Inspiration
WearWise emerged from both our personal frustrations with fast fashion and the complementary backgrounds of our team: most of us study AI for Biomedicine and Healthcare, while one member brings expertise in AI for Sustainable Development. We kept noticing how one-off occasion outfits often end up forgotten at the back of the wardrobe or worse, in landfill. Renting is a promising alternative, but in practice it’s fragmented, time-consuming, and often more confusing than buying something new. For us, this was personal: seeing friends and family struggle to make sustainable choices made us want a solution that actually works. Drawing on our AI expertise, we designed WearWise as a transparent, intelligent rental assistant that lowers the friction of choosing eco-friendly fashion. It’s understandable, auditable, and aligned with responsible AI principles - helping people make sustainable choices confidently and effortlessly.
What it does
WearWise is a transparent, glass-box outfit recommender that works across multiple UK fashion rental platforms. Users fill out a short, human-centred questionnaire about their event, location, date, budget, style “vibes,” favourite or avoided colours, and any fit concerns. Our agent turns this into a search brief, queries several rental providers, and returns real items with prices, delivery windows, and descriptions. We then score and rank these items with a simple, interpretable model that balances budget, delivery speed, and how well each piece matches the brief. On the front end, users see curated rental looks with a visible match percentage, friendly tags like “Budget-friendly” or “Arrives quickly,” and a clearly marked top recommendation.
Crucially, every recommendation comes with an explanation of why it was chosen and why other options ranked lower, so users understand the trade-offs instead of blindly trusting a black box. In short, WearWise makes the sustainable “rent rather than buy” choice easy, transparent, and reliable.
How we built it
We created a lightweight, end-to-end system combining a clean web interface, a LangGraph agent pipeline, and a hybrid rule-based plus LLM ranking layer. The front end uses plain HTML, CSS, and JavaScript, designed for clarity rather than flash: a calm questionnaire that feels more like talking to a stylist than filling in a form, and a results view that doubles as an explainability surface, with match bars, tags, and expandable debug details.
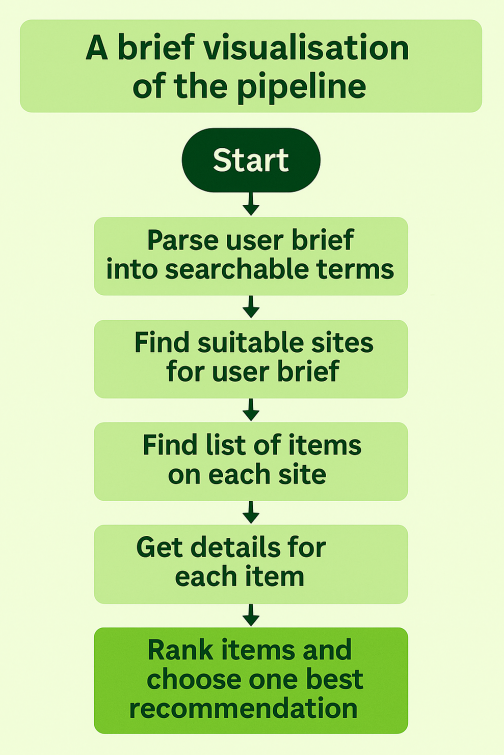
On the back end, a Flask app exposes a /api/recommend endpoint and orchestrates the agent. The LangGraph workflow is structured into explicit nodes: parsing user input into a search term, selecting rental sites, finding product URLs via modular scrapers, fetching product details, and scoring and ranking items using a transparent scoring function.
We layer an LLM via an AWS Bedrock proxy on top to break ties among top candidates and generate short, friendly explanations in UK English. Output is constrained to a strict JSON schema for safety and predictability. All graph invocations are wrapped with LangSmith’s @traceable functionality, producing an inspectable trace for every request.
The result is a small but genuinely agentic system that integrates tools, observability, and human-centred explanations - making sustainable outfit recommendations transparent and trustworthy.
Challenges we ran into
Working with live rental providers felt more like interacting with live clinical systems than clean benchmark datasets. Sites would rate-limit, time out, or silently change their structure. At one point, a single provider’s API timing out caused the entire agent run to fail - clearly unacceptable for an “agent that lasts.” We addressed this by hardening our graph nodes with defensive try/except handling and sensible fallbacks, so if one site is unavailable, the agent degrades gracefully and continues with other sources.
Another challenge was deciding how much of the internal scoring to show users. As researchers, we love raw numbers, but most users prefer clear labels like “good match” or “within budget.” We iterated on the UI to translate numeric scores into intuitive match levels and tags, keeping detailed numbers confined to a collapsed debug section for judges and developers.
Finally, integrating the LLM as a stylist while maintaining transparency required careful prompt design and parsing. We enforce that the model returns a minimal JSON object and never exposes internal scores, avoiding drift into opaque or uncontrolled behaviour. ct and never mention internal scores, to avoid drifting into opaque, uncontrolled behaviour.
Accomplishments that we’re proud of
For our first hackathon, we are especially proud of building a multi-provider, resilient rental agent without compromising on transparency. WearWise does more than call a single API and hide the rest: it coordinates several scrapers, handles real-world network failures, and still delivers useful suggestions. Every recommended item comes with a clear explanation of why it fits the user’s brief and where it may fall short compared to alternatives. The top pick is visually highlighted and accompanied by a “why not the others?” section, showing if a dress was rejected because it was too expensive, too slow to arrive, or less aligned with the requested style.
We also implemented robust observability through LangSmith: each end-to-end agent run is traceable, with intermediate states and node outputs available for inspection. Coming from AI for Sustainable Development and AI for Biomedicine and Healthcare, we are particularly pleased that we treated this fashion use case with the same rigor we would apply to a decision-support tool in a more critical domain - with simple rules, documented behaviour, and clear routes to auditing.
What we learned
Building WearWise reinforced how closely sustainability, user experience, and transparency are connected. It’s not enough to tell people that renting is “greener”; if the journey is slow, confusing, or untrustworthy, they will quietly default back to fast fashion.
We learned that even relatively simple, rule-based scoring can be powerful when clearly explained and surfaced in the interface. We also noticed that agent workflows closely resemble decision-support pipelines in healthcare: you gather evidence (rental items), apply explicit heuristics, and optionally use a model to provide a narrative summary - all while keeping intermediate steps visible.
On the tooling side, we gained a deeper appreciation for observability. LangSmith traces for each run let us see exactly where things broke when a provider timed out and verify that our error-handling and fallback mechanisms worked as intended. This kind of traceability is essential for building agents that users can truly trust, not just agents that occasionally produce impressive outputs.
What’s next for WearWise
If we had more time beyond the hackathon, we would expand WearWise in two main directions: richer sustainability signals and stronger evaluation. On the sustainability side, we would enrich items with fabric composition, brand-level sustainability ratings, and approximate shipping impacts, then expose this information through additional tags and an optional “lower-impact first” sorting mode; always being transparent about what we know and what we don’t.
On the transparency side, we would formalise our scoring scheme as a small “model card” for WearWise, documenting which factors are considered, how they are weighted, and their limitations, keeping it aligned with the LangSmith traces we already generate.
Longer term, we see WearWise as a testbed. The same glass-box patterns we use here - node-level traces, clear scoring, human-friendly explanations, and robust error handling - could be applied back into our core domains of sustainable development and healthcare. Our aim is not just to build an AI stylist, but to show what a genuinely transparent, sustainability-aware agent can look like in practice.
Built With
- langgraph
- python

Log in or sign up for Devpost to join the conversation.