-
-
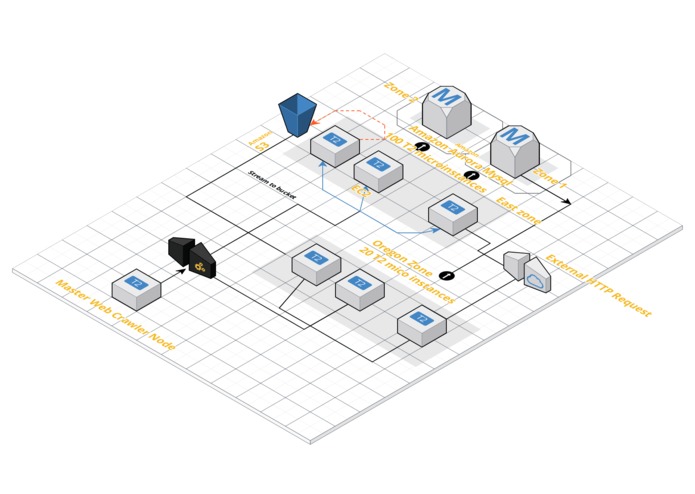
Architecture
-
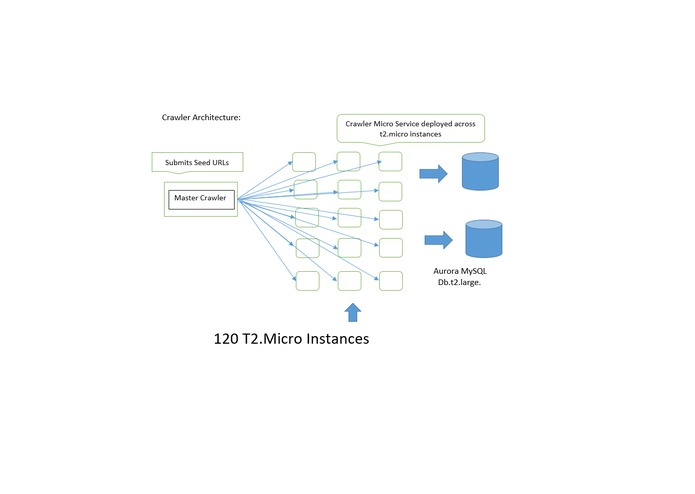
Detailed AWS Architecture
-
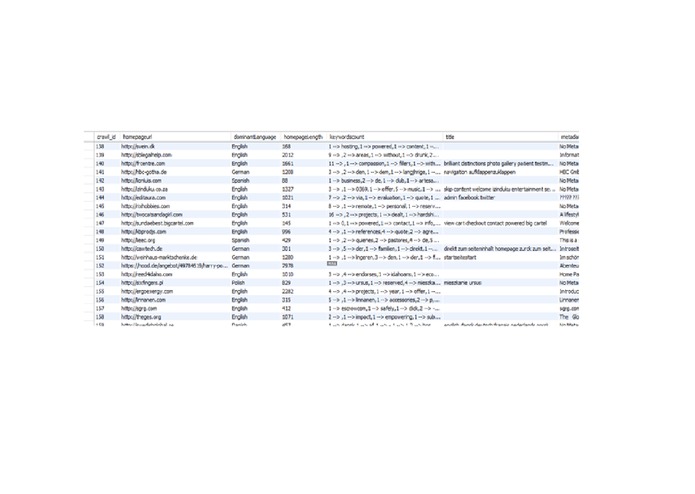
