challenge to do it without using any APIs or Cloud Services.
What it does
Scrapes the Google results page for the search term 'Spartan'
How I built it
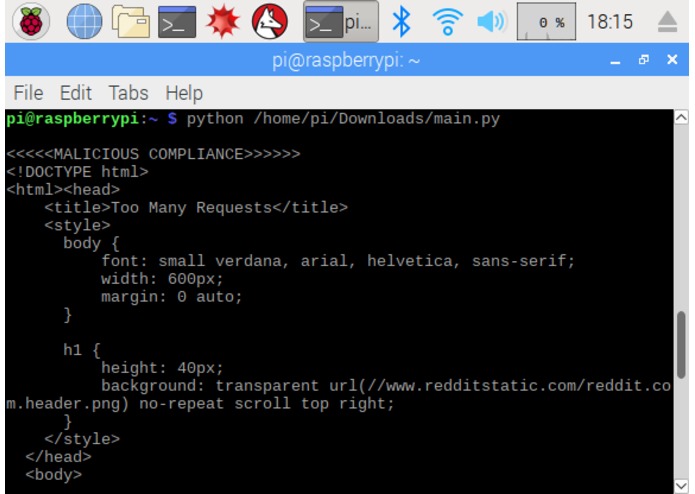
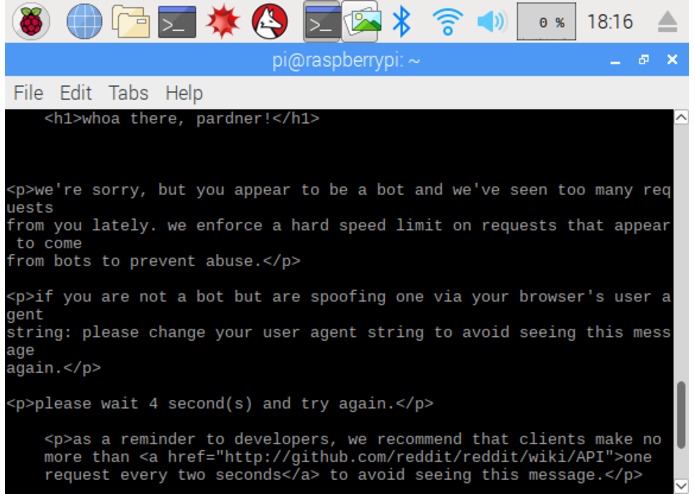
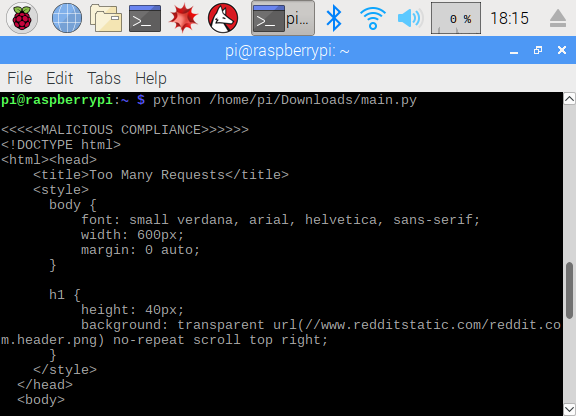
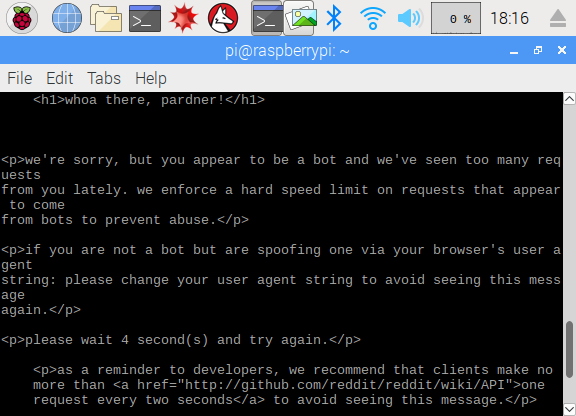
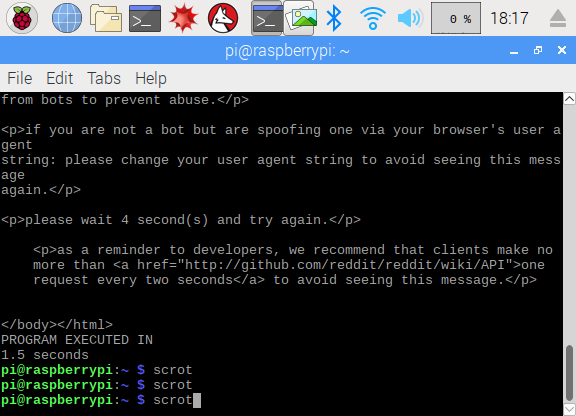
STAGE 1 - .py module running on the Raspberry Pi searching Reddit PROBLEM: As signal is constantly originating from the same location, Reddit blocked the bot from receiving input fairly quickly.
STAGE 2 - Attempt to use Selenium and Docker to create more complex crawler (FAIL)
"Improved performance, NOT Efficiency
PROBLEM: most specialist Selenium code found online is written in Java
STAGE 3 - DuckDuck Go API to fetch and feed search content into Scrapy and then Algolia. Had to rewrite Python API as it was outdated. In the end, entire API needs to be rewritten (Future Project) before it can be useful
(Compatibility issues between urllib2 and urllib3) Then the fact urllib no longer exists due to security issues Did Not work. Had to rewrite a lot of DuckDuckGo's API. Lot of work. No yield.
STAGE 4 - CommonCrawl and Beautiful Soup to scrape Google Search Results for the Word 'Spartan'. Hosted on a Digital Ocean server. FAILED DUE TO MODULE Compatibility Issues AND LACK OF KNOWLEDGE.
What I learned
API's are not always the best solution for a program
What's next for WebScraper_Journey
DuckDuck Go API completion Exploring Algolia further Fixing issues with scraping on CommonCrawl

Log in or sign up for Devpost to join the conversation.