WeatherClassification
Decision Tree ML algorithm for Weather Classification Algorithm in Austin, TX
Computer-based models have become incredibly powerful to the field of meteorology for weather forecasting tools, both in the short and long terms. In simple terms, forecasting decisions are made based on collections of past and present quantitative data. This process has existed for centuries, yet continues to evolve in parallel with our scientific boundaries.
Here, we can apply decision tree algorithms quite effectively: we can develop models that map the given atmospheric data to each of their weather outcomes. Therefore, when we obtain future instances of data, we can make decisions on what outcomes they map to. What's neat about decision trees, aside from their intuitive shape, is their versatility: they can be applied to all shapes of data and often require little amounts of pre-processing of the features. In a very particular use case, given atmospheric data in an area corresponding to instances of tornadoes vs strong winds vs no wind, we can make determinations on whether a tornado is occurring/forming from data collected in real-time. The models' determinations will have a huge influence on disaster preparedness and other forms of preparation given a specific wind event.
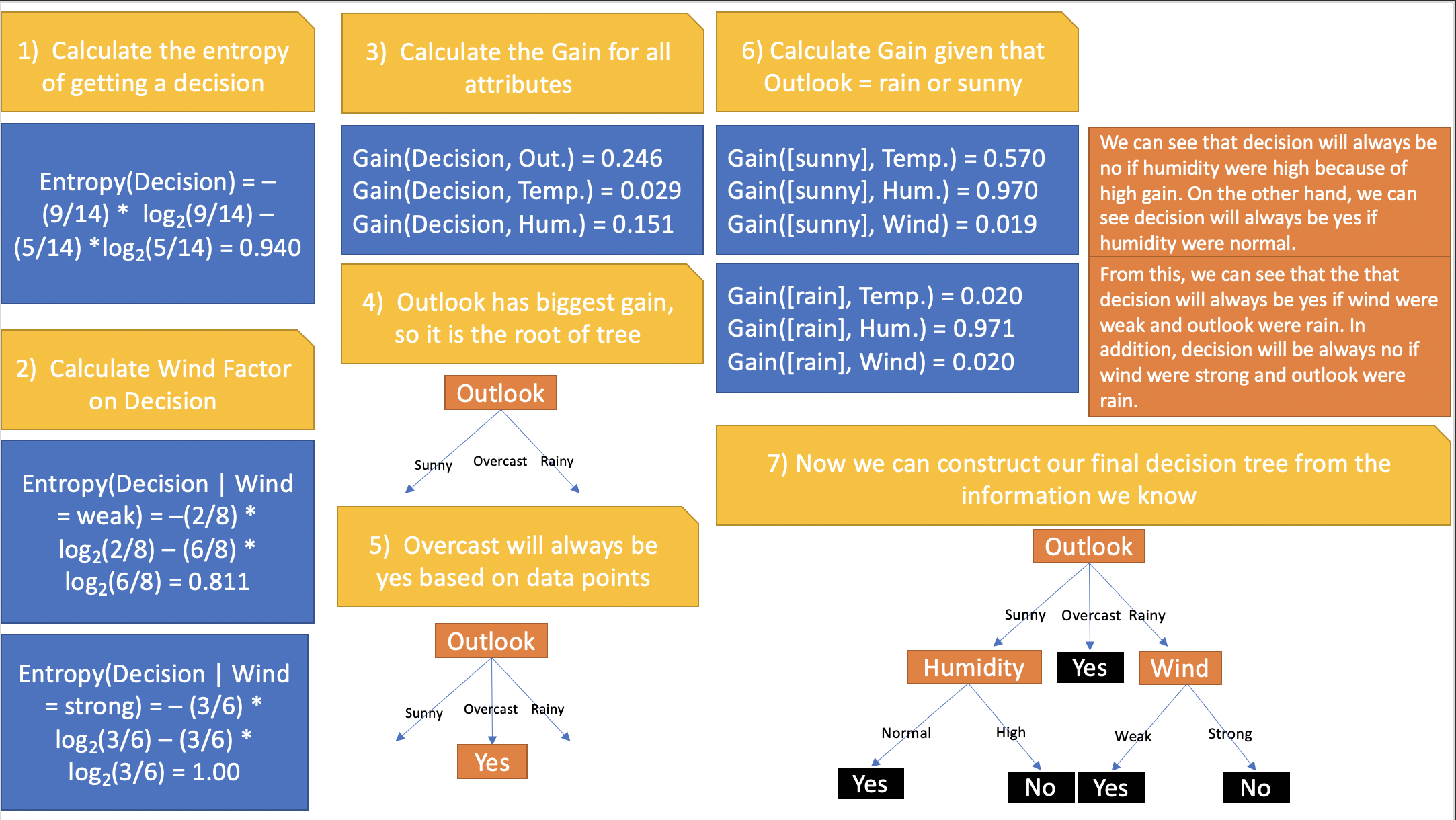
At its core, the ML Decision Tree algorithm relies on entropy, and by extension, the concept of information gain.
Entropy is essentially defined as the measure of disorder (or purity)". For a concrete example, we can look at the case of flipping a coin. Say that our random variable X models the act of flipping a coin with Heads or Tails as our outcome. In the case where we have Heads and Tails with 50% chance, our entropy is at it's highest since we have no way to measure what the likely outcome is, as there is no majority. On the other end, if we are closer to either 0% or 100% for either Heads or Tails, we have a far lower Entropy.
Now that we understand Entropy, we can better comprehend Information Gain. Information Gain allows us to measure the reduction of disorder when we have additional information about a particular class (features/independent variables). We essentially subtract the entropy of $X$ given that attribute $a$ exists from the total entropy of X, seeing how much our entropy has reduced from the additional attribute a, i.e. how much disorder has been reduced. The greater this reduction, the more information gained about X from the attribute.
Now we can apply these concepts to our Decision Tree model. In the training process, our data is continuously split by the attribute with the greatest information gain (or biggest reduction in entropy). Classifying future data points therefore relies on traversing this tree because of the "information gained" by matching the appropriate attribute value. This process continues until a final "decision" (classification) is reached. Thus, we have mapped quantitative and qualitative data to a specific outcome by essentially "making decisions" at each step of the tree, narrowing the pool of classifications until a particular leaf node is reached.

Log in or sign up for Devpost to join the conversation.