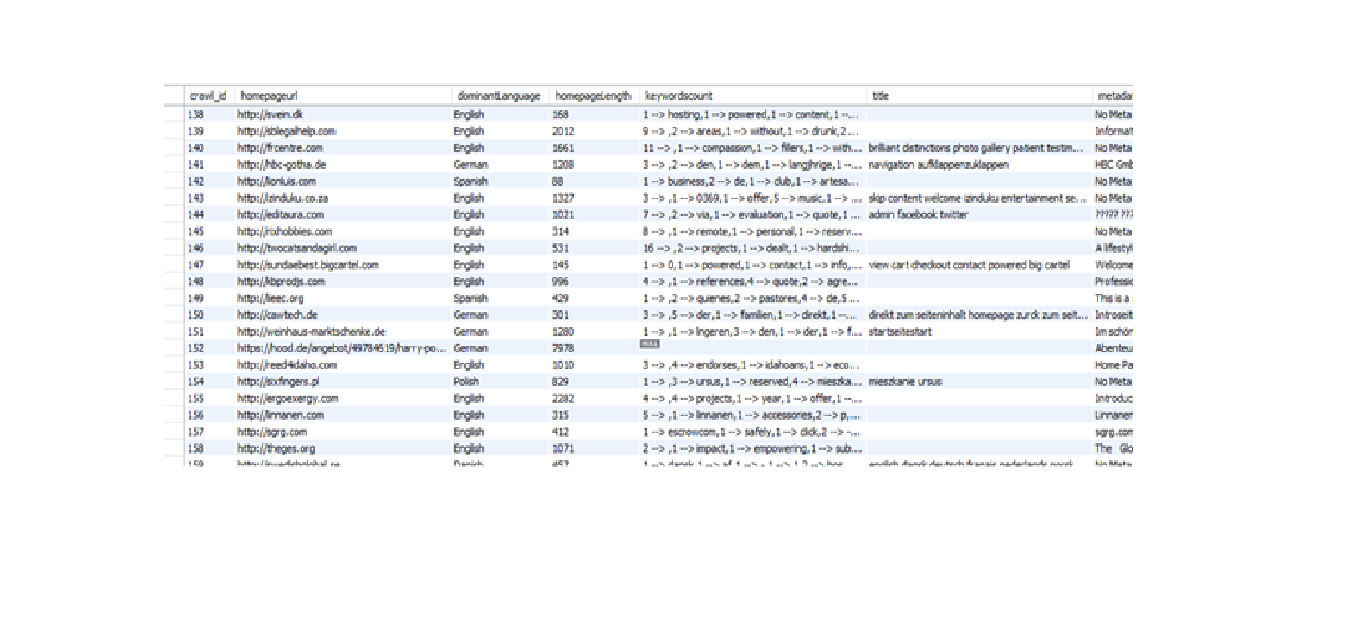
Crawl data
-

crawl data
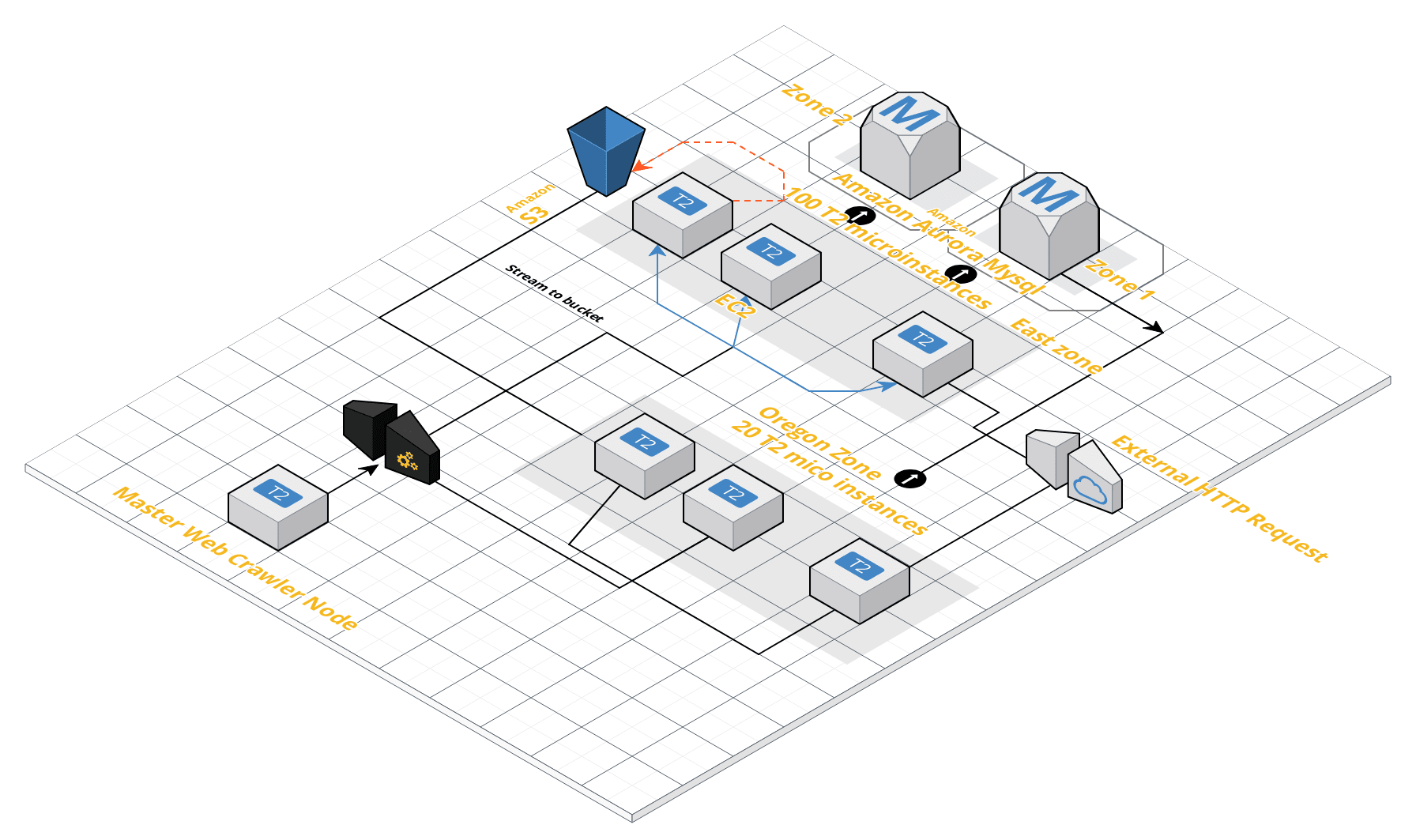
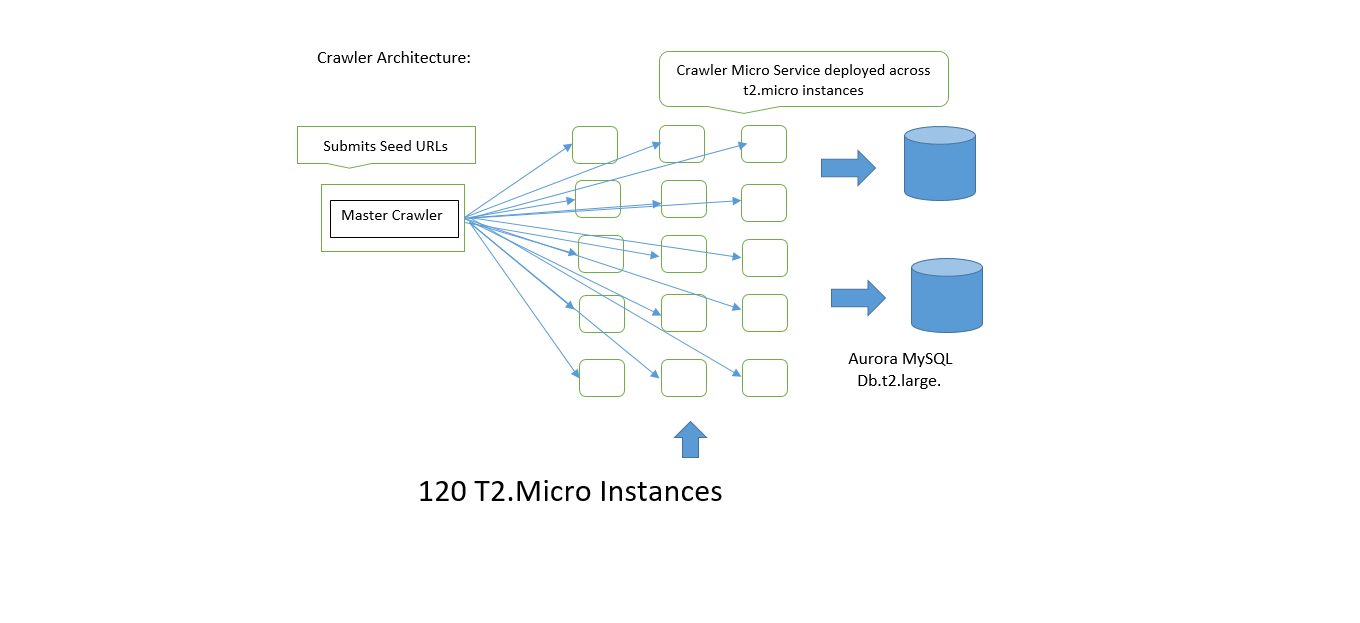

Inspiration - Large Scale Crawls take 1.5 million dollars, I want to rethink the way of how crawls can be optimized to run on low memory and hence save lot of money on ec2 instances and enable high parallel writes to mysql database.
What it does
==> Language Detection – English , German , Japanese, … etc. upto 54 languages of home page. ==> Email Address , Phone number and Address Extraction (city, Zipcode and State) . ==> Stop words removal, Text Normalization and outgoing links extraction. ==> Outgoing Links – Programmed for 8 links outgoing inner links from the home page to the neighbouring pages (1 hops). ==> Keyword Analysis of the Body text of a URL HTML page – Key => Words , Value => Counts (frequency of words in a html document). ==> Duplicate Finder – returns true of it finds duplicates of text across the 9 URLS of a ROOT webpage. MD5 Hash Algorithm is used for cross checking the duplicates. ==> Link Discover – Automatically Discover Links that has contact us or about us page and extracts the phone number and email address. ==> User Agent Rotator – Rotates the User Agent – with different User Agent Strings. ==> Facebook open graph tag extractor – title , description ,url etc.
How I built it
==> Avoiding objects – Specially Class Objects – Objects are heavy weight occupying 48 bytes. ==> Use Global Instance Static Classes – that is common and can be shared across instances. ==> Byte[] and Str[] instead of Strings and Collections. ==> Parallel arrays where – a[key] and a[value] takes less space and more memory efficient than Collections map and List. ==> Map Collections used with final static – with fixed size . Eg: Map container = new ==> ==> HashMap(1), defines Map of size 1. ==> Creates Arrays of fixed size only on demand , array of byte takes less bytes than String. ==> StringBuilder() instead of String has drastically reduced the memory space. ==> Use of short instead of int , volatile instead of final . ==> Security – Classes are final as they cannot be extended or override or overloaded. ==> AtomicBoolean , AtomicInteger – Helps maintain dedicated variable in a multi threaded environment. ==> Singleton Pattern for Thread safe class access. ==> Static classes and methods stored in Permanent Generation or metaspace as it reduces the GC Pauses. ==> Use of in maven to prevent unused classes to be loaded in JVM Runtime . Please refer to AmazonAurora/pom.xml for the exclusions. ==> -XX:MaxGCPauseMillis=80 (in milliseconds) - This JVM parameter will make your JVM more responsive and highly available for crawling as it reduces the time taken for GC Pauses. ==> Crash Proof – Fault Tolerance – Persisting and saving the serialized file to /home/ec2-user for reloading the file incase the JVM abruptly shutsdown.
Challenges I ran into
==> CRAWLER BREAKS IN MIDDLE DUE TO UNHANDLED EXCEPTIONS ==> OUT OF MEMORY ERROR OCCURRED FREQUENTLY DUE TO CLASS LEVEL OBJECTS . ==> URL REDIRECTS – 301 , 302 HTTP STATUS CODES LEAD TO CRAWL JOBS RUNNING INFINITELY. ==> USED VM PROFILE FOR PROFILING APPLICATION – LOT OF MEMORY SPENT ON STRING MANIPULATION , STRING CONCATENATION AND STRING APPENDING – HENCE REPLACED WITH STRINGBUILDER. ==> START,TEST,STOP – MEMORY PROFILING – LEARNT HOW TO OPTIMIZE JVM TO RUN ON LOW MEMORY AND HOW TO TUNE YOUNG GENERATION. ==> I COULD HAVE MADE MY LIFE EASY USING DOCKER BUT REFRAINED FROM IT DUE TO LOW MEMORY ENVIRONMENT.
Accomplishments that I'm proud of
==> Crawler has been tested to run for more than 4 hours with no Out of Memory Exceptions ==> Successfully Crawled 20,000 Seed URLs with no crawl breaks in between. ==> Gracefully shutsdown with no memory leak. ==> Saved lots of dollars without spinning up large instances.
What I learned
==> Don't start off with highly complex code - Start with very minimal design and add complexity as it goes further. ==> It looks very simple at first , but becomes complex as we approach the problem hands - on (coding) - try to research the web and get more inputs before jumping right off with coding. ==> Design is really important than developing code for the application. ==> Costs can be reduced in many ways - Use resources optimally and dont hard code your secret tokens in github code - as my aws account got compromised recently.
What's next for Web Crawling using Swarm of 120 robots with low memory
==> Developing SEO based website optimized Crawling - Integration with Natural Processing Libraries for understanding texts , articles, news etc. ==> Ecommerce based price comparison Crawler and location data extraction crawler.
Built With
- amazonec2
- auroramysql
- datascraper
- duplicatedetection
- emailextraction
- facebookopengraphextractor
- hashing
- java8
- keywordseoanalyzer
- language-detection
- linkdiscovery
- maven
- md5
- meta-tag-extractor
- microservices
- natural-language-processing
- phonenumberextraction
- serialization
- springboot
- webcrawler






Log in or sign up for Devpost to join the conversation.